Behind every closed-source frontier model is a technical report that tells you everything except the part you actually wanted to know.
Bert, Redaction Savvy AI Agent
Why study closed-source models? Although their weights and training details remain proprietary, frontier closed-source models set the benchmark for what is possible with large language models. Understanding their capabilities, architectural hints, and positioning helps practitioners choose the right tool for each task, anticipate where the field is headed, and recognize the gap (or lack thereof) between proprietary and open alternatives. Building on the historical model lineage from Section 6.1, this section maps the landscape as of early 2025, with notes on rapidly evolving developments.
Prerequisites
This section continues from Section 7.1. You should be comfortable with the modern Transformer architecture, tokenization, and the pretraining objective from Section 6.1. Some understanding of scaling laws helps when comparing model families across orders of magnitude.
This continuation of Section 7.1 picks up after OpenAI and Anthropic and covers the rest of the closed-source frontier: Google's Gemini series, the second-tier providers (xAI, Cohere, Mistral), the architectural patterns that converge across multimodal models, attention variants used in production frontier models, practical rate-limit constraints, the convergence trend, and the messy reality of benchmarking when contamination is everywhere.
7.2.1 Google DeepMind: The Gemini Series
Gemini's 1-million-token context window was famously demoed at Google I/O 2024 by feeding the model the entirety of the Apollo 11 mission transcripts and asking it to find a specific moment of humor. The demo worked, but the more important feat was that the 1M context was not a marketing trick; internal benchmarks at Google Cloud confirmed that needle-in-a-haystack retrieval held at over 99% accuracy across the full window, the first model where that was publicly verifiable.
Gemini 2.0 and 2.5: Native Multimodality at Scale
Google's Gemini models were designed from the ground up as natively multimodal systems. While GPT-4o also handles multiple modalities, Gemini's architecture was built for this purpose from the initial pretraining stage, jointly training on text, images, audio, and video data simultaneously. This approach, Google argues, produces deeper cross-modal understanding than retrofitting multimodal capabilities onto a text-first model.
The Gemini family includes several tiers:
| Model | Context Window | Strengths | Use Case |
|---|---|---|---|
| Gemini 2.5 Pro | 1M tokens | Deep reasoning, "thinking" mode, code | Complex analysis, agentic tasks |
| Gemini 2.0 Flash | 1M tokens | Speed, cost efficiency, multimodal | High-throughput production |
| Gemini 2.0 Pro | 1M tokens | Balanced capability, world knowledge | General-purpose, coding |
| Gemini Ultra | 1M tokens | Highest raw capability | Research, frontier tasks |
The million-token context window is Gemini's signature feature. Processing up to 1 million tokens (approximately 700,000 words) in a single prompt enables use cases that were previously impossible: analyzing entire codebases, processing hours of video with audio, or reasoning over complete book-length documents. Gemini 2.5 also introduced a "thinking" mode that, similar to OpenAI's o-series, allows the model to spend additional inference compute on complex reasoning tasks.
Integration Advantages
Google's unique position as both an AI lab and a massive cloud/consumer platform gives Gemini integration advantages that pure-play AI companies cannot match. Gemini is embedded in Google Search, Google Workspace (Docs, Sheets, Gmail), Android, and the Google Cloud Vertex AI platform. For organizations already committed to the Google ecosystem, these integrations reduce friction significantly.
7.1.5 Architecture Unification in Multimodal Models
The phrase "natively multimodal" appears in every frontier model announcement, but the engineering behind that phrase differs substantially between providers. The difference between a "bolt-on" multimodal system and a "native" one is not merely marketing: it affects what the model can reason about, how latency scales, and which cross-modal tasks it handles reliably.
Bolt-On vs. Native Multimodal Architecture
The bolt-on approach, exemplified by GPT-4V (the vision-capable predecessor to GPT-4o), works by prepending a separate vision encoder to an existing language model. A convolutional neural network or vision transformer (ViT) processes the image into a sequence of patch embeddings. These embeddings are then projected via a linear adapter layer into the language model's token embedding space. From the LLM's perspective, image tokens look like any other tokens; the LLM itself is unchanged.
This approach has real advantages: the language model backbone can be trained first, at full scale, without multimodal data. Vision capability can be added afterward without expensive joint pretraining. The downside is that the representations are misaligned. The vision encoder was trained on image-text contrastive pairs (like CLIP), not on the same objective as the language model. The adapter layer must bridge a representational gap between two models trained with different objectives on different data distributions. The result is a system that can describe images accurately but struggles with tasks requiring deep cross-modal reasoning, such as solving a geometry problem from a handwritten diagram.
