"The reasoning-first tier (o3, Claude with extended thinking, Gemini 2.5 Pro). The cost-first tier (Haiku, Mini, Flash). The open-weights tier (Llama, Qwen, DeepSeek). Each tier is a deployment thesis."
Frontier, Frontier-Model-Reader AI Agent
- Distinguish reasoning-first, long-context, multimodal, and open-weight frontier models by access mode and target workload.
- Track an open-source project's traction signal without falling for the "GitHub stars" vanity metric.
- Pick which frontier model to evaluate for a given product-development question.
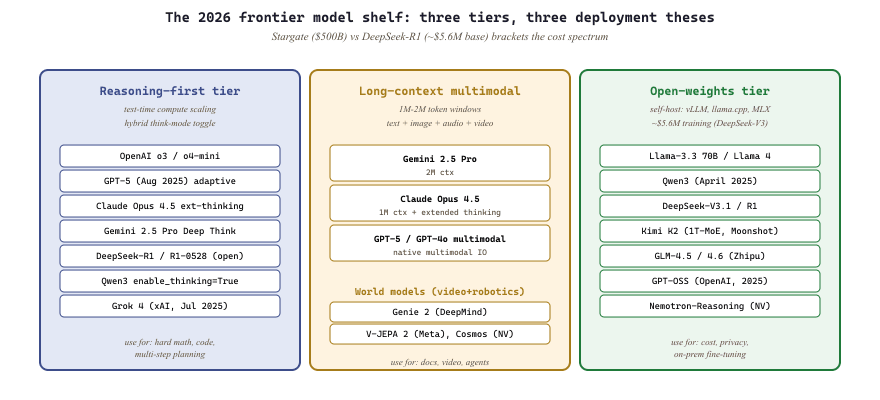
The 2025-26 model shelf has three tiers: reasoning-first (o3 and o4-mini, Claude Opus 4.5 with extended thinking, Gemini 2.5 Pro with Deep Think, DeepSeek-R1 and R1-0528, the GPT-5 family's adaptive thinking), long-context multimodal (Gemini 2.5 Pro, Claude Opus 4.5, GPT-5), and open-weights (Llama-3.3 70B / Llama 4 family, Qwen3, DeepSeek-V3.1, Kimi K2, GLM-4.6). Knowing what each tier exists for, and the open-source projects (vLLM, llama.cpp, MLX) that ship them, is most of model selection.
Prerequisites
This section assumes the LLM model-zoo vocabulary from Section 14.4 and the open-weights LLM landscape from Section 10.10.
78.4.1 Reasoning-first models
- OpenAI o3 / o4-mini / GPT-5 (Aug 2025): dedicated reasoning models with test-time compute scaling, plus GPT-5's adaptive "think harder" tier.
- Claude Opus 4.5 / Sonnet 4.5 (Anthropic, 2025) with extended thinking. Claude 4 family launched May 2025.
- Gemini 2.5 Pro with Deep Think (March 2025).
- DeepSeek-R1 and R1-0528, DeepSeek-V3.1 (2025): the open reasoning frontier.
- Qwen3 (April 2025) with the
enable_thinking=Truehybrid-reasoning toggle. The older QwQ-32B-Preview (Dec 2024) is now superseded by Qwen3. - Grok 4 (xAI, July 2025): late frontier entrant.
- NVIDIA Nemotron-Reasoning (2025): a relevant frontier reasoning release.
- Step-1 / Step-2 (StepFun, 2025): Chinese reasoning models worth tracking.
The single most important pattern across the 2025-26 frontier is the unification of "fast" and "thinking" modes under one model. Qwen3 exposes enable_thinking=True on the chat template; Claude 3.7+ and Claude 4 ship extended thinking; GPT-5 routes adaptively via an internal think-or-answer gate; Gemini 2.5 Pro adds Deep Think. This is the architectural convergence that makes 2025-26 distinct from 2024. The GRPO recipe from DeepSeek-R1 (2025) is the open recipe behind much of this; see also Section 19.6 for the foundational papers.
78.4.1.5 World models for video and robotics
The 2025 frontier expansion that is not text-only: world models for video and robotics. Genie 2 (DeepMind), V-JEPA 2 (Meta), and Cosmos (NVIDIA, 2025) together represent the world-model frontier: models that learn the dynamics of physical environments well enough to plan in them. These are not text models with vision tacked on; they are foundation models for video and robotics directly.
