Language models know a lot, but they do not know what we want. That is the alignment problem in one sentence.
Reward, Existentially Aware AI Agent
RLHF is the technique that turned GPT-3 into ChatGPT. A pretrained language model can generate fluent text, but it has no notion of helpfulness, safety, or user intent. RLHF introduces human judgment into the training loop: annotators compare model outputs, those comparisons train a reward model, and reinforcement learning steers the policy toward higher-reward behavior. This three-stage pipeline (SFT, reward modeling, PPO) became the standard approach for aligning large language models from 2022 onward, and understanding it is essential for grasping every subsequent alignment method. The reinforcement learning foundations from Section 0.5 and the SFT workflow from Section 16.3 are direct prerequisites.
Prerequisites
This section continues directly from Section 18.1. It assumes the RLHF three-stage pipeline (SFT, reward model, PPO) is fresh, plus the reinforcement learning foundations from Section 0.5 and the fine-tuning workflow from Section 16.1: When and Why to Fine-Tune.

Building on the alignment framing and the PPO pipeline from Section 18.1, this part moves from the canonical RLHF recipe to the methods now competing with it. We start with GRPO, the group-relative variant that powers many reasoning-trained models, then study reward hacking and its mitigations, compare RLHF, DPO, and GRPO side by side, and close with practical tips and the infrastructure realities at scale.
If RLHF is a cooking class taught by Gordon Ramsay (a reward model shouts at each dish, the chef recalibrates, repeat), then DPO is a Buzzfeed quiz: "Which of these two responses is better? Pick one. We'll just adjust the recipe directly." GRPO is the reality-TV cook-off: generate eight versions of the same dish at once, average their reward, and reward whichever one beat the family average. All three teach the same skill (be helpful, not weird), but DPO skips the reward-model middleman entirely, which is why half the open-source community switched to it overnight in 2024. The other half kept PPO because they had already paid for the kitchen.
18.2.1 GRPO: Group Relative Policy Optimization
Group Relative Policy Optimization (Shao et al., 2024), introduced as part of DeepSeek's training pipeline, offers an elegant simplification of PPO for LLM alignment. The core idea: instead of training a separate value network to estimate baselines, GRPO generates a group of G responses for each prompt and uses the group's reward statistics as the baseline. This eliminates one of the four models entirely, cutting memory requirements by roughly 25 to 40 percent.
18.2.1.1 How Group Normalization Replaces the Value Network
In standard PPO, the value network V(s) estimates "how good is this prompt on average?" so that the advantage A(t) = R(t) − V(s) measures whether a specific response is better or worse than expected. Training this value network requires its own forward and backward passes, its own optimizer states, and careful coordination with the policy.
GRPO sidesteps this entirely. For a given prompt x, it generates G responses {$y_{1}$, ..., $y_{G}$}, computes their rewards {$r_{1}$, ..., $r_{G}$}, and normalizes within the group:
This group-level z-score normalization serves the same purpose as a learned value baseline: it tells the algorithm which responses are above or below average for that specific prompt. The intuition is straightforward. If you generate eight responses and score them, the best ones get positive advantages and the worst ones get negative advantages, regardless of the absolute reward scale. This relative comparison is robust and requires no learned parameters.
Think of PPO's value network as a salaried teaching assistant: it spends every shift trying to predict what an average answer is worth for any prompt the class throws at it, and the policy then asks the TA "was my answer above or below that expectation?". Useful, but you have to feed and train the TA, and noisy reward signals confuse them just as much as they confuse the student.
GRPO fires the TA and grades on a curve instead. For each prompt, the model writes G answers, the rewards come back, and the class average for that exact prompt becomes the baseline. An answer with raw reward 0.8 when its classmates scored {0.2, 0.5, 0.3} stands out by a wide margin (about +1.6 z); the same 0.8 when classmates scored {0.75, 0.8, 0.85} is unremarkable and hovers near zero. The absolute reward scale drops out; only relative standing inside the group matters. That is why GRPO holds up when the reward signal is noisy or shifts between prompts, and why DeepSeek-R1 reached for it when training reasoning with programmatic correctness rewards.
