"A quantized model is still the same model, just one that learned to mumble. The trick is making sure it mumbles the right answer."
Quant, Bit-Whisperer AI Agent
The 2026 model zoo splits cleanly into three layers. The first is the closed-API frontier: the GPT-5 family (Aug 2025), the Claude 4 family (Opus 4.5 / Sonnet 4.5 / Haiku 4.5, 2025), and Gemini 2.5 Pro and its 2025-26 successors. You can call them but never run them. The second is the open-weight frontier: Llama-3.3 and the Llama 4 family (Scout / Maverick / Behemoth previewed in 2025), Qwen3, DeepSeek-V3 / R1 / V3.1, Kimi K2, GLM-4.5, GPT-OSS, and the Mistral families. You can download them and run them anywhere your hardware allows. The third is the small open-weight tier: Pythia, SmolLM2, TinyLlama, Phi-4. You can fine-tune and inspect them on a laptop. Each layer is useful for different reasons; this section catalogues all three.
The frontier is moving fast: a model that was unbeatable in January 2026 is likely a midrange option by December. The list below names the families that mattered as of the book's print date and the URLs that will keep tracking the leaderboards as the line moves.
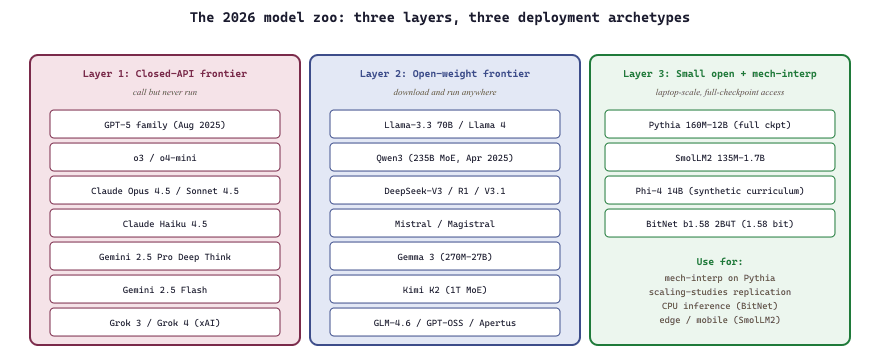
10.10.1 The closed-API frontier
The first GPT paper had no name on the model card, no system prompt, no chat interface, and zero users. By the time GPT-5 shipped, OpenAI was running a model lineup so dense (GPT-4o, 4.5, 5, o3, o4-mini) that engineers maintained internal spreadsheets just to remember which one to call for which task. The lesson is that frontier "models" are now product lines, and the leaderboard you're reading was probably already out of date by the time the print run hit the warehouse.
- GPT-4o through the GPT-5 family (OpenAI): GPT-4o introduced multimodal "omni" inputs (May 2024); GPT-4.5 "Orion" (Feb 2025); GPT-5 (Aug 2025) ships the reasoning-mode chain-of-thought as a built-in adaptive feature; o3 and o4-mini cover the cost-efficient reasoning tier. Model card index.
- Claude 3.5 Sonnet through the Claude 4 family (Anthropic): Claude 3.7 Sonnet (Feb 2025) introduced extended-thinking; Claude Opus 4 / Sonnet 4 / Haiku 4 launched May 2025, followed by Opus 4.5 / Sonnet 4.5 / Haiku 4.5 later in 2025. Strong long-context (200K tokens default, 1M extended), agentic-task leadership through 2025-26. Claude models doc.
- Gemini 2.5 Pro (March 2025, with Deep Think mode) and Gemini 2.5 Flash (Google DeepMind): multimodal-by-default; 1M-token context the default, 2M as a preview tier. Top of the long-context leaderboards as of mid-2025.
- Grok 3 (Feb 2025) and Grok 4 (July 2025) (xAI): late entrants to the frontier; native real-time web access.
10.10.2 The open-weight frontier
- Llama-3.3 70B (Dec 2024) and the Llama 4 family (Scout, Maverick, Behemoth previewed in 2025) (Meta); Llama Community License. The most-fine-tuned open family by a wide margin.
