"Citing your sources is not pedantry. It is the difference between a trustworthy assistant and a confident confabulator."
RAG, Scrupulously Footnoted AI Agent
A RAG system that generates correct answers but cannot tell you where those answers came from is only half-built. Source attribution transforms RAG from a "trust me" black box into a verifiable information system. Users, auditors, and downstream processes need to trace every claim back to a specific document, paragraph, or data record. This section covers the system design problem of building citation into RAG pipelines: from prompt-level strategies through post-generation verification to end-to-end attribution architectures.
Prerequisites
This section builds on the RAG architecture from Section 32.1. Familiarity with prompt engineering and structured output parsing is assumed. Advanced retrieval techniques and hallucination-detection methods are covered in detail later in the book.
The mental model: in a RAG system, the citation is the bridge between the LLM's generated text and the underlying knowledge base, and that bridge does five distinct jobs at once. Source attribution serves multiple purposes beyond user trust:
- Verifiability: Users can click through to the source document and confirm claims, reducing the effective hallucination rate by enabling human verification
- Accountability: When answers are wrong, citations enable root-cause analysis: was the source document incorrect, was the wrong passage retrieved, or did the LLM misinterpret the evidence?
- Compliance: Regulated industries (finance, healthcare, legal) require audit trails showing which documents informed a decision; emerging AI regulations increasingly mandate explainable outputs.
- Freshness signals: Citations that include document dates let users assess whether the information is current
- Feedback loops: Tracking which sources are cited most frequently reveals which documents are most valuable, informing corpus curation
Treat attribution as a load-bearing part of the architecture, not a UI garnish. A RAG system without trustworthy citations is a generative system pretending to be a retrieval system, which is the worst of both worlds.
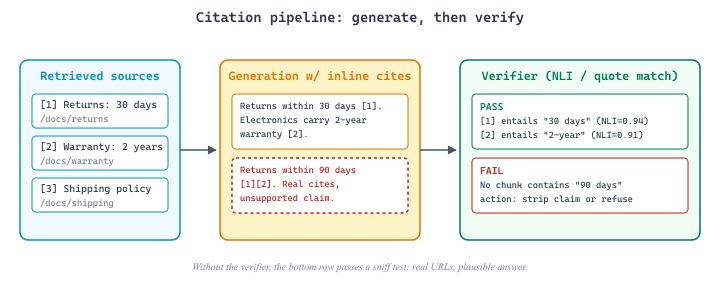
A model can generate a citation to a real source while stating something the source does not actually say. This is citation hallucination, one of the most dangerous failure modes because it creates false confidence. Every attribution system needs a verification layer, not just a generation layer.
Concrete example: a user asks "what is the return window for electronics?" The retriever returns Source [1] (Returns Policy: "Items may be returned within 30 days for a full refund") and Source [2] (Warranty Guide: "Electronics carry a 2-year manufacturer warranty"). The model writes "Electronics can be returned within 90 days [1][2]." The "[1][2]" looks authoritative; both sources exist; the URLs work; the user clicks them and sees real policy documents. But 90 days appears in neither source. The model averaged "30 days" and "2 years" into a plausible-sounding middle ground and stapled real citations onto a fake claim. NLI verification would catch this because neither source entails "90 days"; quote-matching would catch it because no chunk contains the string "90 days."
32.5.2 Prompt-Level Attribution Strategies
The simplest approach to attribution is instructing the LLM to cite its sources within the generation prompt. This works surprisingly well with capable models but requires careful prompt design.
Inline Citation with Source IDs
def build_attributed_prompt(query, retrieved_chunks):
"""Build a prompt that instructs the LLM to cite sources inline."""
context_block = ""
for i, chunk in enumerate(retrieved_chunks):
source_id = f"[{i+1}]"
context_block += (
f"Source {source_id}: {chunk['title']}\n"
f" URL: {chunk['url']}\n"
f" Content: {chunk['text']}\n\n"
)
system_prompt = """You are a research assistant. Answer the user's question
using ONLY the provided sources. Follow these citation rules strictly:
1. Every factual claim must have an inline citation like [1], [2], etc.
2. If multiple sources support a claim, cite all of them: [1][3].
3. If no source supports a claim, do not make it. Say "I could not find
information about this in the provided sources."
4. At the end, list all cited sources with their titles and URLs.
5. Never cite a source for a claim it does not actually support."""
return system_prompt, f"Sources:\n{context_block}\nQuestion: {query}"
# Example usage
chunks = [
{"title": "Returns Policy", "url": "/docs/returns", "text": "Items may be returned within 30 days..."},
{"title": "Warranty Guide", "url": "/docs/warranty", "text": "Electronics carry a 2-year warranty..."},
]
system, user_msg = build_attributed_prompt("What is the return window?", chunks)
# LLM output: "Items can be returned within 30 days of purchase [1].
# Electronics also carry a 2-year warranty [2].
#
# Sources:
# [1] Returns Policy - /docs/returns
# [2] Warranty Guide - /docs/warranty"In a 2024 study by Vectara, roughly 15% of RAG citations pointed to real sources but misrepresented what those sources actually said. The system was not lying outright; it was doing the AI equivalent of citing a reference in a term paper without reading past the abstract.
