"Cost optimization is the disciplined refusal to spend money on capacity you do not need yet."
Werner Vogels, Amazon CTO, AWS re:Invent keynote, 2022
Sections 46.1 and 46.2 told you what hardware you need and how it integrates with the rest of the enterprise. This section is the procurement layer that sits underneath: where do you actually rent those GPUs, what does the price-per-flop landscape look like across the specialist providers and the hyperscalers, and how do you stitch together spot, reserved, and on-demand capacity into a portfolio that does not blow up the budget. The right answer in 2026 is almost never "all on-demand at one provider"; the right answer is a tiered procurement strategy that matches workload shape to contract shape. For LLM teams, the workload-to-contract mapping is sharper than in classical ML: fault-tolerant batch jobs (embedding refresh, evaluation suites, nightly fine-tuning) belong on spot, real-time inference SLAs belong on reserved or on-demand, and getting this wrong is the single largest line item in an LLM company's monthly burn.
Prerequisites
This section assumes familiarity with compute sizing from Section 57.1 and with enterprise integration patterns from Section 57.2. Familiarity with model-rotation strategy from Section 44.6 helps when reasoning about multi-provider tradeoffs.
The 2024-2025 GPU shortage taught one durable lesson: capacity at the right price is a procurement problem first and an engineering problem second. The team that locked in Lambda Labs reservations in early 2024 paid roughly half what their competitors paid on-demand for the same H100 hours that summer. The team that built a workload that could run on spot capacity from RunPod or vast.ai cut their training bill by another 60-70%. This section walks through the procurement landscape, the spot-instance economics that make it interesting, and the reserved-capacity playbook that protects against the next scarcity cycle.
57.3.1 The four procurement tiers
Spot GPU prices on the major hyperscalers can drop by 70% during a public holiday and spike by 200% when a new frontier model launches and every researcher wants to run benchmarks. Teams that run their training jobs on spot capacity learn to read the AI news cycle the way commodity traders read weather reports.
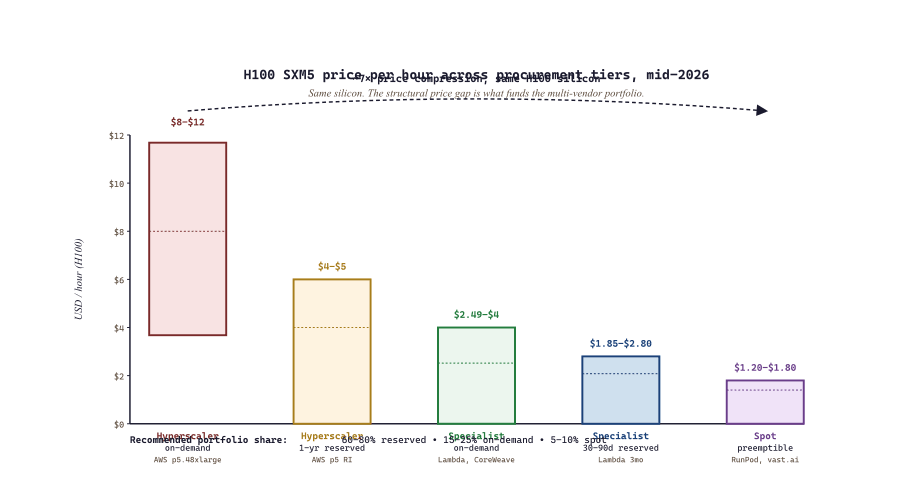
The 2026 GPU market sorts into four procurement tiers, each with different price-per-hour and different operational guarantees. The tiers compound: most production deployments use three of the four in parallel, with workload-aware routing between them.
- Hyperscaler on-demand (AWS p5, GCP A3, Azure ND): premium pricing ($8-$12/hr for H100), maximum reliability, integrated with the rest of the cloud stack. Best for production inference that cannot tolerate eviction.
- Hyperscaler reserved (1-3 year commits): 40-65% discount off on-demand. Best for steady-state production with confident multi-year forecasts.
- Specialist clouds (Lambda Labs, CoreWeave, Modal, Together AI): $2-$4/hr H100, 30-day commit terms, fewer integration features, GPU-optimized networking. Best for training and batch inference where you do not need the broader cloud surface.
