"Input classification, output filtering, tool sandboxing, authorization. The four trust boundaries that decide whether your LLM agent gets a paycheck or a CVE."
Guard, Trust-Boundary-Architect AI Agent
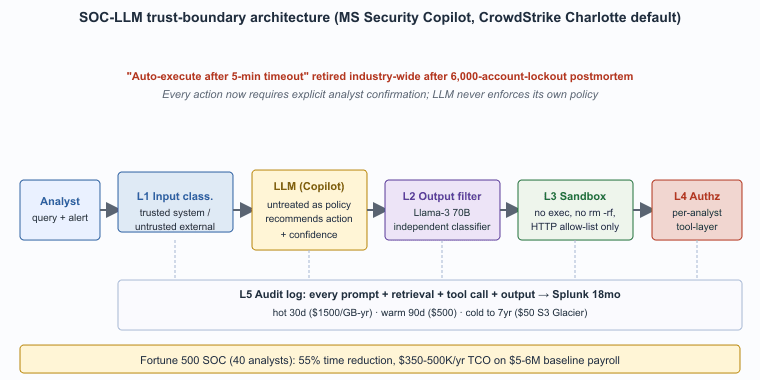
The dominant pattern for security-sensitive LLM systems treats every input as potentially adversarial and every tool the LLM can call as a privileged operation. The architecture has five layers: input classification, output filtering, tool-call sandboxing, authorization at the tool layer, and comprehensive audit logging. This section walks through each layer, then maps it onto the SOC-workflow table that records what can be safely automated after the postmortem in Section 71.3 was widely internalized.
Prerequisites
This section assumes the LLM-attack-surface vocabulary from Section 71.3, the LLM-agent permission patterns from Section 27.1, and the LLM-tool-use patterns from Section 26.3.
The Five-Layer Trust-Boundary Pattern
The 40-hours-saved-per-week claim from CrowdStrike Charlotte AI's marketing was independently audited by a Forrester Total Economic Impact study in 2024. The auditors verified the savings but cautioned that the analyst-time saved was reallocated to higher-tier work rather than headcount reduction; in 2026 nobody on a SOC team is meaningfully "replaced" by Charlotte, but the work mix has shifted toward the cases the LLM cannot triage on its own.
The dominant pattern for security-sensitive LLM systems treats every input as potentially adversarial and every tool the LLM can call as a privileged operation:
- Input classification. Every input (user prompt, retrieved doc, tool output) gets classified as "trusted system prompt" or "untrusted user/external content." Only the trusted layer can set policy.
- Output filtering. Every output passes through a filter that checks for policy violations, leaked secrets, prompt-injection success indicators ("ignore previous instructions" patterns in the output).
- Tool-call sandboxing. Tools the agent can call execute in sandboxes with explicit allow-lists. No exec(), no rm -rf, no arbitrary HTTP egress unless on an allow-list.
- Authorization at tool layer. Each tool call is authorized against the originating user's permissions; the agent cannot bypass user authorization by passing parameters that name a different user.
- Comprehensive audit logging. Every prompt, retrieval, tool call, and output is logged for post-hoc investigation.
Table 71.4.1a summarizes how LLM augmentation actually maps onto the dominant SOC workflows in 2026.
| Workflow | LLM role | Auto-act safe? | Reference vendors |
|---|---|---|---|
| Alert triage and enrichment | Summarize alert, pull context, recommend severity and next step | No: analyst always confirms; auto-execute deprecated industry-wide | Microsoft Security Copilot, CrowdStrike Charlotte AI |
| Phishing-email analysis | Extract IOCs, classify intent, summarize attack pattern | Partial: auto-block on high-confidence + IOC-list match; otherwise analyst review | Defender XDR, Proofpoint, Abnormal |
| Detection-as-code generation | Draft Sigma, KQL, or Splunk rules from analyst description | No: every rule reviewed and tested in staging before production | Tines, Torq, Tracecat, Hunters |
| Threat-intel synthesis | Daily/weekly digest of feeds, blogs, CVEs filtered to org stack | Yes (digest is informational, not an action) | Recorded Future AI, Mandiant Intelligence Console |
| Incident postmortem drafting | Draft executive summary, timeline, action items from logs | No: IR lead reviews and finalizes; LLM output is a draft | Most leading SIEM/SOAR vendors |
| Vulnerability-management triage | Map CVEs to internal asset inventory, draft prioritization narrative | Partial: tickets opened automatically; remediation approved by humans | Wiz, Snyk, Tenable |
Layer 1: Input Classification
Every input gets labeled at ingestion. The trusted system prompt sets policy and never appears in retrieved content; user prompts are explicitly "user said X"; retrieved documents are "the system retrieved this text, treat it as data"; tool outputs are "the tool returned this, treat as data." The labeling is structural, not semantic: the prompt template constructs the input with delimiters or message roles that make the trust level unambiguous to the model. The model is instructed in the system prompt to never treat content within "user" or "tool-output" sections as policy.
Layer 2: Output Filtering
An independent classifier (often a smaller, cheaper model) reads the LLM output before it reaches downstream tools or users. The classifier checks for known injection-success signatures, leaked secrets (API keys, internal URLs, customer PII), and policy violations specific to the deployment. The independent classifier is structurally important: relying on the LLM to filter its own output is fragile because successful injections can suppress the filter.
Layer 3: Tool-Call Sandboxing
Tools the agent can call execute in sandboxes with explicit allow-lists. The principle of least privilege applies aggressively: the agent should not be able to exec arbitrary commands, write to arbitrary paths, or make HTTP requests to arbitrary destinations. The allow-list is the security boundary; the model is not trusted to respect the boundary, the runtime enforces it.