78.4.2 Long-context and multimodal frontier
- Gemini 2.5 Pro: 2M-token context.
- Claude Opus 4.5: 1M context.
- GPT-4o / GPT-5 with multimodal IO.
78.4.3 Open-weights frontier
- Llama-3.3 70B (Dec 2024), Llama 4 family (Scout / Maverick / Behemoth, 2025-Q2), Qwen3 (April 2025), DeepSeek-V3.1 / R1 / R1-0528 (Jan-mid 2025), Kimi K2 (Moonshot, 2025, 1T-MoE), GLM-4.5 / GLM-4.6 (Zhipu, 2025), GPT-OSS (OpenAI's first open-weights release in years, 2025) (covered in Chapter 12). These remain the open shelf in 2026.
The January 2025 Stargate announcement (a $500B infrastructure commitment from OpenAI / SoftBank / Oracle for US data centers over five years) is the economic anchor for the "frontier requires capital" thesis. Paired with the DeepSeek-R1 disclosure of ~$5.6M for V3-base training a few weeks earlier, the two numbers bracket the 2025 cost spectrum: ten thousand times more capital separates the closed-frontier path from the open-recipe path. Treat both numbers as ground truth for any "how much does the frontier cost" discussion through 2026.
78.4.4 Comparing the frontier models
| Model | Released | Frontier on | Access | Notes |
|---|---|---|---|---|
| OpenAI o3 / o4-mini | 2024-25 | Hard reasoning | API | Test-time compute model |
| GPT-5 family | Aug 2025 | Generalist + adaptive reasoning | API | Internal think-or-answer gate |
| Claude Opus 4.5 | 2025 | SWE-bench, long-context coding | API | Extended thinking mode |
| Gemini 2.5 Pro | March 2025 | Multimodal, 2M context, Deep Think | API | Largest context window |
| Grok 4 | July 2025 | Real-time web search | API | xAI |
| DeepSeek-R1 | Jan 2025 | Open reasoning | Open weights (MIT) | GRPO recipe; the open-replication anchor |
| Qwen3-235B | April 2025 | Multilingual MoE, hybrid reasoning | Open weights (Apache 2.0) | enable_thinking toggle |
| Kimi K2 | 2025 | Open-weight scale (1T MoE) | Open weights | 32B active |
| Llama 4 family | 2025-Q2 | Open frontier | Open weights (LCL) | Scout / Maverick / Behemoth |
The most important capability change of 2024-2026 was the shift from "predict the next token" models to test-time-compute / reasoning models. The cost-per-task economics changed substantially: more tokens per task, but higher success on the hardest tasks. Whether this trend extends or saturates is the open research question Part XII discusses.
vLLM started as a Berkeley research project (PagedAttention paper, June 2023). Through 2024 it was the open-source serving library, growing steadily. In Q1-Q2 2025 it crossed an inflection: enterprise adoption (Anyscale, Databricks, NVIDIA Triton) brought engineering resources, the project shipped FP8 / FP4 quantization paths, multi-LoRA serving, speculative decoding (Medusa/EAGLE), and disaggregated prefill/decode. GitHub stars went from ~25k in early 2025 to ~50k by mid-2026, but the more meaningful signal was that the top-five LLM-hosting companies all standardized on vLLM as their default open-weight serving stack. By Q1 2026 vLLM had surpassed TGI (Hugging Face's serving library) as the open-source production default. The lesson: a project's value is the layer of infrastructure that uses it, not its star count. The vLLM repo and the vLLM blog document the trajectory.
Stars correlate with awareness, not with adoption or quality. Many high-star repos (15-30k stars) are research demos with no production users; many production-critical infrastructure projects (vLLM in early 2024, SGLang in 2025) had relatively modest star counts while running serving for major labs. The better signals: (1) named enterprise users with case studies; (2) the rate of commits in the last 90 days; (3) issue-resolution time; (4) presence in adjacent production stacks (NVIDIA Triton, AWS Bedrock, etc.). Treat stars as a noisy proxy at best.
- The 2026 model shelf splits cleanly: reasoning-first, long-context multimodal, and open-weights.
- Reasoning-first models trade more tokens per task for higher success on the hardest tasks.
- vLLM's 2025 inflection from research project to default open-source production serving illustrates the difference between awareness (stars) and adoption (named users).
What's Next?
In the next section, Section 78.5: External Reading & Communities, we build on the material covered here.