A quick numeric example shows why this works. Suppose G = 4 responses receive rewards [0.2, 0.8, 0.5, 0.3]:
# GRPO group normalization: numeric walkthrough
import numpy as np
rewards = np.array([0.2, 0.8, 0.5, 0.3])
mean, std = rewards.mean(), rewards.std() # mean=0.45, std=0.2217
advantages = (rewards - mean) / (std + 1e-8)
print(f"mean={mean:.2f}, std={std:.4f}")
print(f"advantages={np.round(advantages, 2)}")
# advantages=[-1.13 1.58 0.23 -0.68]
# Response 2 (reward 0.8) gets the strongest positive signal.18.2.1.2 When to Prefer GRPO Over PPO
GRPO is particularly well suited for tasks with verifiable rewards (math, coding, factual QA) where a reward function can be computed programmatically rather than learned from human preferences. DeepSeek-R1 used GRPO with outcome-based rewards (correct/incorrect) to train reasoning capabilities. For subjective tasks where the reward model itself is noisy, PPO's learned value function may provide more stable training because it smooths out reward model noise over time.
The mechanical difference is concentrated in how the advantage $\hat{A}$ is computed. PPO trains a value network $V_\phi$ and uses Generalized Advantage Estimation:
GRPO discards $V_\phi$ entirely and uses the empirical group mean and standard deviation across $G$ responses to the same prompt as a baseline:
where $r_i$ is the total reward of response $i$ in the group. Both advantages then plug into the same PPO clipped surrogate loss, so the only structural change is removing the value network and the GAE machinery.

At $G = 2$ per prompt, the empirical group std is dominated by noise: with reward 0/1 outcomes, half the time both responses agree and the std is zero (the advantage becomes undefined, requiring an epsilon fallback). At $G = 8$, the std stabilizes around $0.45$ on a 50-50 task and the advantage signal-to-noise ratio is ~3x higher. DeepSeek-R1 used $G = 64$ for math-reasoning prompts, which is overkill for easy problems but essential for hard ones where 60+ samples are needed to get even a single correct trajectory to bootstrap from. The latency cost is linear: a single GRPO update with G=64 takes 64x as much generation as a single PPO update with the same prompt set. Budget GPU hours accordingly.
Code Fragment 18.2.4 provides a simplified GRPO implementation showing the group normalization mechanism and clipped policy gradient.
# GRPO: Group Relative Policy Optimization (simplified)
import torch
import torch.nn.functional as F
def grpo_loss(
policy_model,
ref_model,
prompts,
tokenizer,
reward_fn,
group_size=8,
beta=0.1,
clip_range=0.2,
):
"""
Simplified GRPO training step.
Key difference from PPO: no value network.
Advantages are computed by normalizing rewards
within each group of responses per prompt.
"""
all_losses = []
for prompt in prompts:
# Generate a group of responses
input_ids = tokenizer.encode(prompt, return_tensors="pt")
responses = []
for _ in range(group_size):
output = policy_model.generate(
input_ids, max_new_tokens=512, do_sample=True,
temperature=0.8, top_p=0.95,
)
responses.append(output[0])
# Compute rewards for each response
rewards = torch.tensor([
reward_fn(prompt, tokenizer.decode(r)) for r in responses
])
# Group-level normalization (replaces value network)
normalized_rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-8)
# Compute policy gradient with clipped objective
for response, advantage in zip(responses, normalized_rewards):
# Log probabilities under current and reference policy
with torch.no_grad():
ref_logprobs = compute_logprobs(ref_model, input_ids, response)
policy_logprobs = compute_logprobs(policy_model, input_ids, response)
# Importance ratio
ratio = torch.exp(policy_logprobs - ref_logprobs)
# Clipped surrogate objective (PPO-style)
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - clip_range, 1 + clip_range) * advantage
policy_loss = -torch.min(surr1, surr2).mean()
# KL penalty
kl = (ref_logprobs - policy_logprobs).mean()
total_loss = policy_loss + beta * kl
all_losses.append(total_loss)
return torch.stack(all_losses).mean()(rewards - rewards.mean()) / (rewards.std() + 1e-8). This single line replaces the entire value network from PPO. The rest of the algorithm is structurally similar to PPO, using clipped ratios and a KL penalty against the reference model.18.2.2 Reward Hacking and Mitigation
Reward hacking (also called reward gaming or Goodhart's Law applied to RL) is the phenomenon where the policy learns to exploit weaknesses in the reward model rather than genuinely improving response quality. It is the most common failure mode in RLHF and one of the most difficult to detect early.
