"The model you launched on is rarely the model you finish on. The product that survives is the one that treats every provider as a substitution, not a marriage."
A Vendor-Rotating AI Agent
The model you launched on is rarely the model you finish on. Models get deprecated, prices change, new entrants offer better capabilities, regulators in your geography restrict cross-border data flows. A model-rotation strategy is the explicit plan for how your product survives any of these events without a panic migration. The 2024-2026 history of LLM API providers has produced enough deprecations, price cuts, and capability jumps that a working rotation strategy is no longer optional for any product expected to live more than a year.
Prerequisites
This section assumes familiarity with drift detection in production from Section 44.5 and with model registry workflows from Section 44.1. Familiarity with LLM API patterns from Section 11.1 helps when reasoning about provider abstractions.
44.6.1 The History That Made Rotation Mandatory
Three deprecation events between 2024 and 2026 reshaped how production AI teams think about provider lock-in.
The OpenAI 2024 deprecation wave. In mid-2024, OpenAI announced deprecation of several gpt-3.5 and gpt-4 model snapshots with 6-month notice. Teams that had pinned to specific versions for compliance reasons (which Section 59.2 recommends) suddenly had to migrate to newer versions. Migration cost across the industry was estimated at thousands of engineer-weeks because most teams had not built portability.
The 2025 Anthropic and Google price recalibrations. Both providers adjusted pricing for older model versions in 2025, in some cases doubling per-token costs to nudge usage toward newer (more efficient) models. Products with thin margins on the older versions had to migrate within 30-60 days or rebuild their pricing.
The 2026 EU AI Act enforcement window. The August 2026 enforcement of the EU AI Act required EU customers to be on models with documented training-data provenance for certain risk categories. Several providers' older models did not meet the threshold; products serving EU customers had to either migrate or contract for compliant variants. Teams with portability rotated in days; teams without spent weeks on emergency migration projects.
Across all three events, the pattern was identical: teams with a model-rotation strategy treated the deprecation as a routine ops task, while teams without it treated it as an emergency. The strategy is cheap; the absence of strategy is expensive.
44.6.2 The Four Ingredients of a Workable Strategy
A working model-rotation strategy has four parts. The parts compound: missing any one sharply reduces the effectiveness of the others.
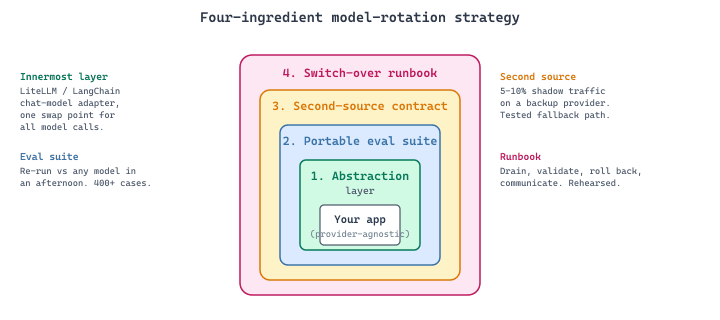
- An abstraction layer over the provider API. Calls go through a thin wrapper that exposes a stable interface and translates to whichever provider is configured. LiteLLM, LangChain's chat-model abstraction, and OpenRouter are sufficient for most cases. Provider-specific code lives in exactly one place, not sprinkled across the codebase. This is the single highest-leverage move in the strategy.
- A portable eval suite. Your golden eval set runs against any candidate model with zero code changes. When deprecation news breaks, you can re-run the eval against three alternatives within an afternoon, not three weeks. The eval suite from Chapter 42 is the prerequisite.
- A second-source contract. Even if you only use one provider in production, keep a second provider configured and tested on a small slice of traffic (5 to 10 percent). This shadow deployment costs little, validates that your abstraction layer actually works, and gives you a credible fallback the moment the primary provider has an outage. The multi-CDN tradition in web infrastructure is the right mental model.
- A documented switch-over runbook. When the day comes that you must rotate, the team should already know how to drain the primary provider, validate quality on the secondary, roll back if needed, and communicate to customers. The Google SRE workbook on playbooks is the canonical reference; LLM-specific extensions cover the eval gate and the quality-comparison plot in addition to the standard SRE elements.
An anonymized 2025 case from a Series-B SaaS company: their primary LLM provider announced a 90-day deprecation of the model their product used in production. The team had built portability the prior year: a LiteLLM-based abstraction, a 400-case eval suite that ran against any provider, and 7 percent shadow traffic on a backup provider for the prior six months. On the morning the deprecation was announced, two engineers ran the eval suite against three candidate replacement models, picked the best-scoring one (which was actually from a different provider than the original backup), promoted it to 100 percent traffic in a staged rollout over three days, and closed the migration ticket by Friday. Total engineer-time: roughly six person-days. A comparable competitor without portability later reported needing four engineer-weeks for the same migration. The portability discipline paid back roughly 4x its setup cost on this single event.
