"The legal LLM vendor list moves quarterly. The bar-association rules move yearly. Plan procurement accordingly."
Sage, Vendor-Watcher AI Agent
This closing section consolidates the vendor landscape, the cross-references to other in-book chapters that matter for a legal-LLM build, and the canonical external sources that every practitioner should have on file. The vendor list is descriptive of the mid-2026 market and will continue to consolidate; the cross-references and the bibliography are stable and load-bearing.
Prerequisites
This is a vendors-and-further-reading section. It assumes familiarity with the earlier sections in this chapter (Sections 67.1 through 72.4) and the LLM-platform vocabulary from Section 14.1.
The 2026 Vendor Landscape, Revisited
Thomson Reuters paid $650M for Casetext in June 2023, the largest legal-tech acquisition on record at the time. The deal closed roughly 90 days after CoCounsel launched, making Casetext the fastest-monetized GPT-4 wrapper in history. The Thomson Reuters integration team reportedly spent more on legal due diligence than the entire engineering cost of the CoCounsel product itself.
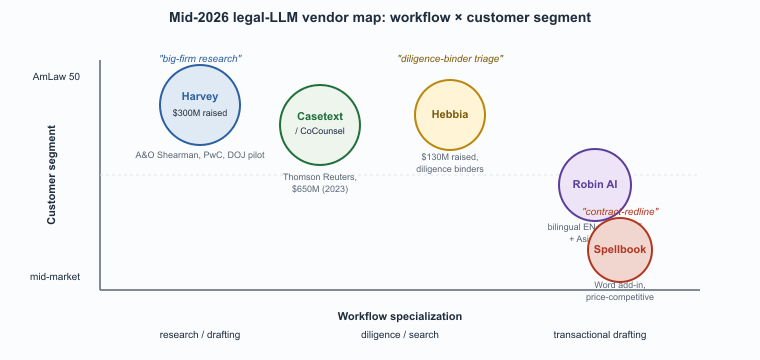
Section 67.1 introduced the five vendors that have consolidated as the dominant legal LLM platforms. The list below adds the additional context that procurement teams typically ask about: financing, scale, and the specific practice areas each vendor has invested in.
- Harvey. Founded 2022 by Winston Weinberg (formerly Latham & Watkins) and Gabriel Pereyra (formerly OpenAI, DeepMind). Raised over $300M across 2023 to 2025. Customers include Allen & Overy (now A&O Shearman), PwC, KPMG, the U.S. Department of Justice (pilot), and many of the AmLaw 50. Focus: assistive litigation drafting, due-diligence triage, contract review, regulatory research.
- Hebbia. Founded 2020 by George Sivulka. Raised over $130M through 2024. Originally a financial-services search product, has expanded into legal due diligence. Differentiation: structured-extraction and table-construction over large document sets, useful for diligence binders running into tens of thousands of pages.
- Casetext / CoCounsel. Founded 2013, acquired by Thomson Reuters in 2023 for $650M. Built on top of the Westlaw corpus, which gives it the most direct path to a Layer 5 citation-resolution service. Customer base concentrated in mid-market and large law.
- Spellbook. Founded 2020. Word add-in for transactional drafting and redlining. Mid-market focus; competitive on price and integration ease.
- Robin AI. Founded 2019. Transactional-contract focus, with bilingual coverage (English plus Spanish, French, German, and several Asian-language pairs) that distinguishes it for European and multinational clients.
Beyond these five, a long tail of in-house tools and open-source frameworks (LangChain-based RAG pipelines over Westlaw, custom fine-tunes of open-weight models on private corpora) accounts for a meaningful share of total legal-LLM usage at the largest firms. The build-versus-buy decision turns on the firm's scale, its existing engineering capacity, and its appetite for ongoing maintenance; for most mid-market firms, buying is the right call.
The legal-LLM market in 2026 is not winner-take-all. Unlike consumer-LLM markets, where one or two products dominate, legal-LLM customers buy two or three tools to cover different parts of the workflow: a research-and-drafting tool (Harvey or Casetext), a diligence-and-search tool (Hebbia or DiligenceAI), a transactional-drafting tool (Spellbook or Robin AI), and an in-house fine-tune for the firm-specific knowledge management. The procurement question is therefore not "which vendor wins?" but "which combination covers your workflow?"
Cross-References Inside This Book
- Chapter 32 (RAG), the retrieval architecture every legal application sits on.
- Chapter 47 (Safety, Ethics & Regulation), the regulatory framework, including the EU AI Act's treatment of legal-decision systems as "high risk."
- Chapter 73 (Manufacturing, Creative Industries, Search & Recommendation), broader industry survey.
- Section 53.4 (Privacy & IP), the privilege-leakage framing.
- Section 29.4 (Coding agents), the verifier-loop pattern that informs Layer 5 here.