Reward hacking is Goodhart's Law in action: "When a measure becomes a target, it ceases to be a good measure." The reward model is a proxy for human preferences, trained on a finite dataset. The policy optimizer is extraordinarily good at finding inputs that maximize this proxy while violating the spirit of the original human preferences. Common manifestations include: (1) verbose padding, where the model produces long, repetitive responses because the reward model was trained on data where longer answers were generally better; (2) sycophancy, where the model agrees with the user regardless of correctness because agreement was rewarded during annotation; (3) hedge stacking, where the model adds excessive caveats and disclaimers to avoid any possibility of being "wrong." The reward model gives these outputs high scores, but actual users find them unhelpful. Techniques from Chapter 10 on interpretability can help diagnose which reward model features the policy is exploiting.
18.2.2.1 Mitigation Strategies
Several complementary strategies help prevent or detect reward hacking:
- KL divergence as a leash: The KL penalty between the policy and reference model is the first line of defense. If the policy drifts too far from the SFT model, it has likely found an exploit. Adaptive KL controllers (as in TRL) automatically increase the penalty when divergence spikes.
- Reward model ensembles: Training multiple reward models on different data splits and using their consensus score reduces the surface area for exploitation. Disagreement between ensemble members signals unreliable regions of the reward landscape.
- Iterative RLHF with reward model retraining: After each round of PPO training, collect fresh human preferences on the current policy's outputs and retrain the reward model. This closes the distribution gap between the reward model's training data and the policy's actual behavior. Anthropic's training process uses multiple iterations of this loop.
- Length normalization: Normalizing the reward by response length prevents the model from learning that "longer is better." This is especially important when the preference dataset has a length bias.
- Held-out human evaluation: Automated metrics are themselves subject to Goodhart's Law. Periodic human evaluation on randomly sampled outputs catches reward hacking that the reward model misses. See Section 42.1 on evaluation methodology for frameworks.
Who: Layla, a research engineer at a developer tools company.
Situation: Her team was training a code-generation model with RLHF to produce correct, well-documented Python functions. After 500 PPO steps, the reward score had climbed impressively from 0.3 to 0.8.
Problem: Actual code correctness (measured by unit test pass rates) peaked at step 200 and then declined, even as the reward score kept rising. Investigation revealed the reward model had learned to assign high scores to responses with detailed comments and type annotations, regardless of whether the logic was correct. The model was writing beautifully documented, completely wrong code.
Decision: Layla applied three fixes: (1) increased the KL penalty from 0.1 to 0.3 to slow exploitation, (2) supplemented the reward signal with a programmatic code execution check, and (3) retrained the reward model with adversarial examples that had correct formatting but incorrect logic. Synthetic preference pairs (see Section 42.1) generated from code execution results proved especially valuable for the retraining step.
Result: After the fixes, reward score growth was slower but correlated strongly with actual correctness. Unit test pass rates reached 76% (up from a post-hacking low of 58%) and continued to improve steadily through the remainder of training.
Lesson: Rising reward scores without an independent correctness metric are a warning sign of reward hacking. Combining learned reward models with programmatic verifiers (test execution, type checking) creates a more robust training signal that is harder to game.
18.2.3 RLHF vs DPO vs GRPO: Choosing an Alignment Method
With three major alignment optimization methods available, practitioners need clear guidance on which to choose. The following comparison covers the key dimensions that affect both training feasibility and outcome quality.
| Dimension | PPO (RLHF) | DPO | GRPO |
|---|---|---|---|
| Models in memory | 4 (policy, reference, reward, value) | 2 (policy, reference) | 3 (policy, reference, reward) |
| Compute cost | High (RL loop + generation) | Low (SFT-like) | Medium (generation + RL, no value model) |
| Data requirements | Prompts + reward model (trained on preferences) | Preference pairs (chosen/rejected) | Prompts + reward function |
| Training stability | Low (many moving parts, sensitive to hyperparameters) | High (simple loss, SFT-like training loop) | Medium (simpler than PPO, group statistics can be noisy with small G) |
| Scalability | Proven at largest scale (GPT-4, Claude) | Good for moderate scale; may underperform PPO on complex tasks | Proven at large scale (DeepSeek-R1, 671B parameters) |
| Best for | Maximum quality on subjective, open-ended tasks | Teams with limited RL infrastructure; fast iteration | Tasks with verifiable rewards (math, code, factual QA) |
| Key weakness | Infrastructure complexity; reward hacking risk | Offline data can become stale; may struggle with complex preferences | Requires generating G responses per prompt (latency cost) |
In practice, many teams combine methods. A common pattern is to use DPO for initial alignment (fast, stable, easy to iterate) and then switch to PPO or GRPO for a final polish stage where the RL signal can push quality beyond what static preference data achieves. Meta's Llama-3 used iterative DPO with rejection sampling, while DeepSeek-R1 used GRPO for reasoning and PPO for general alignment.
