"An API key is a six-month commitment to a vendor's roadmap. Choose the vendor, not the model."
Compass, Vendor-Locked-In-But-Honest AI Agent
"Platform" in Part III means something different from Parts I and II: in those parts the platform was a GPU cluster or an inference server, but here it is the LLM-as-a-service vendor whose API your agent code lives against (OpenAI, Anthropic, Google, Mistral, Cohere, Together, Groq, Replicate, Fireworks, Bedrock, Vertex). This section maps that vendor shelf and tells you when each platform earns its monthly invoice.
Prerequisites
This section assumes you have built simple LLM API calls from Section 11.1, understand auth and retry patterns from Section 11.4, and have a working mental model of the closed-versus-open split from Section 10.6.
"Platform" in Part III means something different from Parts I and II. Where Part II's question was "where do I run a 70-billion-parameter open-weights model when I do not own an H100", Part III's question is the inverse: "where do I call a frontier model I will never run myself, and what stack sits between my code and that inference endpoint". The answer is a small ecosystem of managed-inference providers, and the choice among them has gotten more interesting (not less) as the market matured through 2025.
This section maps that ecosystem the way Sections 6.1 and 12.1 mapped theirs: vendor by vendor, what they sell, when to pick them, when not to. The shape of the 2026 market is roughly two tiers: first-party model providers (OpenAI, Anthropic, Google) who own the underlying models, and aggregator / model-router platforms (AWS Bedrock, Azure OpenAI, Together, Replicate, Fireworks) who resell those plus their own. The tier you pick shapes pricing, latency, and most importantly which models you have access to.
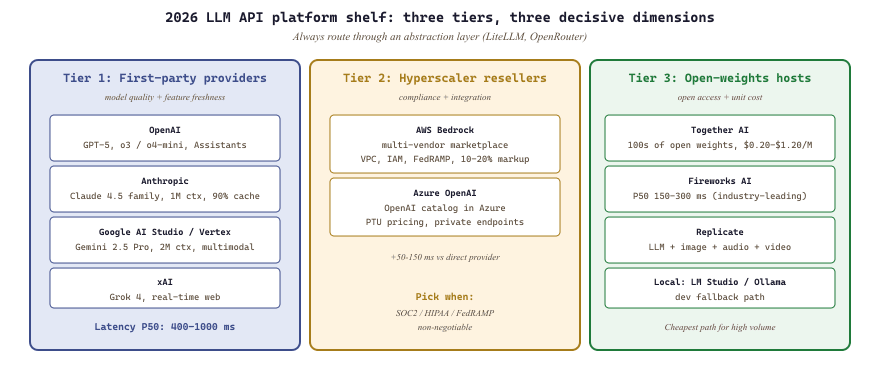
14.1.1 First-party model providers
OpenAI: the default for many production teams. USP: GPT-5 family (released 2025) plus the multimodal o-series reasoning models; the broadest tool-use ecosystem (Assistants, structured outputs, file search); the most mature batch API. Pick OpenAI when you want the broadest feature surface and you can tolerate vendor-lock to their tool-use formats. Anti-recommendation: do not pick OpenAI as your only provider; the 2023 and 2024 service incidents made multi-provider abstraction layers mandatory.
Anthropic: the default for long-context and tool-heavy workloads. USP: the Claude 4 family (Opus 4.5, Sonnet 4.5, Haiku 4.5; the Opus class powers this book's authoring stack) plus extended-thinking on Claude 3.7+; the 1M context window; prompt caching with the most aggressive pricing in the market (90% discount on cache hits, see Anthropic prompt caching docs). Pick Anthropic when you have long-context workloads (codebases, document review) or when cache hit rates dominate cost. Anti-recommendation: skip if your workload is high-frequency low-token chat where Haiku is overkill and a smaller open-weights model would be cheaper.
Google AI Studio and Vertex AI: Google's two front doors to Gemini. AI Studio is the developer-friendly free-tier-included entry; Vertex is the GCP-integrated enterprise version. USP: Gemini 2.5 Pro's native multimodality (image, video, audio in one model) and the cheapest frontier-class long-context tokens by a wide margin in 2025. Pick when you do video understanding, when you are already on GCP, or when long-context cost dominates. Anti-recommendation: avoid Vertex if you are not on GCP; the integration surface assumes you are.