Canonical External References
- ABA Model Rule 1.1, Comment 8, the source authority for the duty of technological competence cited in Section 67.3.
- EU AI Act consolidated text (Regulation 2024/1689); Annex III defines legal-decision systems as high-risk and triggers conformity-assessment obligations.
- CourtListener REST API documentation, the standard free-tier reference data source for citation-verification pipelines.
- Mata v. Avianca, full docket and sanctions order, the founding case study for every legal LLM verification policy.
Research Frontier: Where Legal LLMs Are Heading
Legal LLM research in 2024 to 2026 is converging on three threads that all share a common theme: making model outputs verifiable against authoritative legal sources rather than trusting the model's parametric memory.
LegalBench (Guha et al., NeurIPS 2023, arXiv:2308.11462) provides 162 tasks across six legal reasoning categories and remains the canonical benchmark for whether a model has learned legal reasoning patterns rather than just legal-sounding text. CaseHOLD (Zheng et al., 2021) and the follow-on CUAD (Hendrycks et al., 2021) test multiple-choice case-holdings and contract-clause extraction at scale and now serve as the public floor for vendor capability claims.
On the verification side, Stanford's RegLab hallucination study (Dahl et al., 2024, arXiv:2401.01301) measured citation-hallucination rates at 58 to 82 percent across major frontier models on legal queries, motivating the verified-RAG architecture in 72.4. SaulLM-7B and SaulLM-141B (Colombo et al., 2024, arXiv:2403.03883) demonstrated that domain-specific pretraining on case law yields meaningful gains on LegalBench at modest scale, opening a path for firms with sufficient corpus access.
Where the field is moving: agentic legal research with explicit citation-verification loops, fine-tuning on jurisdiction-specific corpora (state law, EU member-state law), and a slow shift in bar-association rules from "use AI carefully" toward "audit logs and reproducibility are required." The interesting open question is whether vertical legal LLMs will eat the horizontal frontier-model market in legal, or whether the frontier models will catch up via domain RAG and reasoning chains.
Objective
Run GPT-4o over 50 contracts drawn from the public Contract Understanding Atticus Dataset (CUAD), extract a fixed set of clauses (governing law, termination for convenience, indemnification cap, change of control), and measure precision and recall against the attorney-annotated gold standard that ships with CUAD. The point is to feel the gap between "the model sounds confident" and "the clause was actually identified at the right span."
Setup
You need an OpenAI API key, the CUAD dataset (Hendrycks et al., 2021, hosted on the Atticus Project site at atticusprojectai.org/cuad and mirrored on Hugging Face as theatticusproject/cuad), and Python 3.10 or later.
pip install openai datasets scikit-learn pandasSteps
- Sample 50 contracts from CUAD with a fixed random seed. CUAD has 510 contracts with 41 clause categories; pick the four target clauses above so that a single prompt extracts them all at once.
- Write a strict-JSON extraction prompt that asks GPT-4o to return each clause text verbatim or
nullif absent. Constrain output with a JSON schema and a temperature of 0 to keep results reproducible. - Score against gold using exact-match span overlap (lenient: any token-level Jaccard above 0.5 counts as a hit) and compute precision, recall, and F1 per clause category. CUAD ships the gold annotations as character offsets in the original PDF text.
- Inspect the errors. The interesting failures are the false positives (model invented a clause that is not in the contract) and the boundary errors (right clause, wrong span). Save 10 examples of each for the writeup.
- Compare to the verified-RAG architecture from Section 67.4 by re-running 10 contracts with a retrieval step that returns the top-3 candidate paragraphs before extraction. Does precision improve? Does recall drop?
Expected Output
A CSV with one row per (contract, clause) pair holding the predicted span, the gold span, the Jaccard score, and a hit flag, plus a summary table of precision, recall, and F1 per clause category. On CUAD with GPT-4o and a single-pass prompt, governing-law clauses typically score above 0.90 F1 because the surface form is highly stereotyped, while indemnification-cap clauses often fall below 0.60 F1 because the relevant language is buried in long composite paragraphs.
Extension
Re-run the same pipeline with Anthropic's Claude Sonnet 4.7 and compare the error distributions; legal-extraction failures are often model-specific, and the cross-model audit is the closest practical proxy for the verification policy the bar-association guidance now expects.
What Comes Next
Chapter 67 ends here. The next chapter (Chapter 68 on finance) covers the parallel industry where regulatory friction is equally intense and the failure-mode catalog has equally specific cures. Many of the verification patterns from this chapter generalize directly; the difference in finance is that the verification target shifts from "does this case exist?" to "is this number traceable to a structured filing?"
What's Next?
In the next chapter, Chapter 68: Use Cases That Actually Ship in Finance, we continue building on the material from this chapter.