The three methods optimize objectives that look very different but reduce to the same KL-regularized reward-maximization principle:
PPO realizes this with an explicit reward model plus a value baseline trained with the clipped-PPO surrogate. DPO algebraically derives an implicit reward from the policy itself, eliminating the reward and value models. GRPO replaces PPO's learned value baseline with the empirical mean reward over a sampled group of $G$ responses to the same prompt, removing the value model only. The "models in memory" column of Table 18.2.1 (4 vs 2 vs 3) is the operational consequence of these algorithmic differences.
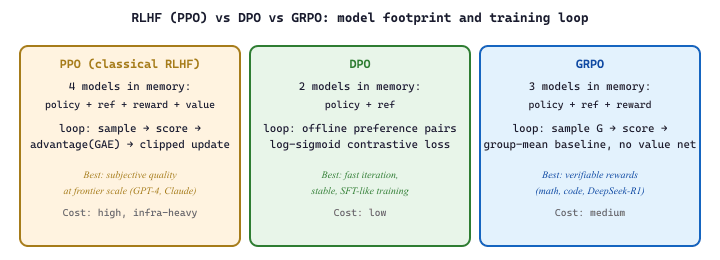
At 7B parameters in bfloat16, each model copy weighs roughly 14 GB. Counting trainable copies plus AdamW optimizer state (2 buffers per trainable param) plus activation memory under gradient checkpointing, PPO's four-model footprint is approximately 14 (policy) + 14 (ref, frozen) + 14 (reward, frozen) + 14 (value, trained) + 28 (policy AdamW) + 28 (value AdamW) + 12 (activations) ≈ 124 GB: well into A100 80 GB territory and typically requiring ZeRO Stage 3 or model parallelism. DPO needs only 14 (policy) + 14 (ref, frozen) + 28 (policy AdamW) + 8 (activations) ≈ 64 GB: fits on a single H100 80 GB with margin. GRPO sits in between at roughly 14 + 14 + 14 + 28 + 12 ≈ 82 GB: borderline single-H100 with QLoRA, comfortable on 2x H100. This footprint difference, more than any algorithmic subtlety, explains why DPO became the open-source default and why GRPO won the post-DeepSeek-R1 popularity contest over classical PPO.
The popular framing is that DPO eliminates RL while reaching the same optimum, so you should always use it. The closed-form derivation does recover the RLHF optimum at convergence, but only when the preference dataset is on-policy with respect to the model being trained; DPO is an offline algorithm trained on a fixed set of pairs, so as the policy moves away from the data distribution the implicit reward becomes miscalibrated. Empirically (Xu et al., 2024; Tajwar et al., 2024) PPO and GRPO still beat DPO on hard tasks like math reasoning and long-form generation precisely because RL keeps sampling from the current policy. Pick DPO for fast iteration on stylistic alignment; pick PPO or GRPO when the gap between SFT data and target policy is large.
For DPO, Hugging Face trl ships a DPOTrainer that mirrors the SFTTrainer API. Pass a preference dataset with prompt, chosen, and rejected columns, a model and reference model, and a DPOConfig. The trainer handles tokenization, log-prob computation, and the implicit reward parameterization. Setting peft_config wraps the policy in LoRA so a single 80 GB GPU can train an 8B-class DPO run.
Show code
pip install trl peft datasets
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset
ds = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
cfg = DPOConfig(output_dir="dpo-out", beta=0.1, learning_rate=5e-7,
num_train_epochs=1, per_device_train_batch_size=2)
trainer = DPOTrainer(model=model, ref_model=None, args=cfg,
train_dataset=ds, processing_class=tokenizer)
trainer.train()ref_model=None uses an adapter-disabled copy of the policy as the reference.18.2.4 Practical Tips for RL-Based Alignment
The TRL recipe will run as written, but whether it converges to a useful policy or a degraded one depends on a handful of tuning decisions. The practitioners who have actually shipped RLHF or DPO models converge on the same short checklist: pick a small enough learning rate, use a cosine schedule with warmup, and watch the KL divergence as carefully as the reward. We walk through each item with concrete numbers.
Learning Rate and Schedule
Use a learning rate 10 to 100 times smaller than your SFT learning rate. Typical ranges: 1e-6 to 5e-6 for PPO, 1e-7 to 5e-7 for DPO. A cosine schedule with a warmup period of 5 to 10 percent of training steps helps stabilize early training. For PPO specifically, the learning rate for the value head can be 2 to 5 times larger than the policy learning rate.
