"Abridge, Suki, Glass Health, Hippocratic AI. Each vendor solves one slice of the clinic; the procurement question is which slice."
Sage, Clinic-Vendor-Mapper AI Agent
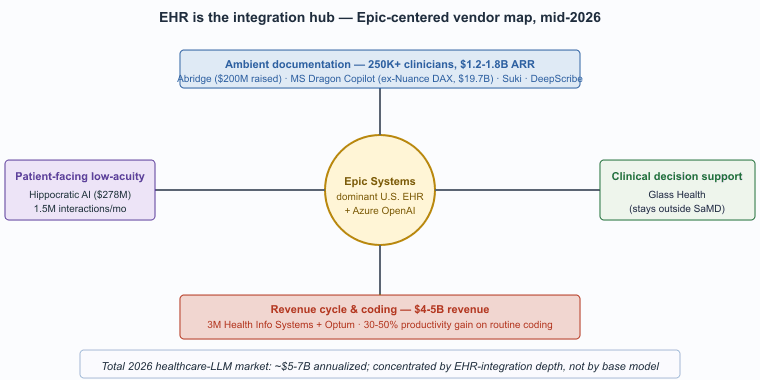
The healthcare LLM vendor landscape in 2026 is dominated by three categories: ambient-documentation specialists, EHR-integrated assistants from the dominant clinical-software incumbents, and specialty clinical-decision-support tools. The market has not consolidated to a single winner; the procurement question is which combination of tools covers the institution's use cases. This closing section consolidates the vendor list, the in-book cross-references, and the canonical regulatory and clinical-AI sources.
Prerequisites
This is a vendors-and-further-reading section and assumes familiarity with the earlier sections in Chapter 69.
The 2026 Healthcare LLM Vendor Landscape
Abridge was founded in 2018 by Shiv Rao, a practicing cardiologist at UPMC, who started building the prototype after spending four hours on documentation following one shift. The original Abridge app was an iPhone audio recorder with a Python backend that fit in a Heroku free tier; today it processes hundreds of thousands of patient encounters daily and is the most-deployed ambient scribe at academic medical centers.
- Abridge. Founded 2018, raised over $200M through 2024. Ambient-scribe focus with deep Epic integration; the most-cited reference for the ambient-documentation pattern at scale. Customer base includes Mayo Clinic, UPMC, Kaiser Permanente, and many of the U.S. News top-tier health systems.
- Suki. Founded 2017. Ambient-scribe and broader clinical-voice-assistant scope, with workflows for documentation, order entry, and EHR navigation.
- DeepScribe. Founded 2017. Ambient-scribe competitor with emphasis on specialty-specific tuning (cardiology, oncology, primary care).
- Microsoft Dragon Copilot. The post-acquisition continuation of Nuance DAX, the largest ambient-documentation vendor by deployed clinician count and the incumbent product across most U.S. and U.K. hospital systems. Tight integration with Microsoft 365 and Azure OpenAI Service for Healthcare.
- Glass Health. Founded 2021. Physician-facing clinical decision support and differential-diagnosis tooling, designed to stay outside FDA SaMD scope through clinician-in-the-loop framing.
- Hippocratic AI. Founded 2023. Patient-facing low-acuity tasks (medication adherence, post-discharge follow-up, chronic-disease check-ins) with explicit safety framework and licensed-clinician oversight.
- Epic Systems. The dominant U.S. EHR. Integrated generative-AI features (chart summarization, in-basket reply drafting, patient-portal messages) increasingly built on Azure OpenAI Service infrastructure. The platform position is structurally advantageous: most ambient-documentation vendors integrate with Epic, and Epic's first-party features compete with or complement them.
- 3M Health Information Systems and Optum. Incumbent medical-coding and revenue-cycle vendors, both with mature LLM-augmented coding products.
- Pharma R&D platforms. Isomorphic Labs, Cradle, Generate Biomedicines, and the in-house teams at the largest pharma companies all use LLM-style sequence models in drug discovery. The product surface is internal R&D, not patient-facing.
The structural feature of the 2026 healthcare LLM market is that the EHR is the integration hub, not the LLM provider. Most clinically-deployed LLM functionality reaches clinicians through Epic, Oracle Cerner, or another EHR vendor's interface. Stand-alone clinical LLM products struggle to achieve scale because they require clinicians to context-switch out of the EHR; products that integrate inside the EHR achieve adoption almost automatically once the workflow is approved. This is why Epic's own generative-AI roadmap and its partnership with Microsoft (Azure OpenAI Service) shape the competitive landscape more than any individual LLM model release.