- Spot markets (RunPod, vast.ai, AWS Spot, GCP Spot): $0.80-$2/hr H100, eviction risk, no SLA. Best for fault-tolerant batch jobs, evaluation runs, embedding generation.
The pricing gap between Lambda Labs / CoreWeave / Modal and AWS / GCP / Azure for an identical H100 SXM5 is structural, not transient. Hyperscalers price for the bundle (network, IAM, S3 integration, support); specialists price for the GPU itself and assume you bring your own integration. If your workload is "PyTorch in a container talking to S3", the specialist is the right venue and saves 50-70%. If your workload is "deeply integrated with twelve other AWS services", the bundle premium is worth paying. Artificial Analysis tracks the spread monthly.
57.3.2 Spot-instance economics for LLM workloads
Spot capacity (sometimes "preemptible" or "interruptible") is GPU time that the provider can reclaim at short notice (2-5 minute warning, sometimes immediate). The discount versus on-demand is steep, typically 60-80%. The tradeoff is eviction risk: any job that cannot resume cleanly from a checkpoint will lose work when the spot pool tightens.
LLM workloads split sharply on spot suitability. The fault-tolerant ones (batch inference, embedding generation, evaluation, hyperparameter sweeps) are nearly free on spot if you wire up checkpoint-resume correctly. The fault-intolerant ones (real-time inference SLAs, single-run training that cannot be restarted) need on-demand or reserved.
- RunPod Community Cloud spot: H100 PCIe at $1.20-$1.80/hr, A100 at $0.60-$1.10/hr, eviction notification 60 seconds. Resilient to brief outages; usable for batch with sane checkpoint cadence.
- vast.ai marketplace: peer-to-peer GPU rental; pricing varies widely (H100 at $1.50-$2.50/hr depending on host reliability score). The cheapest hosts have higher eviction rates; filter on reliability > 99% for production-grade batch work.
- AWS Spot p5: H100 at $4-$6/hr (vs $12 on-demand). Eviction rates climbed sharply during the 2024 shortage; now back to 5-15% per day in stable months. Spot Fleet across regions is the failure-mode mitigation.
- Modal serverless GPU: not technically spot, but the per-second billing and zero-idle behavior make it economically similar for bursty workloads. H100 at $4.56/hr active, $0 idle. Best when your traffic is genuinely bursty.
57.3.3 The reserved-capacity playbook
Reserved-capacity contracts are the right tool for the 70% of your workload that has a predictable floor. The 2024-2025 GPU shortage produced a generation of teams that learned the playbook the hard way: commit to a baseline that you are confident you will use, then layer spot and on-demand on top for the variable portion. The structure that works in 2026:
- Reserve your steady-state floor (60-80% of forecast): lock in 30-day or 90-day terms with a specialist provider. CoreWeave and Lambda Labs both offer monthly reservation pricing roughly 30% below their on-demand rates with no annual commitment.
- Bridge the predictable-burst layer with on-demand: the next 15-25% of capacity above the reserved floor. Use hyperscaler on-demand or specialist on-demand depending on integration needs.
- Cover the unpredictable spikes with spot: the top 5-10% gets routed to RunPod or vast.ai spot. If spot is not available in the moment, gracefully degrade (queue requests, route to a cheaper model, defer batch work).
- Pre-negotiate burst capacity: a "right to surge to 2x reservation for 7 days/month" clause is standard with specialist providers and costs almost nothing if you never use it. Get it in writing before you need it.
A retrieval-heavy B2B startup running mid-2025 served roughly 12M user queries/month, each costing ~$0.0008 in inference. Their procurement portfolio: 8 reserved H100s on CoreWeave for the steady-state baseline (~$2.40/hr each on a 90-day commit, total ~$14K/month), bursting to 4 additional on-demand H100s during US-business-hours peaks (~$3.50/hr, used 6 hours/day average), and routing nightly embedding-refresh jobs (~80M docs/month) to RunPod spot at $1.30/hr. Total monthly GPU cost: ~$22K against ~$95K MRR, giving a healthy 23% gross-margin contribution from compute. The equivalent setup on AWS p5 on-demand would have cost ~$70K/month, flipping the unit economics. The procurement strategy was worth roughly one senior engineer's salary saved.