GPT-4o replaced this approach with end-to-end training across all modalities from the outset. Text, image patches, and audio spectrograms are all tokenized and processed by the same transformer stack with the same attention layers. There is no separate encoder, no adapter, and no representational gap to bridge. Cross-modal reasoning emerges naturally because the representations are jointly optimized on the same training objective.
Gemini went further still. Google's Gemini technical report describes the model as having been built natively multimodal from the initial pretraining stage, jointly trained on text, images, audio, and video data simultaneously. The key claim is that image and text tokens share a joint embedding space: an image patch and a text token describing the same concept are close neighbors in that space. This is architecturally different from even GPT-4o's approach, where joint embedding was achieved through post-hoc alignment between existing text and vision representations rather than from-scratch joint training.
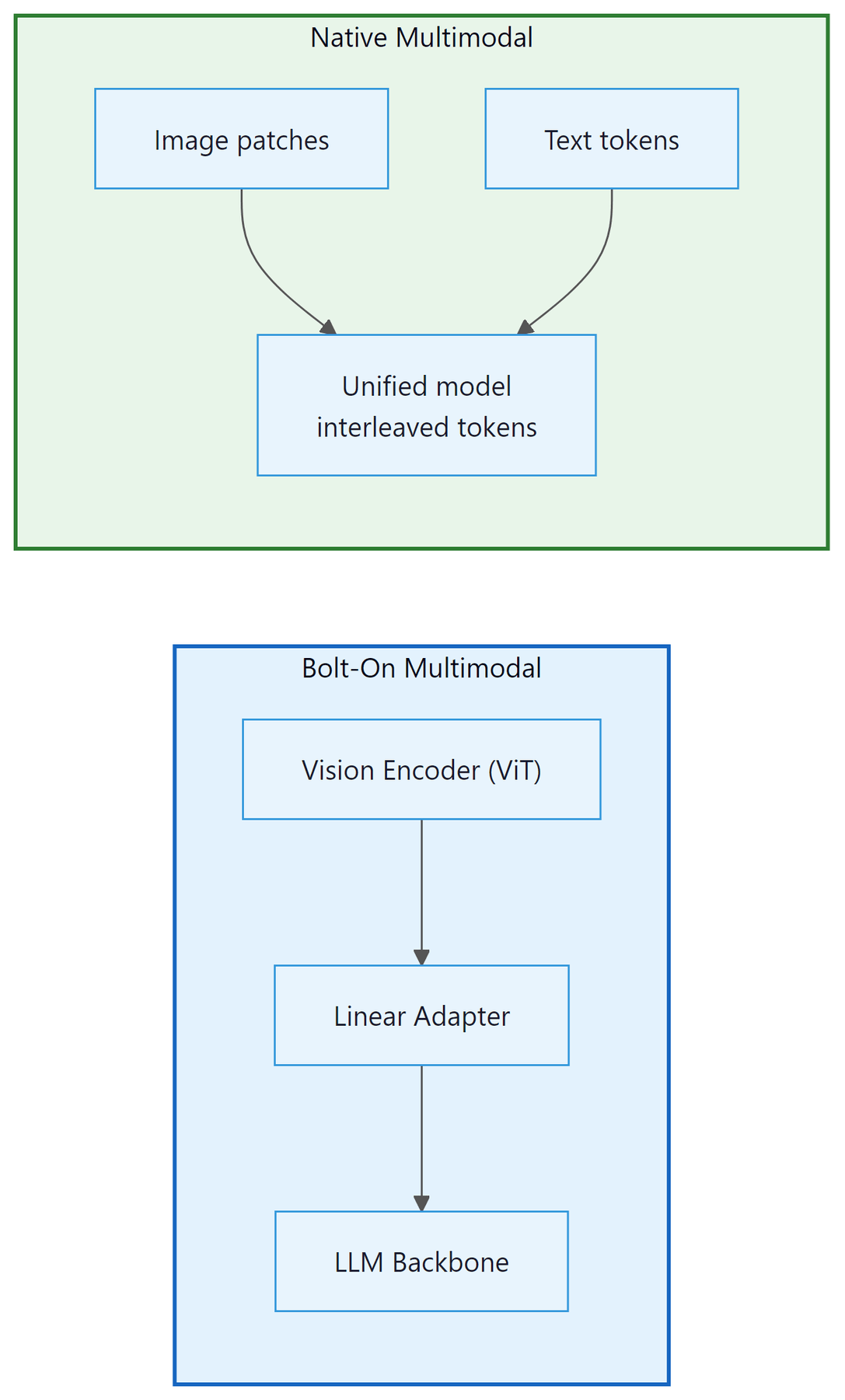
Cross-Modal Attention
In a native multimodal transformer, image patch tokens, audio tokens, and text tokens all participate in the same attention computation. Attention is not restricted by modality. A text token representing the word "triangle" can attend to image patch tokens that contain triangular edges, and the attention weights will be high if the model has learned that correspondence during training.