- Qwen3 (Alibaba, April 2025): 0.5B to 235B parameters; Apache 2.0 for most sizes. The 235B MoE has 128 experts and a hybrid-reasoning
enable_thinking=Truetoggle. Task-specific variants Qwen3-Coder and Qwen3-Math ship alongside. - DeepSeek-V3 (Dec 2024) and DeepSeek-R1 (Jan 2025), DeepSeek-V3.1 (2025): 671B MoE; MIT-licensed weights; Multi-head Latent Attention (MLA); the most-replicated open reasoning recipe of 2025. R1 introduced GRPO-driven reasoning that the open community has since adopted as the standard recipe.
- Mistral / Mixtral / Magistral (Mistral AI): 7B dense, 8x7B / 8x22B MoE, Mistral Large 2, Magistral (the 2025 reasoning line). Apache 2.0 for most open weights.
- Gemma 3 (Google): 270M, 2B, 9B, 27B; Gemma license. Edge-friendly sizes, multimodal vision support in Gemma 3.
- GPT-OSS (OpenAI, 2025): OpenAI's first open-weights release in years; relevant as a public reference for the GPT post-training stack.
- Kimi K2 (Moonshot, 2025): 1T parameter MoE with 32B active; one of the largest open-weight releases of 2025.
- GLM-4.5 / GLM-4.6 (Zhipu, 2025): a major Chinese open-weight family alongside Qwen3 and DeepSeek.
- Apertus (Swiss AI, 2025-Q4): fully open multilingual European-trained model; the right open base for multilingual research.
10.10.3 The mech-interp and small-open tier
- Pythia (EleutherAI, 160M to 12B): full intermediate checkpoints, fully reproducible recipe. The canonical scaling-studies and mech-interp checkpoint family.
- SmolLM2 (Hugging Face, 135M / 360M / 1.7B): trained on FineWeb-Edu; the best-in-class very-small open model of 2025.
- Phi-4 (Microsoft, 14B): small dense, trained on synthetic curriculum; strong reasoning per parameter.
- BitNet b1.58 2B4T: native 1.58-bit weights, first open-source 1-bit model at 2B scale. Inferable on CPU via bitnet.cpp.
10.10.4 Comparing the frontier model families
| Family | Top variant (mid-2026) | Access | Context | Approx $/1M in (USD) | Strength |
|---|---|---|---|---|---|
| OpenAI GPT | GPT-5 family / o3 | API only | 200K-1M | $2.50-$15 input, more for thinking tokens | Reasoning, code, multimodal |
| Anthropic Claude | Claude Opus 4.5 | API only | 200K-1M | $15 input / $75 output (Opus); cheaper for Sonnet / Haiku | Agentic, long-form writing |
| Google Gemini | Gemini 2.5 Pro | API only | 1M-2M | $1.25-$10 input | Multimodal, long-context |
| Meta Llama | Llama 4 family | Open weights (LCL) | 128K-1M+ | $0 (self-host); $0.50-$3 via providers | Most-fine-tuned base |
| Alibaba Qwen | Qwen3-235B | Open weights (Apache 2.0) | 128K-1M | $0 (self-host); $0.30-$2 via providers | Multilingual, MoE, hybrid reasoning |
| DeepSeek | DeepSeek-V3.1 / R1 | Open weights (MIT) | 128K | $0 (self-host); $0.14-$1.10 via DeepSeek API | Cost-efficient reasoning frontier |
The defining architectural trend of 2025 is the unification of "fast" and "thinking" modes under a single model. Qwen3 exposes enable_thinking=True on the chat template; Claude 3.7+ and Claude 4 ship an extended-thinking parameter; GPT-5 ships an adaptive "think harder" tier where the model chooses how long to reason per query; Gemini 2.5 Pro adds Deep Think. The practical consequence: prompting in 2026 means deciding whether to let the model think, not just what to ask. Thinking tokens cost more (sometimes 3-5x the completion-token price on closed APIs) and add latency. Default to thinking off for retrieval and summarization; default to thinking on for math, code, and multi-step planning.