14.1.2 The hyperscaler resellers
AWS Bedrock: a model marketplace inside AWS. USP: every major closed-weights provider (Anthropic, Cohere, Meta, AI21, Mistral, plus Amazon Nova) behind one IAM-controlled API, with VPC-private endpoints and full audit logging. Pick Bedrock when you are an AWS-shop enterprise where data residency, SOC2, or HIPAA controls are non-negotiable. Anti-recommendation: Bedrock pricing is a 10 to 20% markup over direct provider pricing; do not use it for cost-optimization, only for compliance.
Azure OpenAI: OpenAI's models hosted in Azure with private endpoints and enterprise SLAs. USP: same models as OpenAI direct but with Azure's compliance and data-residency story; provisioned-throughput-unit (PTU) pricing offers predictable latency for high-volume workloads. Pick if you are a Microsoft-shop with regulatory constraints. Anti-recommendation: do not use Azure OpenAI for experimentation; the deployment-creation flow is slow and the model catalog lags OpenAI direct by weeks.
14.1.3 The independent inference platforms
Together AI: the largest open-weights inference host. USP: serverless inference for hundreds of open-weights models (Llama 4 family, Qwen3, DeepSeek, Mixtral) at competitive per-token pricing, plus dedicated endpoints for production traffic. Pick Together when you want to serve open-weights models without operating GPUs. Anti-recommendation: not the cheapest for very high volume; at that point dedicated GPUs on RunPod or self-hosted vLLM are better.
Replicate: per-request serverless for any model published to its registry. USP: the easiest way to call image, audio, and video models alongside LLMs from one API; the registry is the most diverse in the industry. Pick Replicate for multi-modal applications where you mix-and-match models and accept warm-start latency. Anti-recommendation: avoid for latency-sensitive chat where the cold-start overhead is unacceptable.
Fireworks AI: open-weights specialist focused on throughput and latency optimization. USP: the fastest open-weights inference benchmarks in 2025 (often 2-3x throughput of Together on Llama-class models) and a quality-controlled fine-tuning service. Pick Fireworks when latency or tokens-per-second matter more than model breadth. Anti-recommendation: smaller model catalog than Together; if you need a very long tail of open-weights options, look elsewhere.
Beyond hosted APIs, three desktop / local-inference clients matter in 2026 even for API-first developers, because they make "let me try the open-weights equivalent" cheap. LM Studio (2024) is the dominant local Mac / Windows GUI, with a one-click MLX backend on Apple Silicon and an OpenAI-compatible local server. Ollama is the terminal-friendly equivalent. Msty (2024-25) is the emerging multi-model desktop client with side-by-side chat and provider routing built in. The pattern in 2026 is to ship API-first but keep a local fallback path for development and offline demos.
14.1.4 The platforms compared
| Platform | Tier | Approx pricing (input/output per 1M, frontier tier) | Latency profile | Model coverage | Enterprise features |
|---|---|---|---|---|---|
| OpenAI | First-party | $5-$15 / $20-$60 | P50 ~400-800 ms first-token | OpenAI only | SOC2, ZDR, Enterprise tier |
| Anthropic | First-party | $3-$15 / $15-$75 | P50 ~500-900 ms; aggressive prompt cache | Claude only | SOC2, HIPAA add-on, ZDR |
| Google AI Studio | First-party | $1.25-$10 / $5-$30 | P50 ~600-1000 ms; native multimodal | Gemini only | Vertex tier for enterprise |
| AWS Bedrock | Reseller | 10-20% markup over direct | +50-150 ms vs direct provider | Anthropic, Meta, Cohere, Amazon, Mistral | VPC, IAM, full audit, SOC2/HIPAA/FedRAMP |
| Azure OpenAI | Reseller | Same as OpenAI direct | Similar to direct; PTU for guaranteed | OpenAI catalog (delayed) | Azure compliance suite, private endpoints |
| Together AI | Open-weights host | $0.20-$1.20 / $0.20-$1.20 (Llama-class) | P50 ~200-400 ms | Hundreds of open-weights | SOC2, dedicated endpoints |
| Replicate | Multi-modal host | Per-second compute pricing | Variable; cold starts possible | LLMs + image + audio + video | Custom deployments |
| Fireworks AI | Open-weights host | $0.15-$1.00 / $0.15-$1.00 | P50 ~150-300 ms (industry-leading) | Curated open-weights + custom | Fine-tuning, dedicated endpoints, HIPAA |
In 2026, hard-coding to one provider's SDK is a 2022 mistake. Use LiteLLM, OpenRouter, or the OpenAI-compatible endpoint everyone now ships. The cost of staying provider-agnostic is small (an extra HTTP hop); the value when a provider has an outage, deprecates a model, or quietly slows down is enormous.
