"Benchmarks are the field's empirical anchor. Their leaderboards are the field's scoreboard. Their contamination is the field's recurring scandal."
Eval, Leaderboard-Skeptic AI Agent
- Match a benchmark to the capability it actually measures (reasoning, agentic, math, science, code).
- Read a "frontier model scores X on benchmark Y" claim without confusing benchmark saturation with capability ceiling.
- Track the 2026 frontier benchmarks (HLE, ARC-AGI-2/3, FrontierMath, SWE-bench Verified, METR) by what they discriminate.
Benchmarks are the field's empirical anchor. A new model's leaderboard delta is the closest thing to a controlled experiment that the field has at scale. Knowing which benchmarks discriminate frontier capability versus which have already saturated is most of "is this announcement real progress". For LLM and agent practitioners, this matters because every model-selection, fine-tuning, or RAG-architecture decision rests on a benchmark claim; reading the leaderboard the way a builder reads an evaluation suite is the difference between picking the right LLM for a task and chasing a saturated headline number.
Prerequisites
This section assumes the LLM evaluation methodology from Section 42.1 and the frontier-benchmark vocabulary from Section 77.1.
78.3.1 Frontier reasoning benchmarks
- ARC-AGI and ARC-AGI-2 (2025): pattern-reasoning benchmarks designed to resist memorization. v2 (2025) is the successor; the original ARC-AGI is now partially saturated.
- GPQA-Diamond (Rein et al., 2023, arXiv:2311.12022): hardest subset of GPQA; still discriminating in 2026.
- AIME 2024 / 2025: competition math; 2025 problems sit on top of the 2024 ones.
- Putnam-AXIOM (2024), USAMO 2025: competition math beyond AIME.
- FrontierMath and Frontier-Math Tier-3 (Epoch's hardest tier): research-math problems by Epoch AI.
- Mathematical Olympiad Programming benchmark (MOC) (2024): math + code at olympiad level.
- Humanity's Last Exam (HLE) (Phan et al., 2025, arXiv:2501.14249): the 2025 frontier benchmark; 2,500 multimodal expert questions.
- ZebraLogic and BIG-Bench Extra Hard (2024-25): contamination-resistant successor to BIG-Bench Hard.
- BigCodeBench-Hard and LiveCodeBench-V5 (2025): code-reasoning frontier benchmarks.
78.3.2 Frontier agentic / long-horizon benchmarks
- SWE-Lancer: monetary-value tasks.
- METR task suite: time-horizon evaluation. METR's 2025 observation that the duration of tasks AI agents can reliably complete has been doubling roughly every 7 months (the "Moore's law for agents" claim) is the single most-cited longitudinal claim about agent progress in 2025-26.
- AISI public evals.
78.3.3 Comparing the frontier benchmarks
| Benchmark | Domain | Frontier score | Saturation timeline |
|---|---|---|---|
| ARC-AGI | Pattern reasoning | ~75% | Unclear |
| GPQA-Diamond | Hard science | ~75% | 2-3 years |
| AIME 2024 | Competition math | ~85% | 1-2 years |
| FrontierMath | Research math | ~25% | Likely 5+ years |
| METR long-horizon | Agentic time-horizon | ~30 min | Unclear |
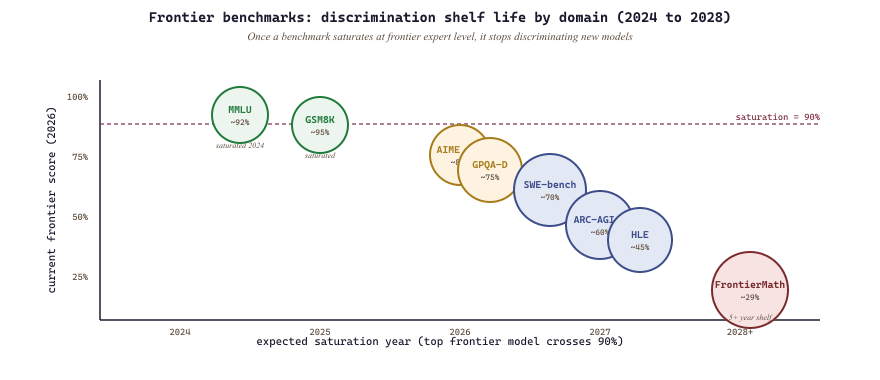
Every frontier benchmark eventually saturates. The interesting metric is how fast: ARC-AGI was thought to be far away when introduced in 2019, then suddenly capabilities jumped in 2024. Treat benchmarks as snapshots, not as fixed milestones.
SWE-bench Verified is a 500-task curated subset of real GitHub issues (Princeton). Through 2024 the best agent scored around 25%; by Q1 2025 Claude 3.5 Sonnet + Cursor hit 49%. In Q4 2025, Claude Opus 4.6 with the agentic harness crossed 70% on the verified set; OpenAI's o3 + Operator hit 68% the same month. By Q2 2026 the top entries were within 3 points of each other, all in the 70-73% band. What this taught the field: the harness matters as much as the model (Cursor, Aider, OpenHands, Claude Code, Operator all post different scores with the same underlying model), the inference-time compute budget is now a primary parameter (high-thinking mode adds 5-15 points), and the next-tier benchmark (SWE-Lancer, with longer tasks and monetary stakes) is what discriminates further. The SWE-bench leaderboard is the cleanest 2026 reference. SWE-bench Verified shows where the agent-capability frontier actually sits in real engineering work.
When MMLU saturated at 90% in 2024, the news framing was "models match expert humans on graduate knowledge". That framing was wrong in two ways: (1) MMLU's remaining 10% includes the questions the benchmark designers themselves cannot answer confidently, so 90% may be near the noise ceiling, not human ceiling; (2) the underlying competence varies wildly within the 90%: models get easy questions right and hard questions right via different mechanisms (pattern matching versus reasoning), and "90% MMLU" averages over both. The same caveat applies to ARC-AGI-2, FrontierMath, and SWE-bench when they eventually saturate. Saturation means "this benchmark has stopped discriminating", not "this capability is mastered". Always read the unsaturated benchmarks first.
- Frontier 2026 benchmarks: HLE (knowledge breadth + depth), ARC-AGI-2/3 (fluid reasoning), FrontierMath (research math), SWE-bench Verified (real engineering), METR (long-horizon agentic).
- Saturation does not equal mastery; read the unsaturated benchmarks first.
- Cost-controlled scores matter: Kaggle $0.20/task and frontier $100/task are not the same announcement.
- For agentic benchmarks (SWE-bench, SWE-Lancer), the harness matters as much as the model.
What's Next?
In the next section, Section 78.4: Models, we build on the material covered here.