You cannot inspect, fine-tune, or quantize a closed-API model. You can only call it. Every meaningful technique in Chapters 8 through 11 (mech-interp, activation patching, embedding inspection, attention visualization) requires weights you control. The frontier closed-API models are the right tools for production in Part III; the open-weight families are the right tools for understanding here.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
# 4-bit quantized, fits on 24 GB. The bare load_in_4bit=True flag is
# deprecated as of transformers 4.x late 2024; use BitsAndBytesConfig.
bnb = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model_id = "meta-llama/Llama-3.3-70B-Instruct"
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id, quantization_config=bnb, device_map="auto"
)
# Same pattern, different family:
# model_id = "Qwen/Qwen3-7B-Instruct"
# model_id = "deepseek-ai/DeepSeek-V3.1"The AutoModelForCausalLM abstraction is what makes all three loadable with the same five lines. Behind it, transformers picks the right model class (LlamaForCausalLM, Qwen3ForCausalLM, DeepseekV3ForCausalLM) automatically.
10.10.5 Picking a default for Chapter exercises
For Chapters 7 to 11: Qwen3-7B-Instruct (open weight, Apache 2.0, fits in 24 GB at 4-bit) is the recommended default base. For mech-interp work in Chapter 10: Pythia-160M or Pythia-1.4B (small enough to load fully into TransformerLens, full intermediate checkpoints available). For "what does a frontier model do" comparisons: call the current GPT-5 family / Claude Opus 4.5 / Gemini 2.5 Pro through their APIs.
The Jan 2025 release of DeepSeek-R1 (671B MoE, MIT-licensed) plus the GRPO training recipe is the most-replicated open recipe of 2025. The disclosed V3 base training cost (~$5.6M) and the R1-Zero "RL from verifiable rewards" pipeline together set a new floor for what an open team can reproduce. Every reasoning-fine-tuned open model since (Sky-T1, Open-R1, Bespoke-Stratos) traces its lineage to this release. The headline lesson for Part II: an open team published a frontier-grade reasoning model and the entire training recipe within the same week.
Quantization for Serving
This section is a practical companion to the quantization theory in Chapter 10. It focuses on the serving-specific workflow: how to load pre-quantized models in vLLM, TGI, and SGLang; how to convert models to GGUF for llama.cpp; and how to choose the right format for your deployment target.
Prerequisites
This section assumes the quantization formats covered in Section 10.1 through Section 10.3 and the inference-stack platforms in Section 10.6. The open-versus-closed licensing landscape is revisited later in the book.
For the mathematics of quantization (absmax, zero-point, per-group schemes), the algorithms behind GPTQ, AWQ, and bitsandbytes, calibration strategies, quality degradation analysis, and hands-on quantization labs, see Section 9.1: Model Quantization. This section assumes you have already quantized your model (or downloaded a pre-quantized checkpoint) and focuses on loading and serving it.
1. Serving GPTQ and AWQ Models
Both vLLM and TGI natively support GPTQ models. Point the server at a GPTQ-quantized model and specify the quantization format.

The GPTQ update rule that drives the column-by-column loop above is:
Here $H = X^{T} X$ is the Hessian of the layer's squared error against calibration activations $X$. The first term rounds the current column, the second redistributes the rounding error onto remaining columns to keep the layer's output close to the FP16 reference. AWQ's complementary objective, in contrast, picks the scale that minimizes the activation-weighted quantization error:
The activation-weighting is what makes AWQ "activation-aware": channels that consistently produce large $x$ get larger $s$, hence more of the 4-bit dynamic range.