Cross-References Inside This Book
- Section 70.1 (Healthcare & Biomedical AI), the focused production-pattern section in this chapter.
- Section 53.4 (Privacy & IP), broader privacy framework.
- Section 50.1 (Privacy attacks), membership inference and extraction.
- Chapter 37 (Conversational AI), ambient documentation and patient-facing chat sit on this stack.
- Section 67.4 (Verified RAG), the citation-verification pattern that biomedical literature synthesis adopts.
Canonical External References
- U.S. Food and Drug Administration. Software as a Medical Device (SaMD) landing page, including AI/ML guidance and Predetermined Change Control Plan (PCCP) materials.
- U.S. Department of Health & Human Services. HIPAA for Professionals, the authoritative entry point for Business Associate Agreement requirements that apply to LLM vendors.
- Coalition for Health AI (CHAI). Assurance standards and model cards for responsible health-AI deployment; widely referenced in U.S. hospital RFPs by 2026.
- Microsoft Health Solutions. Dragon Copilot product documentation, the post-acquisition continuation of the Nuance DAX ambient-scribe line.
- Epic Systems. Vendor documentation on EHR-integrated AI agents and generative-AI partnerships.
Who. A multi-state academic-affiliated health system with 28 hospitals, ~25,000 employed clinicians, and a system-wide Epic deployment. Situation. The system's Chief Medical Information Officer evaluated ambient-scribe vendors through late 2024, with shortlist of Abridge, Microsoft Dragon Copilot, and Suki. Problem. Vendor selection had to balance four dimensions: depth of Epic integration (must populate problem list, orders, and patient instructions natively), specialty coverage (the system has 60+ specialties with distinct documentation conventions), data-handling posture (BAA, no training on customer data, configurable retention), and clinician acceptance (the load-bearing rollout risk is clinician adoption rather than technical performance). Decision. The system selected Abridge based on documented depth of Epic integration and published outcome metrics from peer institutions (Mayo, UPMC, Kaiser Permanente). How. A 6-month phased rollout: 200 clinicians in Wave 1 (primary care), 1,000 in Wave 2 (medical specialties), full rollout in Wave 3. Each wave gated on a 30-day post-deployment metrics review (documentation time, note quality scored by a panel, clinician satisfaction). Result. By mid-2026, ~18,000 clinicians active, documentation-time reduction of 38 percent on average across specialties (range 22-54 percent), and burnout-score improvement in the top quartile of published comparators. Lesson. Vendor selection at scale is dominated by EHR-integration depth and published peer outcomes, not by base-model selection; the LLM is a commodity, the integration and the pedagogy of clinician workflow are the load-bearing layers.
The U.S. ambient-documentation market reached roughly $1.2-1.8B in 2025 ARR across the named vendors, with Abridge, Microsoft Dragon Copilot, Suki, and DeepScribe accounting for the bulk. CB Insights, Pitchbook, and KLAS Research place the deployed clinician count at over 250,000 by mid-2026, growing roughly 60-90 percent year-over-year. Funding tracks the adoption: Abridge raised over $200M cumulative through 2024 at a roughly $2.5B valuation; Microsoft's Nuance acquisition (closed 2022) was $19.7B and Dragon Copilot is the post-acquisition continuation.
The medical-coding sub-vertical is more mature and lower-velocity: 3M Health Information Systems plus Optum account for roughly $4-5B in annual revenue, with LLM-augmented coding products typically priced at 5-15 percent of the institution's revenue-cycle spend. Productivity gains in published peer-reviewed studies range 30-50 percent on routine coding work, translating to roughly $50-150 per clinician-day of recovered coder time at typical U.S. health systems.
Patient-facing low-acuity is smaller but growing fast: Hippocratic AI raised $278M through 2024 at a $1.6B valuation, with deployed agents handling roughly 1.5M patient interactions per month by late 2025 across post-discharge follow-up, medication-adherence, and chronic-disease check-in workflows. Across all sub-verticals, the 2026 healthcare-LLM market represents roughly $5-7B in annualized revenue, dominated by ambient documentation and revenue-cycle automation.
- Section 67.5 (Legal LLM Vendors) for the parallel vendor consolidation pattern in the legal vertical.
- Section 68.5 (Finance LLM Vendors) for the BloombergGPT and FinGPT-style finance vendor landscape.
- Section 70.5 (Education LLM Vendors) for the Khanmigo, Magic School, and Anthropic-for-Education-style market structure.
- Chapter 66 (Procurement and Vendor Selection) for the cross-cutting vendor-selection methodology.
- Appendices for the cross-cutting regulatory and procurement reference materials.