This cross-modal attention is why native multimodal models outperform bolt-on systems on tasks like: reading handwritten equations in a photo and solving them, answering spoken questions about images in real time (GPT-4o's low-latency audio response), or identifying the speaker in a video by correlating lip movements with audio features.
The tradeoff is training complexity and data requirements. Joint multimodal pretraining requires carefully balanced datasets across modalities and longer training runs. Bolt-on systems can leverage existing high-quality unimodal models and are faster to develop. For many production vision tasks (simple image captioning, OCR, chart reading), the bolt-on approach remains competitive; the native approach excels at tasks requiring tight cross-modal integration.
7.1.6 Attention Variants in Frontier Models
The core attention mechanism from the original transformer paper, multi-head attention (MHA), requires storing a key and value vector for every token in the context window for every layer. For a model with 96 layers, 128 attention heads, and a 128K-token context, the KV cache alone demands tens of gigabytes of GPU memory per concurrent session. Frontier labs have adopted several attention variants to address this, and the choice of variant shapes inference cost, memory requirements, and deployable batch sizes.
The table below summarizes what is known or credibly inferred about attention variants across major frontier models. Because most architectures are proprietary, some entries are marked as inferred from published research, model behavior, or team affiliations.
| Model | Attention Variant | Source / Confidence | Key Implication |
|---|---|---|---|
| GPT-4 / GPT-4o | MHA or GQA (undisclosed) | Inferred from context window scaling behavior | Extended context (128K) implies KV cache optimizations; GQA likely for serving efficiency |
| Claude 3.x / 4.x | GQA (inferred) | Inferred from Anthropic researcher affiliations and published work on long-context efficiency | 200K context window with maintained retrieval accuracy; GQA reduces KV cache footprint substantially |
| Gemini family | Multi-Query Attention (MQA) | Google DeepMind technical reports; MQA is a Google Research contribution | Single set of K/V heads shared across all query heads; maximally memory-efficient for serving at scale |
| Mistral 7B / Large | GQA + Sliding Window Attention (SWA) | Published in Mistral 7B technical paper (Jiang et al., 2023) | SWA limits attention to a local window (e.g., 4K tokens) at each layer, enabling linear memory scaling; GQA for KV efficiency |
| Mixtral (MoE) | GQA + SWA (same as Mistral, plus sparse MoE layers) | Published in Mixtral paper (Jiang et al., 2024) | MoE layers interleaved with transformer blocks; only 2 of 8 experts activated per token, reducing compute despite large parameter count |
The trend toward GQA and MQA reflects a practical industry consensus: standard MHA generates KV caches that are too large for cost-effective long-context serving. GQA, introduced by Ainslie et al. (2023), groups query heads so that multiple query heads share a single set of key and value heads. With 8 query heads sharing 1 KV head group (a common configuration), the KV cache is reduced by 8x with only marginal quality loss relative to full MHA. This is why GQA became the de facto standard for models targeting long context windows.
MQA (Shazeer, 2019) takes this further: all query heads share a single K and V head, for maximum memory savings. The tradeoff is slightly more quality degradation than GQA. Google's use of MQA in Gemini reflects their emphasis on high-throughput serving at scale, where memory bandwidth is the primary bottleneck. For a deep dive into KV cache mechanics and their production implications.
When you choose a self-hosted open-weight model (Mistral, Llama, Qwen), the attention variant directly affects how many concurrent requests you can serve on a given GPU. A model using GQA can serve 4x to 8x more simultaneous sessions than the equivalent MHA model on the same hardware. When comparing "equivalent" open-weight models, check the attention configuration in the model card before benchmarking throughput.