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
# End-to-end GPTQ quantization of Llama-3.1-8B to 4 bits with C4 calibration.
# AutoGPTQ runs the per-column Hessian compensation; transformers wraps the loop.
model_id = "meta-llama/Llama-3.1-8B-Instruct"
tok = AutoTokenizer.from_pretrained(model_id)
gptq_cfg = GPTQConfig(
bits=4, # target precision
group_size=128, # per-128-weight scale, standard sweet spot
desc_act=True, # process columns in activation order for quality
dataset="c4", # 128 samples of WebText-style English by default
tokenizer=tok,
)
# This call triggers the actual quantization (~10-30 min on a single A100).
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=gptq_cfg,
device_map="auto",
)
model.save_pretrained("./llama-3.1-8b-gptq-int4")
tok.save_pretrained("./llama-3.1-8b-gptq-int4")
# The saved directory now contains INT4 weights + FP16 scales + zero-points,
# ~5.5 GB total (vs ~16 GB FP16). vLLM / TGI can load it directly:
# vllm serve ./llama-3.1-8b-gptq-int4 --quantization gptqCode Fragment 10.10.2: Quantizing Llama-3.1-8B to 4 bits with AutoGPTQ via Hugging Face Transformers. The desc_act=True flag processes columns in descending order of activation magnitude, which lets the Hessian compensation absorb more error in the earlier-quantized columns. The result is a single self-contained checkpoint that vLLM, TGI, and SGLang can serve with a one-flag change.
A side-by-side run on a single A100, calibration = 128 C4 samples, generation = greedy, batch = 1:
- FP16 baseline: 6.14 perplexity, 42.3 tokens/sec, 16.1 GB VRAM.
- GPTQ 4-bit (group 128, desc_act): 6.41 perplexity (+0.27, +4.4%), 95.7 tokens/sec (+126% throughput), 4.8 GB VRAM (3.4x smaller).
- AWQ 4-bit (GEMM kernel): 6.38 perplexity (+0.24, +3.9%), 102.3 tokens/sec (+142% throughput), 4.5 GB VRAM (3.6x smaller).
For a 70B model the same recipes typically lose less than 2% perplexity at 4-bit; the quality gap shrinks with scale because larger models have more redundancy to absorb the quantization noise. The throughput win comes from cutting weight-memory traffic by 4x; LLM decode is memory-bandwidth-bound (see Section 9.3), so 4x fewer bytes to read translates directly into roughly 2x more tokens per second.
# Serve a GPTQ model with vLLM
vllm serve TheBloke/Llama-2-70B-Chat-GPTQ \
--quantization gptq \
--tensor-parallel-size 2 \
--max-model-len 4096
# Serve a GPTQ model with TGI
docker run --gpus all --shm-size 1g -p 8080:80 \
-v /data:/data \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id TheBloke/Llama-2-70B-Chat-GPTQ \
--quantize gptqAWQ with the GEMM kernel version is generally recommended for serving scenarios where batch sizes exceed 1. The GEMV version is optimized for single-request (batch size 1) latency. If your workload mixes both, GEMM is the safer default. See Section 9.1 for the full AWQ quantization procedure.
2. GGUF and llama.cpp: CPU-Friendly Serving
GGUF (GPT-Generated Unified Format) is the file format used by llama.cpp, the popular C/C++ inference engine that runs LLMs on CPUs, Apple Silicon, and consumer GPUs. Unlike GPTQ and AWQ, which target NVIDIA GPUs and CUDA kernels, GGUF is designed for portability. It supports a wide range of quantization levels and can split computation between CPU and GPU.
GGUF supports quantization types ranging from Q2_K (roughly 2.5 bits per weight) to Q8_0 (8 bits per weight). The naming convention indicates the bit width and the quantization scheme. The most commonly used levels for serving are Q4_K_M and Q5_K_M, which balance quality and size.
| GGUF Type | Bits/Weight | Model Size (7B) | Quality Impact |
|---|---|---|---|
| Q2_K | ~2.5 | ~2.8 GB | Noticeable degradation; useful for experimentation only |
| Q3_K_M | ~3.5 | ~3.5 GB | Moderate degradation; acceptable for simple tasks |
| Q4_K_M | ~4.5 | ~4.4 GB | Minimal degradation; recommended for most use cases |
| Q5_K_M | ~5.5 | ~5.1 GB | Near-lossless; best quality-to-size ratio |
| Q6_K | ~6.5 | ~5.9 GB | Very close to FP16 quality |
| Q8_0 | 8.0 | ~7.2 GB | Virtually lossless |
To convert a Hugging Face model to GGUF format, use the conversion script included with llama.cpp.