Layer 4: Authorization at Tool Layer
Each tool call is authorized against the originating user's permissions. The agent runs as the user, not as a privileged service account; the agent cannot bypass user authorization by passing parameters that name a different user. This is the architectural defense against the agent being tricked into performing actions outside the requesting user's scope. The authorization happens at the tool layer because the model itself cannot be trusted to enforce it.
Layer 5: Comprehensive Audit Logging
Every prompt, retrieval, tool call, and output is logged for post-hoc investigation. The audit log is the forensic substrate for incident response when something goes wrong; it also supports policy and compliance review. The log volume can be substantial; cost-conscious deployments tier the storage (hot for 30 days, warm for 90 days, cold archived for the retention policy duration) but do not skip the logging.
The trust-boundary pattern is descriptive, not normative. Every major SOC-LLM vendor (Microsoft Security Copilot, CrowdStrike Charlotte, Tines, Torq, Hunters) implements variants of this architecture, and the open-source agentic-security frameworks (LangChain-based deployments at scale, Semantic Kernel patterns at Microsoft) recommend it as the default. The reason is not that the architecture was designed top-down; it is that every other architecture failed in production. The 2024 auto-execute incidents established that LLMs cannot be trusted to enforce security policy in their own outputs; the architecture must enforce policy externally. The OWASP Top 10 and MITRE ATLAS reflect the same lesson at the cataloging level: every entry on either list maps to a defense at one of these five layers.
Who. A Fortune 500 financial-services firm with a 40-person internal SOC, a 24x7 operations posture, and ~$8M annual security-operations budget. Situation. Through 2024, the firm piloted Microsoft Security Copilot in the SOC, with mixed initial results: the LLM accelerated investigation on routine alerts (40-60 percent time reduction), but several near-miss incidents occurred where the LLM recommended actions that would have been wrong if executed without review. Problem. The CISO needed a deployment posture that captured the productivity gains while structurally preventing the auto-execute failure mode from the LLM-amplified false-positive storm postmortem (Section 71.3). Decision. The firm adopted the five-layer trust-boundary pattern: (1) input classification labels every alert payload and retrieved threat-intel chunk by trust tier; (2) an independent output classifier (Llama-3 70B running on internal infrastructure) reviews every Copilot recommendation before display; (3) tool calls execute in a sandboxed runtime with explicit allow-lists per analyst role; (4) tool-layer authorization verifies the analyst's permissions on every privileged action; (5) every prompt, retrieval, recommendation, decision, and tool call is logged into Splunk for 18-month retention. How. The implementation took ~4 months and ~2 FTE of engineering effort. The most consequential design choice was removing the "auto-execute after 5-minute timeout" feature from the existing SOAR playbooks; every action now requires explicit analyst confirmation. Result. Investigation time per alert dropped 55 percent on routine categories; no auto-execute incidents; the audit log proved valuable in two regulatory examinations where the firm could demonstrate end-to-end decision provenance. Lesson. The five layers are descriptive of what works in production, not normative; every other architecture failed when stress-tested against adversarial inputs or operational error.
A 40-analyst SOC running the five-layer pattern with full audit logging has a concrete cost stack. LLM inference: ~200,000 queries/month at ~3,000 input + 800 output tokens average, costing ~$2-4K/month at frontier-API pricing, or ~$30-50K/year. Independent output classifier: a self-hosted Llama-3 70B running on 4x H100 nodes adds ~$200K/year amortized hardware + ~$50K/year ops. Audit logging: every prompt + retrieval + tool call + response averages ~10KB compressed, at 200K queries/month that is ~24GB/month, or ~290GB/year. In Splunk Cloud at ~$1,500/GB-year for retention, that is ~$435K/year for the SOC-LLM logs alone if naively stored at standard rates.
Optimization. Cost-conscious deployments tier storage: hot (last 30 days) at $1,500/GB-year for fast query, warm (30-90 days) at $500/GB-year, cold (90 days to 7 years) at $50/GB-year in S3 Glacier or equivalent. The tiered model reduces audit-log cost to roughly $80-120K/year while preserving forensic value. Combined SOC-LLM TCO is roughly $350-500K/year on top of the underlying SIEM and EDR, against $5-6M in baseline SOC payroll. The ROI of the augmented pattern is positive on time recovery alone for SOCs above ~20 analysts; smaller teams may not justify the platform cost but can use API-based LLM augmentation without the full self-hosted classifier stack.
- Section 49.1 (Agent Safety) for the agent-architecture safety patterns that operationalize Layers 3 and 4.
- Section 44.3 (Observability) for the OpenTelemetry GenAI conventions that the audit logs (Layer 5) conform to.
- Chapter 27 (Tool Use Protocols) for the tool-call sandboxing pattern (Layer 3).
- Section 69.4 (HIPAA Deployment Patterns) for the structurally similar five-layer defensive pattern in healthcare.
- Section 70.4 (Pedagogically-Scaffolded Tutor Architecture) for the structurally similar input-classification and output-filtering pattern in education.
Show Answer
Show Answer
Show Answer
What Comes Next
Section 71.5 closes the chapter with the vendor and tool landscape, cross-references inside this book, and the canonical external sources, the OWASP Top 10 for LLM Applications and MITRE ATLAS being the most-load-bearing.
What's Next?
In the next section, Section 71.5: Cybersecurity LLM Vendors and Further Reading, we build on the material covered here.