7.2.2 Second-Tier Frontier Models
The Tier 1 labs (OpenAI, Anthropic, Google) dominate headlines, but the frontier is wider than three vendors. xAI, Cohere, and Mistral each carve out a defensible position by optimizing for something Tier 1 deprioritizes: real-time data access, enterprise RAG with citations, or European data sovereignty. We survey them in that order to make the strategic differences obvious.
xAI Grok
Elon Musk's xAI developed Grok with a distinctive positioning: real-time access to data from the X (formerly Twitter) platform and a more permissive content policy than competitors. Grok 2 and Grok 3 have shown competitive benchmark performance, particularly in reasoning and mathematical tasks. The Grok 3 release demonstrated impressive results on coding and scientific reasoning benchmarks, placing it alongside the Tier 1 models on several evaluations.
Cohere Command R+
Cohere's Command R+ is optimized for enterprise retrieval-augmented generation (RAG) workflows. It includes built-in citation generation, grounded responses with source attribution, and strong multilingual support across 10+ languages. Command R+ is not designed to compete head-to-head on general benchmarks; instead, it targets the specific needs of enterprise document processing and knowledge management.
Mistral Large
Mistral AI occupies a unique position as a European frontier lab with both open-source and commercial offerings. Mistral Large 2 competes with GPT-4o on many benchmarks while offering deployment options that comply with European data sovereignty requirements. Mistral's hybrid strategy (open-weight smaller models plus proprietary frontier models) gives it credibility in both the open-source community and the enterprise market.
# Calling Mistral Large via the official Mistral Python SDK
from mistralai import Mistral
import os
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
resp = client.chat.complete(
model="mistral-large-latest",
messages=[{"role": "user",
"content": "Summarise the GDPR right to erasure in three bullets."}],
temperature=0.0,
safe_prompt=True,
)
print(resp.choices[0].message.content)Who: A regulated French insurer needed an LLM to read claim narratives and draft a structured summary for a human adjuster.
Constraint: The CISO refused any provider that routes traffic outside the EU. GPT-4o and Claude were ruled out on those grounds even though they scored higher on the carrier's internal benchmark by 3 to 5 points.
Decision: Mistral Large 2, called via the Paris-region endpoint, plus a fall-back to a self-hosted Mixtral 8x22B for cost-sensitive batch workloads. The team accepted a 4-point quality gap on the internal rubric in exchange for in-region processing, signed BAA-equivalent data-processing agreements, and a single legal jurisdiction for incident response.
Lesson: Outside the US, "best raw benchmark" frequently loses to "lawful to deploy". A European challenger that is roughly competitive with the global frontier can win whole national markets on residency alone.
7.2.3 Comparing the Frontier
Having surveyed eight commercial systems, the question for any practitioner is "which one do I actually pick?" A single benchmark score will not answer that. The honest comparison runs along multiple axes (reasoning, multimodality, long context, coding, latency, cost) where different models lead on different rows, and the right pick depends on which axis your application weights most heavily.
Capability Dimensions
Comparing frontier models requires examining multiple capability dimensions, as no single model dominates across all tasks:
| Dimension | Leader(s) | Notes |
|---|---|---|
| Mathematical reasoning | o3, Gemini 2.5 Pro | Extended thinking modes excel here |
| Code generation | Claude 4 Sonnet, o3 | Agentic coding workflows emerging |
| Long context fidelity | Gemini, Claude | 1M vs 200K, both strong retrieval |
| Multimodal understanding | Gemini 2.5, GPT-4o | Native multimodal architectures |
| Safety and alignment | Claude | Constitutional AI approach |
| Cost efficiency | Gemini Flash, GPT-4o mini | 10x cheaper than flagship models |
| Enterprise RAG | Cohere Command R+ | Built-in citation, grounding |
| Latency | Gemini Flash, Claude Haiku | Sub-second for simple queries |
Pricing Comparison
Pricing as of early 2025. LLM API pricing changes frequently; check provider websites for current rates.
Pricing for frontier models varies dramatically based on the model tier, input vs. output tokens, and whether batch or real-time processing is used. As a rough guide for input/output pricing per million tokens (as of early 2025):
# Approximate pricing comparison (per million tokens, USD)
# These prices change frequently; check provider documentation
pricing = {
"GPT-4o": {"input": 2.50, "output": 10.00},
"GPT-4o mini": {"input": 0.15, "output": 0.60},
"o1": {"input": 15.00, "output": 60.00},
"Claude 3.5 Sonnet":{"input": 3.00, "output": 15.00},
"Claude 4 Opus": {"input": 15.00, "output": 75.00},
"Gemini 2.0 Flash": {"input": 0.10, "output": 0.40},
"Gemini 2.5 Pro": {"input": 1.25, "output": 10.00},
}
# Cost to process a 50K token document with 2K token response
def estimate_cost(model, input_tokens=50000, output_tokens=2000):
p = pricing[model]
cost = (input_tokens / 1_000_000) * p["input"] + \
(output_tokens / 1_000_000) * p["output"]
return f"{model}: ${cost:.4f}"
for model in pricing:
print(estimate_cost(model))The cost differences are striking: for the same workload, Gemini 2.0 Flash costs $0.006 while Claude 4 Opus costs $0.90, a 150x difference. Choosing the right model tier is one of the highest-leverage decisions in production LLM deployment.
