"The frontier moves faster than peer review. The platforms that win are the ones that ship the same week the paper does."
Frontier, Pre-Print-Platform-Reader AI Agent
- Distinguish preprint servers, curated venues, lab publication channels, and live-tracking dashboards by their selection rigor and recency tradeoff.
- Pick the right venue for "I just need to know what shipped this week" versus "I need the definitive paper on X".
- Build a sustainable paper-tracking habit that survives the next decade of platform churn.
The frontier moves faster than peer review. The 2026 paper-discovery stack is therefore an order-of-rigor stack: arXiv first (recency), Hugging Face Papers and Papers with Code (curation), OpenReview (peer review), lab channels (authoritative), and live dashboards for the latest model and benchmark snapshots. Knowing which layer to consult for which question is most of what "staying current" means in practice.
Prerequisites
This section assumes the LLM-API platform vocabulary from Section 14.1 and the frontier-benchmark vocabulary from Section 77.1.
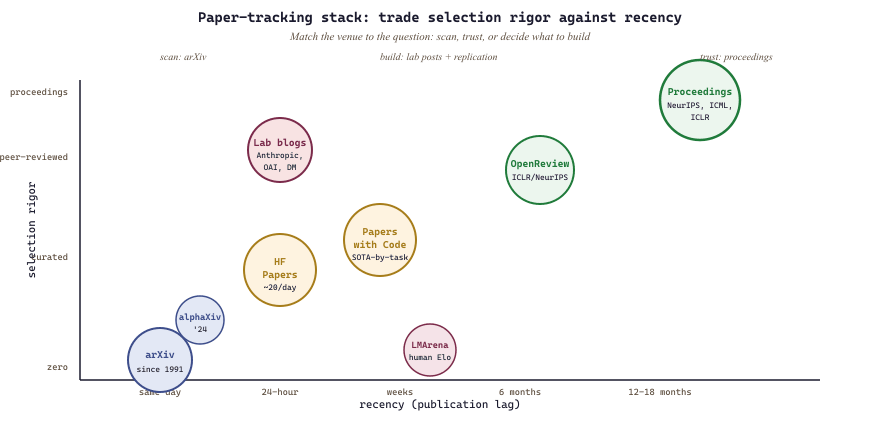
Every venue trades the two. arXiv has zero selection and same-day recency. Hugging Face Papers selects the daily 10-20 most-cited posts but with a 24-hour lag. OpenReview adds peer review with a 6-month lag. NeurIPS / ICLR / ICML proceedings add publication with a 12-18 month lag. Lab blog posts (Anthropic, OpenAI, DeepMind) are zero-lag but the selection is "what does the lab want to communicate this week", not "what is most important to know". The right move is to consult the most-recent venue with sufficient selection for your question: scanning the field uses arXiv; trusting a result uses peer-reviewed proceedings; deciding what to build uses lab posts plus your own replication.
78.1.1 Preprint servers
- arXiv (Cornell, 1991) is the preprint server where almost all LLM and ML research lands first, often months before formal publication. Its objective is to be a free, instant, open repository for scientific manuscripts, which matters because the field moves faster than peer review and arXiv is where conversations actually happen. The core concept is moderated-but-not-peer-reviewed posting with versioned papers (v1, v2, ...) plus citable arXiv IDs. Pick arXiv as your daily read; treat the absence of peer review by checking that results replicate before betting on them.
- Semantic Scholar (AllenAI, 2015) is the AI-driven citation-graph navigation engine for academic papers. Its objective is to make "find related work" and "find papers citing X" fast across the entire scientific literature, which matters when arXiv's flat search misses connections. The core concept is paper-level embeddings and citation context analysis. Pick Semantic Scholar for citation-graph exploration; for raw paper search, arXiv's keyword search is faster.
- bioRxiv (CSHL, 2013) and medRxiv (CSHL + Yale, 2019) are the biological- and medical-sciences preprint servers, analogous to arXiv for their domains. Their objective is to bring open-preprint culture to biology and medicine, which matters when AI-applied-to-bio research happens at the intersection. Pick bioRxiv / medRxiv for AI-in-bio or AI-in-medicine work; most pure-ML papers still go to arXiv.
- OpenReview (UMass + Google, 2013) is the open peer-review platform hosting ICLR, NeurIPS, AAAI, COLM, and other venue's review processes in public. Its objective is to make peer review transparent and citable, which matters because closed-review feedback dies with the reviewer. The core concept is openly-published reviewer comments, author responses, and editor decisions on each submission. Pick OpenReview for tracking what the community actually thinks of a paper, beyond its abstract claims.
78.1.2 Curated paper venues
- Hugging Face Papers (Hugging Face, 2023) is the daily curated digest of arXiv ML papers with one-click access to model and dataset companions. Its objective is to filter the firehose of daily arXiv ML posts down to the 10-20 most-discussed, which matters because reading arXiv-cs.CL raw is impossible for any human. The core concept is community-upvoted papers with linked Hub artifacts. Pick HF Papers for the morning ML reading; pair with paper-author social media for the breaking-news layer.
- Papers with Code (Meta, 2018) is the benchmark-linked paper index that connects every paper to its leaderboard contribution. Its objective is to make "find SOTA for task X" a one-click query, which matters when you want to know the current best result without reading every recent paper. The core concept is the benchmark-task graph: tasks, datasets, methods, papers, and their leaderboard positions. Pick Papers with Code when you need state-of-the-art-by-benchmark; for current research conversations, HF Papers is fresher.
- alphaXiv (Stanford, 2024) is the discussion-thread overlay on arXiv, letting authors and readers annotate and discuss papers in public. Its objective is to make paper discussions citable and persistent rather than scattered across Twitter and Slack, which matters when the conversation around a paper is often more useful than the paper itself. Pick alphaXiv for finding community criticism, replications, and follow-up of important arXiv papers.
78.1.3 Lab publication channels
- Anthropic research and Transformer Circuits.
- OpenAI research.
- Google DeepMind research.
- EleutherAI publications.
- Nous Research.
- Stability AI news.
78.1.4 Live tracking
- LMArena: human Elo leaderboard.
- Artificial Analysis: model dashboards.
- frontier-evals.ai: aggregated frontier-eval scores.
- The 2026 paper-tracking stack runs from arXiv (zero selection, same-day) to peer-reviewed proceedings (high selection, 12-18 month lag).
- Match venue rigor to your question: scan with arXiv, trust with proceedings, decide what to build with lab posts and replication.
- Live dashboards (LMArena, Artificial Analysis) replace vendor press releases for cross-silicon and cross-model comparisons.
What's Next?
In the next section, Section 78.2: Libraries & Frameworks, we build on the material covered here.