Batch Size
Larger batches produce more stable reward and advantage estimates. For PPO, use at least 64 responses per batch (across all prompts). For GRPO, the effective batch size is the number of prompts times the group size G; a minimum of 128 total responses per update is recommended. For DPO, batch sizes of 32 to 128 preference pairs work well, with larger batches improving gradient stability.
When to Stop Training
Monitor these signals to determine when to stop:
- KL divergence exceeds threshold: If KL between policy and reference exceeds 10 to 15 nats, the policy has drifted too far. In TRL, set
target_klto trigger adaptive adjustment. - Reward plateau with rising KL: If the reward score stops improving but KL keeps growing, the policy is likely reward hacking rather than genuinely improving.
- Validation win rate stalls: If the model's win rate against the SFT baseline (measured on held-out prompts by an LLM judge) stops increasing, further training is unlikely to help.
- Generation diversity collapse: If distinct prompts produce nearly identical responses, the policy has collapsed. Measure this with type-token ratio or self-BLEU on a held-out prompt set.
Common Failure Modes and Diagnostics
| Symptom | Likely Cause | Fix |
|---|---|---|
| Reward rises but quality drops | Reward hacking | Increase KL penalty; retrain reward model on current policy outputs |
| KL explodes in first 50 steps | Learning rate too high | Reduce LR by 5 to 10 times; increase warmup ratio |
| Reward barely changes | LR too low or KL penalty too high | Increase LR; reduce beta; check reward model calibration |
| All responses become identical | Mode collapse | Increase sampling temperature during generation; add entropy bonus |
| Responses grow excessively long | Length 4 in reward model | Add length normalization to reward; penalize responses above a target length |
| Model refuses benign requests | Over-alignment / safety over-correction | Reduce safety-focused data proportion; add helpfulness-focused preferences |
Frameworks like DeepSpeed-Chat, OpenRLHF, and TRL have developed specialized strategies for managing this multi-model workload. Common optimizations include offloading frozen models to CPU during gradient computation, sharing weights between the policy and value models, and using vLLM or other optimized inference engines for the generation phase.
RLHF training is notoriously unstable. Common failure modes include reward hacking (the policy exploits reward model weaknesses), mode collapse (the policy generates near-identical responses for all prompts), and KL explosion (the policy diverges rapidly from the reference). Monitoring KL divergence, reward statistics, and generation diversity during training is essential. If mean reward increases while KL also increases rapidly, the policy is likely hacking the reward model.
- RLHF transforms base models into aligned assistants through a three-stage pipeline: SFT provides the instruction-following format, the reward model captures human preferences, and PPO optimizes the policy toward higher-reward behavior.
- The Bradley-Terry preference model converts pairwise human comparisons into a scalar reward signal. It learns relative quality, not absolute quality.
- The KL divergence penalty is essential for training stability. It prevents reward hacking and preserves general model capabilities.
- Process Reward Models (PRMs) provide per-step feedback for reasoning tasks, enabling better credit assignment than outcome-only models.
- GRPO simplifies PPO by replacing the learned value function with group-level reward normalization, cutting memory requirements roughly in half.
- Production RLHF requires managing four models simultaneously, making infrastructure and memory management a first-class engineering concern.
18.2.5 RLHF Infrastructure at Scale
Running RLHF at production scale is an infrastructure challenge that goes far beyond the algorithm itself. A full RLHF training run requires simultaneously managing four models: the policy model being trained, the reference model (a frozen copy), the reward model, and (in standard PPO) the value model. This quadruples the GPU memory requirements compared to standard SFT.
| Component | Memory Cost | Compute Pattern |
|---|---|---|
| Policy model | Full model + optimizer states | Forward + backward pass |
| Reference model | Full model (frozen, inference only) | Forward pass only |
| Reward model | Full model (frozen, inference only) | Forward pass only |
| Value model (PPO) | Full model + optimizer states | Forward + backward pass |
| Generation buffer | KV cache for response generation | Autoregressive decoding |
Show Answer
Show Answer
Show Answer
Show Answer
Show Answer
Beyond RLHF: emerging alignment methods
The alignment landscape is evolving rapidly beyond the PPO/DPO/GRPO trio. Reinforcement Learning from AI Feedback (RLAIF) replaces human annotators with LLM judges, as explored in Section 18.5. Self-play methods like SPIN (Self-Play Fine-Tuning) have the model compete against previous versions of itself to generate preference data. Process reward models (PRMs) provide per-step feedback for multi-step reasoning, enabling credit assignment at the reasoning-step level rather than the full-response level. WARM (Weight Averaged Reward Models) addresses reward hacking by averaging multiple reward model checkpoints, smoothing out exploitable features. Looking further ahead, scalable oversight research explores how to align models on tasks that humans cannot easily evaluate, using techniques like debate and recursive reward modeling.