# Example: Making an API call to compare providers
# All major providers follow the OpenAI-compatible chat format
from openai import OpenAI
# OpenAI
client = OpenAI() # uses OPENAI_API_KEY env var
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "What is 25 * 37?"}],
max_tokens=50
)
print(f"GPT-4o: {response.choices[0].message.content}")
print(f"Tokens: {response.usage.prompt_tokens} in, {response.usage.completion_tokens} out")
# Anthropic (using OpenAI-compatible endpoint)
anthropic_client = OpenAI(
base_url="https://api.anthropic.com/v1/",
api_key="ANTHROPIC_API_KEY" # or use anthropic SDK directly
)
# Similar pattern for Google (Vertex AI) and other providers# Compare LLM providers via the OpenAI-compatible chat completion format.
# Most modern providers (OpenAI, Anthropic, Mistral, Together, Groq, Fireworks)
# accept this exact request shape; only the base_url and model id differ.
from openai import OpenAI
import os
PROVIDERS = [
{"name": "OpenAI", "base_url": None, "model": "gpt-4o-mini",
"api_key": os.getenv("OPENAI_API_KEY")},
{"name": "Anthropic","base_url": "https://api.anthropic.com/v1", "model": "claude-3-5-haiku-20241022",
"api_key": os.getenv("ANTHROPIC_API_KEY")},
{"name": "Together", "base_url": "https://api.together.xyz/v1", "model": "meta-llama/Llama-3.1-8B-Instruct-Turbo",
"api_key": os.getenv("TOGETHER_API_KEY")},
{"name": "Groq", "base_url": "https://api.groq.com/openai/v1", "model": "llama-3.1-8b-instant",
"api_key": os.getenv("GROQ_API_KEY")},
]
prompt = "Define entropy in one sentence."
for p in PROVIDERS:
if not p["api_key"]:
continue
client = OpenAI(api_key=p["api_key"], base_url=p["base_url"])
resp = client.chat.completions.create(
model=p["model"],
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
)
print(f"--- {p['name']} ({p['model']}) ---")
print(resp.choices[0].message.content.strip())The frontier model landscape evolves rapidly. Rather than memorizing current benchmarks, use this evaluation framework when assessing new model releases: (1) Check standardized benchmarks (MMLU, HumanEval, MATH) for broad capability. (2) Test on your specific use case with a held-out evaluation set. (3) Compare cost per quality point, not raw scores. (4) Verify rate limits and latency requirements. (5) Consider the provider's data privacy and retention policies. The best model for your application may not be the one topping the leaderboard.
The remaining topics in this discussion (rate limits and practical constraints, architectural inference from the outside, the convergence trend, and benchmarking methodology with contamination) have been moved into a continuation section to keep page lengths readable. Continue to Section 7.2a: Rate Limits, Convergence & Benchmarking.
Before choosing an open-weight model for your project, verify its license. Models like LLaMA have community licenses with commercial restrictions, while others (Mistral, Qwen) offer more permissive terms. A license mismatch discovered late can force expensive re-engineering.
- Three Tier-1 players define the frontier: OpenAI (GPT-4o, o-series), Anthropic (Claude family), and Google DeepMind (Gemini). Each has distinct strengths in reasoning, safety, multimodality, or context length.
- Reasoning models (o1/o3, Gemini "thinking" mode) represent a paradigm shift: spending more compute at inference time rather than only at training time. This enables dramatic improvements on mathematical and logical reasoning tasks.
- Native multimodality is replacing modular pipelines. GPT-4o and Gemini process text, images, and audio in unified architectures, improving cross-modal reasoning and reducing latency.
- Context windows have expanded dramatically: from 4K tokens in 2022 to 1M tokens in 2025. Long-context fidelity (not just capacity) is a key differentiator.