Structured Output with Citation Objects
For programmatic consumption, structured output formats are more reliable than parsing inline citations from free text:
from pydantic import BaseModel
from openai import OpenAI
class Citation(BaseModel):
source_id: int
quote: str # Exact quote from the source that supports the claim
class AnswerStatement(BaseModel):
claim: str
citations: list[Citation]
class AttributedAnswer(BaseModel):
statements: list[AnswerStatement]
unsupported_aspects: list[str] # Parts of the question with no source support
client = OpenAI()
def generate_attributed_answer(query, chunks):
"""Generate a structured answer with per-claim citations."""
context = "\n".join(
f"[Source {i+1}]: {c['text']}" for i, c in enumerate(chunks)
)
response = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[
{"role": "system", "content": (
"Answer the question using only the provided sources. "
"For each statement, include the source ID and an exact "
"quote from that source as evidence. List any aspects of "
"the question that the sources do not address."
)},
{"role": "user", "content": f"Sources:\n{context}\n\nQuestion: {query}"}
],
response_format=AttributedAnswer,
)
return response.choices[0].message.parsed
32.5.3 Post-Generation Citation Verification
Prompt-level attribution tells the model to cite sources, but does not guarantee accuracy. Verification checks whether each citation actually supports its associated claim.
NLI-Based Verification
Citation verification is a classification problem, not a generation problem. Rather than asking another LLM "is this citation correct?" (which introduces more hallucination risk), use a specialized NLI model trained specifically to detect logical relationships between text pairs. These models are smaller, faster, and more reliable for this task than general-purpose LLMs.
Natural Language Inference (NLI) models classify the relationship between a premise (the source text) and a hypothesis (the generated claim) as entailment, contradiction, or neutral. A valid citation should produce an entailment score above a threshold.
from transformers import pipeline
nli = pipeline("text-classification", model="cross-encoder/nli-deberta-v3-large")
def verify_citations(statements, source_texts):
"""Verify that each citation's source actually supports its claim."""
results = []
for stmt in statements:
claim = stmt.claim
for cit in stmt.citations:
source = source_texts[cit.source_id - 1]
# NLI: does the source entail the claim?
result = nli(f"{source}", f"{claim}")
label = result[0]["label"]
score = result[0]["score"]
results.append({
"claim": claim,
"source_id": cit.source_id,
"nli_label": label,
"nli_score": score,
"verified": label == "ENTAILMENT" and score > 0.7
})
return results
# Flag unverified citations for human review or removalQuote Matching Verification
When citations include exact quotes (as in the structured output approach), a simpler verification checks whether the quote actually appears in the source document. Fuzzy string matching handles minor formatting differences:
from rapidfuzz import fuzz
def verify_quote(quote, source_text, threshold=85):
"""Check if a citation quote actually appears in the source."""
# Try exact substring match first
if quote.lower() in source_text.lower():
return {"match": "exact", "score": 100}
# Fall back to fuzzy matching for minor variations
# Slide a window of quote-length across the source
best_score = 0
quote_len = len(quote)
for i in range(len(source_text) - quote_len + 1):
window = source_text[i:i + quote_len]
score = fuzz.ratio(quote.lower(), window.lower())
best_score = max(best_score, score)
if best_score >= threshold:
return {"match": "fuzzy", "score": best_score}
return {"match": "none", "score": best_score}32.5.4 End-to-End Attribution Architectures
Production attribution systems combine multiple strategies into a pipeline:
- Retrieval with provenance metadata: Every chunk carries its source document ID, URL, page number, paragraph index, and ingestion timestamp. This metadata propagates through the entire pipeline.
- Attributed generation: The LLM generates answers with inline citations using structured output (Section 2 above).
- Citation verification: An NLI model or quote-matching pipeline verifies each citation. Unverified citations are either removed or flagged.
- Citation enrichment: Verified citations are enriched with display metadata (document title, section heading, page number, deep link URL) for the frontend.
- Feedback collection: Users can flag incorrect citations, creating a feedback loop for improving retrieval and generation quality.