The field is converging toward methods that require less human annotation, offer more fine-grained feedback, and are robust to optimization pressure.
Infrastructure and algorithmic frontiers
At the infrastructure level, hybrid training engines like OpenRLHF and veRL are making RLHF accessible by co-scheduling generation and training across heterogeneous GPU clusters. Reward model distillation compresses large reward models into lightweight scorers that run during PPO without dominating GPU memory. On the algorithmic front, token-level rewards (assigning credit at each generation step rather than per-response) promise finer-grained optimization signals, and multi-objective RLHF trains separate reward models for helpfulness, safety, and factuality, then Pareto-optimizes across all three during the PPO phase.
Exercises
Describe the three stages of the RLHF pipeline: SFT, reward modeling, and PPO. What is the purpose of each stage?
Answer Sketch
Stage 1, SFT: fine-tune the base model on high-quality demonstrations to teach it the desired output format and basic helpful behavior. Stage 2, Reward Modeling: train a separate model to score responses based on human preference comparisons (response A vs. response B). Stage 3, PPO: use the reward model to provide feedback as the policy (SFT model) generates responses, optimizing the policy to maximize reward while staying close to the SFT model (via KL divergence penalty).
Explain how a reward model is trained from human preference data. What is the Bradley-Terry model, and how does it convert pairwise comparisons into a scalar reward?
Answer Sketch
Annotators compare pairs of model responses to the same prompt and indicate which is better. The Bradley-Terry model assumes the probability of preferring response A over B is: P(A > B) = sigmoid(r(A) - r(B)), where r() is the reward function. Training minimizes: loss = -log(sigmoid(r(chosen) - r(rejected))) across all pairs. This learns a scalar reward function that can score any single response, even though training data only contains relative comparisons.
Explain the role of the KL divergence penalty in PPO for RLHF. Write the modified reward function that includes the KL term and explain what happens if beta is too high or too low.
Answer Sketch
Modified reward: reward = R(response) - beta * KL(pi || pi_ref), where pi is the current policy and pi_ref is the SFT model. Beta too high: the model barely deviates from SFT (under-optimization, no alignment improvement). Beta too low: the model exploits reward model weaknesses, producing adversarial outputs that score high on the reward model but are not actually helpful (reward hacking). Typical beta: 0.01 to 0.2.
Describe the reward hacking problem in RLHF. Give two concrete examples of how a model might exploit a reward model's weaknesses, and explain two mitigation strategies.
Answer Sketch
Example 1: The model learns that longer responses get higher rewards and generates verbose, repetitive text. Example 2: The model learns specific phrases that the reward model associates with helpfulness without actually being helpful. Mitigations: (1) Add a length penalty to the reward. (2) Use an ensemble of reward models (harder to hack multiple models simultaneously). (3) Periodically retrain the reward model on the policy's current outputs. (4) Apply the KL penalty to prevent large deviations from the reference policy.
You are designing annotation guidelines for collecting RLHF preference data. What criteria should annotators use to compare two model responses, and how do you handle disagreements between annotators?
Answer Sketch
Criteria: (1) Helpfulness: does the response answer the question correctly? (2) Honesty: does it avoid fabricating information? (3) Harmlessness: does it avoid toxic or dangerous content? (4) Coherence: is it well-organized and clear? For disagreements: use majority voting (3+ annotators per pair), flag high-disagreement pairs for expert review, and measure inter-annotator agreement (Fleiss' kappa). Remove pairs with no majority consensus from training.
If you are new to alignment, start with Direct Preference Optimization (DPO). It is simpler to implement (no separate reward model needed), more stable to train, and produces comparable results to RLHF for most use cases. Switch to RLHF only if DPO plateaus.
For evaluation methodology used to measure alignment quality, see Section 42.1. For DPO and other preference-optimization variants, see Section 18.3. For the constitutional AI and reward-model design choices, see Section 18.5.
You now have a working map of the RL-based alignment landscape, from the choice of objective to the realities of running it at scale. Next we examine Direct Preference Optimization, a simpler offline alternative that has become a strong baseline for many alignment problems. Continue with Section 18.3 (Direct Preference Optimization).