# Clone llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# Build (with CUDA support for GPU offloading)
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
# Convert a HuggingFace model to GGUF
python convert_hf_to_gguf.py \
/path/to/meta-llama/Llama-3.1-8B-Instruct \
--outfile llama-3.1-8b.gguf \
--outtype f16
# Quantize to Q4_K_M
./build/bin/llama-quantize llama-3.1-8b.gguf llama-3.1-8b-Q4_K_M.gguf Q4_K_M2.1 Running a GGUF Server
llama.cpp includes a built-in HTTP server with an OpenAI-compatible API. This makes it a viable serving option for environments without NVIDIA GPUs.
# Start the llama.cpp server with GPU offloading
./build/bin/llama-server \
-m llama-3.1-8b-Q4_K_M.gguf \
--host 0.0.0.0 \
--port 8080 \
-ngl 99 \
-c 4096 \
--threads 8
The -ngl 99 flag offloads all layers to GPU. On systems without a GPU, omit this flag
and llama.cpp will run entirely on CPU, using SIMD optimizations (AVX2, AVX-512, ARM NEON) for
acceptable performance on modern processors.
3. bitsandbytes for Serving
For the bitsandbytes NF4 data type, double quantization, and complete code examples, see Section 9.1: Model Quantization (subsection 5).
TGI supports bitsandbytes quantization at startup with --quantize bitsandbytes-nf4,
quantizing on the fly without a pre-quantized checkpoint. This is convenient for prototyping but
produces 30% to 50% lower throughput than pre-quantized GPTQ or AWQ models due to the lack of
optimized CUDA kernels. For production serving, prefer GPTQ or AWQ.
4. Comparison: Choosing the Right Format for Serving
The choice of quantization method depends on your deployment environment, performance requirements, and workflow. The following table provides a side-by-side comparison.
| Aspect | GPTQ | AWQ | GGUF | bitsandbytes |
|---|---|---|---|---|
| Precision | 4-bit, 8-bit | 4-bit | 2-bit to 8-bit | 4-bit, 8-bit |
| Calibration required | Yes (128+ samples) | Yes (small dataset) | No | No |
| Quantization speed (Sec 9.1.2) | Slow (hours for 70B) | Moderate (30-60 min) | Fast (minutes) | Instant (on load) |
| Serving engines | vLLM, TGI, SGLang | vLLM, TGI, SGLang | llama.cpp, Ollama | TGI, HF Transformers |
| Hardware | NVIDIA GPU only | NVIDIA GPU only | CPU, Apple Silicon, GPU | NVIDIA GPU only |
| Throughput | High | High | Moderate (GPU), Low (CPU) | Moderate |
| Quality (4-bit) | Very good | Very good | Good (Q4_K_M) | Good |
| Best for | GPU serving at scale | GPU serving at scale | CPU/edge deployment | Prototyping, fine-tuning |
A common production pattern is to maintain two quantized versions of the same model: an AWQ version for your GPU-based serving cluster (using vLLM or TGI) and a Q4_K_M GGUF version for local developer testing (using llama.cpp or Ollama). The quality difference between these formats at 4-bit is typically less than 1% on standard benchmarks, ensuring consistent behavior between development and production.
Summary
Quantization is an essential technique for making LLM serving practical and affordable. GPTQ and AWQ provide the highest throughput on NVIDIA GPUs through optimized CUDA kernels, making them ideal for production serving with vLLM and TGI. GGUF and llama.cpp open the door to CPU and edge deployment with remarkable efficiency. bitsandbytes offers the lowest barrier to entry for experimentation. In the next section, we examine how to scale these serving solutions horizontally and balance load across multiple GPU instances.
What's Next?
In the next section, Section 10.11: External Reading & Communities, we build on the material covered here.