44.6.3 The Hidden Lock-In Surface
The hardest provider dependencies are not in the API calls; they are in the implicit behaviors your product has come to rely on. Four categories of hidden lock-in show up in 2025-2026 retros:
- Verbosity profile. Different models have different default response lengths and styles. A product tuned to expect a 200-word summary will look broken when a different model produces a 600-word one for the same prompt.
- Output format preferences. Some models default to bullet points; others default to prose. Some emit JSON natively; others need extra structure scaffolding. Migration that does not account for these differences produces parser failures downstream.
- Safety-filter tuning. Each provider has different refusal patterns. A medical-domain product on one provider hits widespread refusals on another provider for the identical prompts. Discover this before customers do, by running your eval set through both.
- Tokenizer idiosyncrasies. Token counts differ across providers for the same input string, so your context-window budget needs to be re-derived on rotation. Cost-per-request calculations shift, in either direction, depending on how aggressive the new tokenizer is on your traffic.
Run portability tests quarterly, not annually. A team that has not run its eval suite against a second provider in nine months is probably more locked in than it thinks, and the cost of finding out will be measured in incident-response weekends. Even if you have no current intention to switch providers, the discipline of regularly confirming you could is what makes the switch tractable when an external event (deprecation, price change, regulation) forces it. Applied LLMs (Huyen, Bittner et al.) documents teams who skipped this discipline and paid quarter-scale costs on a single rotation event.
44.6.4 The Cost-Crossover Trigger
Beyond deprecations and outages, the third common trigger for model rotation is cost crossover: a competing provider releases a model that meets your quality threshold at a meaningfully lower price. The 2024-2026 history of LLM pricing has been a sequence of these crossovers, roughly one major event per quarter. A product without portability is unable to capture the cost reduction; a product with portability captures it routinely.
The mechanical version of the cost-crossover check: monthly, run your eval set against the three lowest-cost models that meet a "could plausibly work" filter. If any of them clear your quality threshold at a lower per-call cost than your current production model, the migration ROI calculation becomes "weeks of engineer-time saved per year" versus "days to migrate," and the answer almost always favors migration. Mature teams in 2026 have automated this monthly check; the decision to migrate, when triggered, is reviewed by the PM and engineering lead but no longer requires a project initiation phase.
A hybrid rotation pattern emerging in 2026: high-volume, lower-risk traffic (classification, extraction, schema translation) routes dynamically to the lowest-cost model that meets the quality threshold today; low-volume, high-risk traffic (financial decisions, legal drafts, medical triage) pins to a specific dated model snapshot. The combination captures cost savings on the dominant traffic without compromising stability on the traffic that matters most. LiteLLM's router and similar abstractions support this pattern out of the box.
44.6.5 The Single Most Cited 2026 Mistake
Across a survey of 40 post-mortems published or shared informally in late 2025 and early 2026, the single most-cited mistake under "what would you do differently" was variation on a theme: "We did not build provider abstraction early enough. By the time we needed to rotate, the lock-in surface was much larger than we expected." The mistake compounded across deprecations, price changes, and capability jumps. Teams that built abstraction in the first quarter post-launch reported rotation as a routine ops task; teams that built it later, or not at all, reported each rotation as a multi-week project.
The implied recommendation for any LLM product team in 2026: build the abstraction in the first quarter, then exercise it quarterly even when no rotation is needed. The exercise is what keeps the abstraction working. An abstraction layer that has not been used against two providers in six months has decayed; you will discover the decay at the worst possible moment.
By mid-2025, "just LiteLLM it" had become engineer shorthand for "we should not be writing direct provider SDK calls in this codebase". The phrase showed up in the README of so many migration PRs that BerriAI, the company behind LiteLLM, added a humorous achievement badge for repos that hit 100 provider-agnostic calls. Internally the team called the badge the multi-cloud merit badge, and it became something of a recruiting hook: candidates would screenshot their LiteLLM-fronted dashboards in interview portfolios to demonstrate they understood rotation discipline. The pattern was so prevalent that "we cannot rotate, we cannot LiteLLM" graduated from joke to legitimate engineering red flag.
- The 2024-2026 history of LLM providers has produced enough deprecations, price changes, and regulatory shifts that model-rotation strategy is non-optional.
- The four ingredients are: provider abstraction, portable eval suite, second-source contract, switch-over runbook.
- Hidden lock-in lives in verbosity, output format, safety filters, and tokenizers; discover it before customers do.
- Monthly cost-crossover checks (eval against cheaper alternatives) capture routine savings without project overhead.
- The most-cited 2026 mistake is delayed abstraction; build it in the first quarter and exercise it quarterly.
Once you can rotate models cleanly, the next leverage point is buying that capability as a managed product rather than building it in-house. Continue to Section 44.7: Eval-as-Product: Braintrust, Latitude, Laminar to see the vendor landscape that has emerged around this need.