Every number in the table above is roughly correct as of late 2025 and will be wrong by the time you read this. Pricing for frontier models drops by 20-50% year-over-year and the latency story shifts with each new generation of inference hardware. What stays stable: your application's latency budget. If your end-to-end UX requires sub-300 ms first-token latency, you have ~3-5 options regardless of pricing. If your UX is batch-async (overnight report generation), pricing matters and latency does not. Pick the dimension your product actually depends on.
Two tiers, three reasons to choose. Tier 1 (first-party providers: OpenAI, Anthropic, Google) wins on model quality and feature freshness. Tier 2 (hyperscaler resellers: Bedrock, Azure OpenAI) wins on compliance and integration. Tier 3 (independent inference hosts: Together, Replicate, Fireworks) wins on open-weights access and unit cost. Pick by which dimension your product is most constrained on, and always route through an abstraction layer.
14.1.5 Default recommendations
For Part III's exercises: start with the free tiers of OpenAI, Anthropic, and Google AI Studio in parallel, hidden behind LiteLLM. Switch to AWS Bedrock or Azure OpenAI only when compliance forces it. Reach for Together, Replicate, or Fireworks when an open-weights model is the right tool. Never call only one provider in production code; the abstraction layer is mandatory.
Section 14.2 next turns from the inference endpoint to the client library that calls it: SDKs, agent frameworks, prompt-management tools, and the observability surface that makes any of this debuggable in production.
API Keys and Secrets Management
Almost every LLM workflow needs a credential: a Hugging Face token for gated models, an OpenAI or Anthropic key for inference, a Weights & Biases token for experiments, or a cloud-provider key for object storage. Where you put them determines whether you become a data-leak news story. This is the canonical home for "where do I put my keys?" and "how do I keep them out of Git?"
The threat model is not theoretical: GitGuardian's 2024 "State of Secrets Sprawl" counted 23+ million secrets exposed in public GitHub commits in 2023 alone, with OpenAI, Anthropic, and Hugging Face API keys in the top-ten leaked credential types. The fix is straightforward: never commit a secret, pick the right backend for the context, rotate when something slips, use IAM roles when possible. The Git-side discipline that catches leaks after they happen is in Section 5.2 (Libraries & Frameworks); this is the prevention counterpart.
The rule that prevents 99% of credential leaks: every secret lives in an environment variable, a keyring entry, or a managed secret store. Never a hard-coded string in a Python file, notebook output, or Git-tracked config. If a key ends up in Git history, rotate it immediately: rewriting history does not erase the value from anyone who already cloned, from forks, or from bots that scrape new commits within minutes.
1. The .env File and python-dotenv
The default starting point for local development: a .env file plus python-dotenv. Keep keys in .env, add .env to .gitignore, load at process start.
# .env (NEVER commit this; add to .gitignore)
OPENAI_API_KEY=sk-proj-abc123...
ANTHROPIC_API_KEY=sk-ant-...
HF_TOKEN=hf_...
WANDB_API_KEY=...# app.py (this is fine to commit)
import os
from dotenv import load_dotenv
# Load .env into os.environ; safe to call multiple times.
# By default looks for .env in cwd and walks upward.
load_dotenv()
# Then use the standard environment-variable pattern; most SDKs
# auto-pick these up without explicit configuration.
from openai import OpenAI
from anthropic import Anthropic
openai_client = OpenAI() # reads OPENAI_API_KEY
anthropic_client = Anthropic() # reads ANTHROPIC_API_KEY
# For HuggingFace, the standard env var is HF_TOKEN (also HUGGING_FACE_HUB_TOKEN);
# huggingface_hub picks it up automatically:
from huggingface_hub import login
# login() with no args uses the env varPair every .env with a committed .env.example that documents variables without values so new contributors know what to fill in. Add .env, .env.local, and *.env to .gitignore on day one of every repo.
Most LLM SDKs in 2025-2026 auto-detect their standard environment variables: OPENAI_API_KEY, ANTHROPIC_API_KEY, OPENROUTER_API_KEY, HF_TOKEN, COHERE_API_KEY, GOOGLE_API_KEY, WANDB_API_KEY. You almost never need to pass the key explicitly in code; load_dotenv() followed by client construction is enough.