Objective
De-identify 100 clinical notes from the publicly released i2b2 2014 de-identification challenge corpus using a HIPAA-eligible LLM (Claude Sonnet 4.7 via AWS Bedrock under a BAA, or an Azure OpenAI deployment under a Microsoft BAA), then measure recall on each of the 18 HIPAA Safe Harbor categories against the i2b2 gold standard. The metric that matters in production is per-category recall on direct identifiers; a single missed MRN or name is what triggers a HIPAA breach notification.
Setup
You need data-use approval for the i2b2 2014 de-identification corpus (Stubbs and Uzuner, 2015, available through the n2c2 portal at n2c2.dbmi.hms.harvard.edu) and access to a HIPAA-compliant LLM endpoint. For development without PHI, the synthetic presidio_synthdata corpus is a substitute that exercises the same pipeline shape.
pip install boto3 presidio-analyzer seqeval pandasSteps
- Define the 18 Safe Harbor categories (names, geographic subdivisions smaller than state, dates, phone numbers, fax, email, SSN, MRN, account numbers, certificate numbers, vehicle identifiers, device identifiers, URLs, IP addresses, biometric identifiers, photographs, full-face images, and the catch-all "any other unique identifying characteristic"). The i2b2 schema maps cleanly onto these.
- Write a system prompt that asks the LLM to return a JSON array of
{start, end, category, text}spans. Constrain with a JSON schema; temperature 0; explicitly forbid the model from rewriting the note. - Run the 100 notes through the LLM and store the predictions. For audit-trail purposes, log the request ID and the response in a write-once log.
- Score with seqeval at the span level, per HIPAA category. Recall is the metric that matters; report precision and F1 too, but optimize for recall.
- Compare to a regex/Presidio baseline. Run Microsoft Presidio over the same 100 notes and look at the recall gap. The interesting finding is usually that the LLM catches contextual identifiers (a patient referred to only as "Mr. Smith's daughter") that the regex baseline misses, while the regex baseline catches structured identifiers (well-formed phone numbers and SSNs) more reliably.
Expected Output
A scoring CSV with per-category recall and precision, plus a confusion matrix showing where the LLM and Presidio disagree. Published de-identification benchmarks on i2b2 with frontier LLMs report recall above 0.95 on names and dates but as low as 0.70 on account numbers and the "other unique identifier" category; that is the gap an internal HIPAA review will ask you to close before deployment.
Extension
Wire the LLM and the Presidio outputs into a union-then-verify pipeline that flags spans where the two systems disagree for human review, and measure the throughput cost; a hybrid pipeline is what most production de-identification systems actually ship.
Research Frontier: Where Healthcare LLMs Are Heading
Clinical-LLM research moved through three distinct phases between 2022 and 2026, and the 2026 frontier is now sharpening around agentic and multimodal clinical reasoning. Med-PaLM and Med-PaLM 2 (Singhal et al., Nature 2023, Nature 620:172-180; arXiv:2305.09617) crossed the USMLE pass threshold and reset expectations for what a generalist LLM can know about medicine. Meditron-70B (Chen et al., 2023, arXiv:2311.16079) demonstrated that open-source pretraining on PubMed and clinical guidelines is competitive with proprietary models on MedQA.
AMIE (Tu et al., DeepMind, 2024, arXiv:2401.05654) is the canonical reference for diagnostic-conversation agents: in a randomized blinded trial, AMIE matched or exceeded primary-care physicians on 24 of 26 conversation-quality axes, with explicit calibration of uncertainty and information-gathering strategy. MedGemini (Saab et al., 2024) extended this to multimodal clinical reasoning over images, text, and structured EHR data; Med-Flamingo (Moor et al., 2023) and RadFM (Wu et al., 2023) target radiology specifically.
Where the field is headed: ambient documentation will saturate as a category and the next investment cycle is going toward clinical-decision-support agents with formal uncertainty quantification, multimodal grounding (image plus text plus longitudinal EHR), and FDA pathways under the new Predetermined Change Control Plan framework. The open research questions are how to validate agents that learn continuously after deployment, how to handle multi-step recommendations that span specialties, and how to translate research benchmarks (MedQA, MultiMedQA) into operational SLOs that hospital governance committees can sign off on.
Show Answer
Show Answer
Show Answer
What Comes Next
Chapter 69 ends here. Section 70.1 is a longer companion piece on healthcare and biomedical AI production patterns. Chapter 70 on education turns to the parallel verticals where regulatory friction is lower but the pedagogical-evidence requirements are unique.
What's Next?
In the next chapter, Chapter 70: Educational Use Cases That Actually Work, we continue building on the material from this chapter.