The most expensive procurement mistake in the 2024-2025 cycle was the team that signed a one-year H100 reservation in mid-2024 at "discounted" rates, then saw on-demand pricing drop 35% by Q1 2025 as supply caught up. They were locked in above market for nine months. The fix: limit your reservation horizon to 90 days unless you are confident pricing is going up, not down. Specialist providers are increasingly willing to write 30-day-renewable terms; use them. Multi-year hyperscaler contracts only make sense if you have firm multi-year revenue visibility, which almost no early-stage AI product does.
57.3.4 Comparing the procurement venues
| Venue | Tier | $/hr (H100) | Term | Best for |
|---|---|---|---|---|
| AWS p5.48xlarge (on-demand) | Hyperscaler | $8-$12 | Hourly | Tight cloud integration |
| AWS p5 (1-yr reserved) | Hyperscaler reserved | $4-$5 | 1 year | Steady-state w/ AWS-dependent stack |
| CoreWeave on-demand | Specialist | $3-$4 | Hourly | Training + production inference |
| CoreWeave reserved (30-day) | Specialist reserved | $2.20-$2.80 | 30 days | Predictable baseline capacity |
| Lambda Labs On-Demand Cloud | Specialist | $2.49 | Hourly | Pure GPU training / batch |
| Lambda Reserved Cloud (3 mo) | Specialist reserved | $1.85-$2.20 | 3 months | Quarterly training cycles |
| Modal (serverless) | Specialist serverless | $4.56 (active only) | Per-second | Bursty inference, zero idle |
| Together AI (batch) | Specialist | $2-$3 equiv. | Per-token | Open-weight serving + batch |
| RunPod Secure Cloud | Specialist | $2.79 | Hourly | Containerized batch + inference |
| RunPod Community Spot | Spot | $1.20-$1.80 | Hourly (preemptible) | Fault-tolerant batch |
| vast.ai marketplace | Spot | $1.50-$2.50 | Hourly (variable) | Lowest-cost batch with checkpointing |
Sign up for accounts at CoreWeave, Lambda Labs, Modal, RunPod, and the spot markets now, even if you only actively use one or two. The onboarding (KYC, billing setup, network configuration) takes days to weeks; the moment you actually need to fail over because your primary provider is out of H100s is the worst possible time to start that paperwork. Treat multi-vendor presence as cheap insurance, not as active multi-cloud spend. Most accounts cost nothing while idle.
57.3.5 Procurement as a continuous practice
Procurement is not a one-time exercise; pricing and capacity shift quarterly as new GPU generations ship, hyperscalers re-negotiate contracts with NVIDIA, and specialist providers expand their fleets. A production team should re-bid their GPU baseline every quarter: collect quotes from the top three or four candidates, model the workload against current pricing, and re-allocate if the spread has moved more than 15%. The mechanical cost of the re-bid is a half-day of engineering work; the savings on a six-figure monthly compute bill compound.
Section 57.4 closes the chapter with the breakeven analysis between API and self-hosting. Section 68.1 picks up the ROI side of the same coin: once you know what compute costs, how do you measure what the LLM dollar buys in business value.
The right GPU procurement strategy in 2026 is a tiered portfolio: reserve your steady-state floor at a specialist (CoreWeave, Lambda Labs) on 30-90-day terms, bridge predictable bursts with on-demand at the same specialist or a hyperscaler, and route fault-tolerant batch work to spot markets (RunPod, vast.ai). The pricing gap between hyperscalers and specialists is structural and worth 50-70% on the GPU line alone; the gap between on-demand and spot is another 60-80% on fault-tolerant workloads. Re-bid quarterly; keep multi-vendor accounts warm; never sign a multi-year hyperscaler reservation without firm multi-year revenue visibility.
Procurement decides what you pay; performance benchmarking decides whether the cheaper GPU actually saves money once latency and throughput are accounted for. Continue to Section 57.4: LLM Performance Benchmarking and Cross-Hardware Portability.