- Attention variants matter for serving: GQA and MQA cut the KV cache 4x to 8x relative to vanilla MHA, which is why every frontier provider has adopted one of them for long-context, high-throughput deployment.
- Capability comparison is multi-axis. No single model dominates reasoning, code, long context, multimodal, safety, latency, and cost simultaneously. Pick on the axis your application weights most heavily, not the headline benchmark.
- Rate limits, convergence, and benchmarking methodology are covered in Section 7.2a.
Show Answer
Show Answer
Show Answer
Show Answer
Show Answer
Show Answer
Exercises
You are choosing a frontier model for three workloads: (a) a high-volume customer service chatbot doing extractive QA over a knowledge base; (b) a coding assistant for senior engineers; (c) a research workflow that synthesizes long PDFs into structured reports. For each, name the family you would default to and the single capability that drives the choice.
Answer Sketch
(a) High-volume QA: a small fast model tier (GPT-4o-mini, Claude Haiku, Gemini Flash). Extractive QA needs grounding accuracy and speed, not reasoning depth; you save 30-60x on per-call cost. (b) Coding for seniors: Claude (Sonnet/Opus tier) historically leads code editing benchmarks like SWE-bench, with GPT-4-class as a competitive alternative. The driver is structured edit fidelity over multi-file repos. (c) Long-document synthesis: Gemini for the largest context window or Claude with citation-aware prompting. The driver is long-context recall plus the ability to maintain coherence over hundreds of thousands of tokens. The general lesson: pick on workload-specific strengths, not on the headline benchmark.
Frontier model API pricing has dropped roughly 10x per year for equivalent quality. Predict: (a) what is the implication for your build-vs-buy decision today on a use case that requires GPT-4-class quality? (b) Why doesn't the same trend hold for fine-tuned open models you self-host? (c) What single application category is most disrupted by the price drop?
Answer Sketch
(a) The economics of self-hosting GPT-4-equivalent open weights are getting worse, not better, because the API price floor is falling faster than your H100 amortization. Default to the API unless you have a hard data-residency or latency constraint. (b) Self-hosting cost is dominated by GPU price and depreciation, which fall slowly (~30%/year), not by efficient batching at provider scale. APIs benefit from millions of concurrent requests sharing the same model instance. (c) High-volume per-task automation (form-filling, classification, simple extraction) gets disrupted most: it was uneconomic at 2023 prices and now runs at near-zero marginal cost, opening millions of new use cases per dollar of budget.
Sketch a 6-line Python wrapper that calls OpenAI by default and falls back to Anthropic on rate-limit or 5xx errors. The wrapper should preserve the user's prompt and surface a single unified response interface. What is the main correctness pitfall to watch for?
Answer Sketch
def chat(prompt):
try: return openai.chat.completions.create(model="gpt-4o", messages=[{"role":"user","content":prompt}]).choices[0].message.content
except (openai.RateLimitError, openai.APIStatusError):
return anthropic.messages.create(model="claude-sonnet-4", max_tokens=1024, messages=[{"role":"user","content":prompt}]).content[0].textThe pitfall: providers differ in tokenization, system-prompt semantics, JSON mode reliability, and tool-call schemas, so the same prompt can produce structurally different outputs. Failover is fine for plain-text use but risky for structured workflows; for those, do per-provider validation and reroute on schema failure rather than just on HTTP errors.
You built your product on a single closed-source frontier model. List four concrete risks beyond price hikes, and for each name one mitigation that does not require switching providers.
Answer Sketch
(1) Silent quality regression when the provider rolls a new checkpoint under the same model name. Mitigation: pin to dated model snapshots (e.g., gpt-4o-2024-08-06) and run a regression eval before upgrading. (2) Region or feature deprecation with weeks of notice. Mitigation: maintain a documented dependency on which features you use and an alternative pre-validated. (3) Capacity throttling during incidents. Mitigation: provision a batch-tier fallback queue and degrade gracefully to lower-tier models. (4) Acceptable-use policy changes that reclassify your workload as prohibited. Mitigation: a periodic policy review and a vendor-portability test harness so the migration cost is bounded. The general principle: structure your code so the provider is a configuration, even if you don't actively switch.
What's Next?
The discussion continues in Section 7.2a: Rate Limits, Convergence & Benchmarking, which covers the practical constraints, architectural inference, convergence trend, and benchmarking methodology that follow naturally from this section's vendor and architecture survey. After that, Section 7.3: Open-Source & Open-Weight Models turns from closed-source frontier APIs to open-weight models.