Show code
# Standard auto-detect pattern: load .env, then construct clients with no args.
from dotenv import load_dotenv
from openai import OpenAI
from anthropic import Anthropic
load_dotenv() # reads .env into os.environ
openai_client = OpenAI() # picks up OPENAI_API_KEY
anthropic_client = Anthropic() # picks up ANTHROPIC_API_KEY
resp = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "ping"}],
)
print(resp.choices[0].message.content)
2. OS Keyrings: keyring for Personal Machines
.env is plaintext on disk. The personal-machine upgrade: the OS-native credential store via the keyring Python library, which uses macOS Keychain, Windows Credential Manager, or Linux Secret Service. Keys are encrypted at rest by the OS, unlocked by your session, and never sit in plaintext.
import keyring
# Set once (e.g. from an interactive shell or a setup script)
# keyring.set_password("openai", "default", "sk-proj-abc123...")
# Read at runtime
api_key = keyring.get_password("openai", "default")
import os
os.environ["OPENAI_API_KEY"] = api_key # then standard SDK auto-pickup worksThe keyring CLI lets you set values without shell history (keyring set openai default prompts). Trade-off: entries do not travel with the repo, so CI and new machines need their own setup.
3. Team and Production: Managed Secret Stores
For teams and production, a managed secret store replaces .env. Five options dominate.
| Tool | Hosting | Best For | Pricing Model | Rotation Support |
|---|---|---|---|---|
| HashiCorp Vault | Self-host (OSS) or HCP managed | Polyglot teams, on-prem, hybrid cloud | Free OSS; HCP managed by namespace | Native dynamic secrets |
| AWS Secrets Manager | AWS-managed | AWS-native workloads | Per secret per month + API calls | Native scheduled rotation (Lambda) |
| GCP Secret Manager | GCP-managed | GCP-native workloads | Per active secret version + access | Versioning + manual / external rotation |
| Azure Key Vault | Azure-managed | Azure-native workloads | Per transaction + premium tier | Native rotation policies (2024+) |
| Doppler | SaaS | Polyglot startups; cross-env sync | Per seat / per workspace | Integration-based rotation |
HashiCorp Vault is most flexible and the standard for self-hosting, polyglot teams, or multi-cloud. Vault's dynamic-secrets feature issues short-lived credentials on demand, the strongest defense against exfiltration. AWS Secrets Manager, GCP Secret Manager, and Azure Key Vault are cloud-native choices with first-class IAM, audit, and rotation. Doppler is the SaaS option startups pick because it syncs secrets across .env, GitHub Actions, Vercel, AWS, and similar targets.
4. IAM Roles: The Cloud Workload Pattern
For workloads on a cloud you control (EC2, ECS, Fargate, GKE, AKS, Cloud Run), the best secret-management answer is no secrets at all. Attach an IAM role to the instance; the SDK fetches short-lived credentials via the metadata service. The provider rotates automatically (typically every few hours); your code never sees a long-lived key.
import boto3
# No access key needed; boto3 picks up the IAM role attached to the
# EC2 instance, ECS task, or Lambda function via the metadata service.
s3 = boto3.client("s3")
response = s3.list_buckets()
# Same pattern works for cross-service: an IAM role can have permission
# to read secrets from Secrets Manager, so you fetch an OpenAI key
# without ever embedding an AWS access key.
secrets = boto3.client("secretsmanager")
openai_key = secrets.get_secret_value(SecretId="openai/prod")["SecretString"]
os.environ["OPENAI_API_KEY"] = openai_keyGCP equivalent: Workload Identity (GKE) or default service accounts (Cloud Run, Cloud Functions). Azure equivalent: Managed Identity. Same pattern: bind workload to identity, grant access to needed secrets, never embed a long-lived credential. This is the 2024-2026 production consensus and the explicit recommendation in every cloud's security guidance.
Quality hierarchy, worst to best: hard-coded, .env tracked in Git, .env in .gitignore, OS keyring, managed secret store, IAM role with no long-lived secret. Each step removes one leak class. Personal projects stop at .env; cloud services should reach IAM roles. Production with managed store and no long-lived keys is the gold standard.
5. CI/CD: Repository Secrets
For CI/CD (GitHub Actions, GitLab CI, CircleCI), use the platform's native repository secrets. They are encrypted at rest, decrypted into env vars at job runtime, and redacted from logs by default. The GitHub Actions pattern:
# .github/workflows/eval.yml
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
- run: pip install -r requirements.txt
- run: python run_eval.py
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
HF_TOKEN: ${{ secrets.HF_TOKEN }}Never echo a secret (redaction is best-effort), never pass one as a CLI arg (it shows in process listings), prefer env vars over files. For OIDC-supporting platforms, GitHub Actions can assume an AWS or GCP IAM role directly, eliminating long-lived cloud keys from the secrets list entirely.
A team's nightly evaluation job needed AWS access to read a calibration dataset from S3. The legacy setup stored an AWS_ACCESS_KEY_ID as a GitHub repo secret, which rotated quarterly via a Slack reminder that was missed twice in 2024. The fix took 30 minutes: create an IAM role with a trust policy that names the repo's OIDC issuer (https://token.actions.githubusercontent.com), drop the secrets, and replace the env block with permissions: id-token: write plus the aws-actions/configure-aws-credentials@v4 action. The job now exchanges a short-lived OIDC token for a 1-hour AWS session at every run. Total long-lived secrets removed: 4. Incidents avoided since: 0 (which was the whole point).
6. Rotation: It Has to Be Routine
Rotation is what teams skip until they have an incident. Defensible policy: production keys rotate quarterly (90 days), staging twice yearly, personal keys on developer departure or annually. Managed stores support scheduled rotation (AWS via Lambda, GCP via external scheduler, Vault via dynamic secrets). Hugging Face, OpenAI, and Anthropic require manual rotation: generate new, update store, verify, revoke old.
7. Leak Detection: Pre-Commit and Continuous Scanning
The complement to good hygiene is automated detection. Three open-source tools dominate: detect-secrets (Yelp), gitleaks (Zach Rice), trufflehog (Truffle Security). All three run as pre-commit hooks and in CI.
# .pre-commit-config.yaml
repos:
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: [--baseline, .secrets.baseline]
- repo: https://github.com/gitleaks/gitleaks
rev: v8.21.0
hooks:
- id: gitleaksRun detect-secrets scan > .secrets.baseline once; subsequent commits fail on new secrets not in the baseline. The 2024-2025 GitHub-native answer is Push Protection, which scans on every push and blocks commits containing recognized secrets across hundreds of providers; enable on every repo with credentials.
The most common 2024-2025 OpenAI / Hugging Face leak in publicly-disclosed incidents was not .env committed by mistake; it was a Jupyter notebook with os.environ["OPENAI_API_KEY"] = "sk-..." hard-coded in a cell. Notebooks save source and outputs; even if you clear the cell, the key may live in the JSON. Mitigations: (1) never hard-code in a notebook; load from .env; (2) use nbstripout as a pre-commit hook; (3) enable GitHub Push Protection. Cost of cleanup: hours. Cost of prevention: one pre-commit hook.
- Section 5.2 (Libraries & Frameworks) for the
.gitignorepatterns and history-rewriting commands that catch secrets after the fact. - Section 5.1 (Platforms) for the AI-in-IDE configuration that should exclude secrets directories from indexing.
- Section 5.2 (Libraries & Frameworks) for Colab Secrets and notebook-specific patterns (
userdata.get("HF_TOKEN")). - Section 44.3 (Observability) for the production observability stack that must redact secrets from traces.
- The hierarchy: hard-coded (worst),
.envin.gitignore(prototype default), OS keyring (personal), managed secret store (teams), IAM role with no long-lived secret (gold standard). - For local development,
.env+python-dotenv+.env.example. Most LLM SDKs auto-detect standard env vars, soload_dotenv()at process start is usually all the code you write. - For team production, pick a managed secret store: Vault (self-host), AWS / GCP / Azure (cloud-native), Doppler (SaaS sync). All support scheduled rotation; use it.
- For cloud workloads, IAM roles eliminate long-lived credentials entirely. Bind workload identity, grant access, never embed long-lived keys in container images.
- Layer leak detection over hygiene:
detect-secretsandgitleakspre-commit, GitHub Push Protection on every repo,nbstripoutfor notebooks. Hard-coded notebook keys are the dominant 2024-2025 leak pattern. - Rotate routinely: 90 days for production, twice yearly for staging, on-event for personal. The difference between "near miss" and "customer notifications."
What Comes Next
Continue to Section 5.2 (Libraries & Frameworks) to run the smoke test that confirms your CUDA stack, library versions, and credential plumbing are all functional.