Granularity Levels
Citation granularity is a critical design decision:
| Granularity | Example Citation | Pros | Cons |
|---|---|---|---|
| Document-level | "Source: Annual Report 2024" | Simple to implement; always available | User must search a large document to verify |
| Page/section-level | "Annual Report 2024, Section 3.2, p. 47" | Reasonable precision; easy to navigate | Requires page/section metadata in chunks |
| Paragraph-level | "Annual Report 2024, p. 47, para. 3" | High precision; fast to verify | Requires fine-grained chunking and indexing |
| Sentence-level + quote | "The revenue grew 15% YoY" (AR 2024, p.47) | Maximally verifiable; builds strong trust | Highest implementation complexity; quote matching needed |
Perplexity AI uses citation-aware RAG: every answer paragraph carries numbered citations [1] [2] back to retrieved sources. Their retrieval stack mixes Google-style web search with custom indexes (academic papers, Reddit, X), and the citation requirement is a structured-output guarantee enforced at generation time. The model is allowed to refuse to answer if it cannot cite confidently. Microsoft Copilot in Bing applies the same pattern (citations rendered as superscript links), and ChatGPT's "Search" mode (rolled out 2024) does too. The structured-output guarantee is what makes the difference between a chatbot and a citable research tool.
ALCE: The Attribution Benchmark
The Automatic LLM Citation Evaluation (ALCE) benchmark (Gao et al., 2023) provides standardized evaluation for attribution quality. It measures:
- Citation precision: What fraction of citations actually support their claims?
- Citation recall: What fraction of claims that should be cited are actually cited?
- Fluency: Does adding citations degrade the natural flow of the response?
ALCE uses NLI models as automated judges. A citation is considered correct if an NLI model classifies the source passage as entailing the associated claim with high confidence. This automated evaluation enables rapid iteration on attribution prompts and architectures without requiring expensive human annotation.
32.5.5 Common Failure Modes
- Citation hallucination: The model invents a plausible citation to a source that does not exist in the retrieved context. Mitigation: constrain citations to a fixed set of source IDs provided in the prompt.
- Citation displacement: The model cites the correct source but for the wrong claim. Mitigation: per-claim verification with NLI.
- Over-citation: Every sentence is cited to every source, making citations meaningless. Mitigation: penalize citation count in the prompt or post-process to remove redundant citations.
- Under-citation: Key claims are generated without attribution, especially for information the model "knows" from pretraining. Mitigation: explicit prompting that all claims must be sourced, with a fallback statement for unsupported claims.
- Stale citations: The cited document has been updated or removed since ingestion. Mitigation: include ingestion timestamps in metadata and periodically re-index.
32.5.6 Integration with Hallucination Detection
Attribution and Section 49.5 (hallucination detection) are complementary. A claim with no valid citation is a candidate hallucination. A claim with a verified citation but low semantic similarity to the source may be a subtle hallucination. Production systems typically combine both:
- Generate answer with citations (this section)
- Verify citations via NLI (this section)
- Run hallucination detection on uncited claims (Section 49.5)
- Score overall answer faithfulness using evaluation frameworks (RAGAS, DeepEval)
- Source attribution is not optional for production RAG systems; it enables users to verify claims and builds trust.
- Combine inline citations with NLI-based verification for both readability and programmatic accuracy checking.
- Attribution granularity should match the use case: sentence-level for legal or medical, paragraph-level for general Q&A.
- The ALCE benchmark provides a standardized evaluation framework for comparing attribution quality across RAG systems.
Show Answer
Citation hallucination occurs when the model generates a citation to a real source document but the claim is not actually supported by that document. It is dangerous because it creates false confidence: users see a citation and assume the claim is verified, when in fact the model fabricated the association. This is worse than no citation at all, because it actively misleads the user.
Show Answer
Inline citations embed source references directly in the generated text (e.g., [1], [2]), while structured citation objects return a separate data structure mapping each claim to its source document, passage, and confidence score, enabling programmatic verification. Structured output (e.g., Pydantic models with JSON schema) guarantees a parseable format with explicit source IDs and supporting quotes, and makes automated verification straightforward since each citation object can be independently checked.
Show Answer
NLI (Natural Language Inference) models can detect semantic entailment even when the generated text paraphrases the source rather than quoting it verbatim. Quote matching fails when the model rephrases information, which is the common case. NLI models classify the relationship between a premise (source passage) and hypothesis (generated claim) as entailment, contradiction, or neutral; only entailment supports the citation.
Show Answer
ALCE (Automatic LLM Citation Evaluation) measures how well language models attribute their outputs to source documents. It matters because it provides a standardized way to compare attribution quality across different RAG implementations.
Exercises
Some teams treat source attribution in RAG as a nice-to-have UI feature. (a) List three concrete product or compliance reasons it's load-bearing. (b) Why is "the model says it cites source X" not the same as "the answer is grounded in source X"? (c) What architectural change is needed to close that gap?
Answer Sketch
(a) Reasons: (i) regulatory requirements (EU AI Act, healthcare, legal contexts) increasingly require traceable provenance; (ii) trust and adoption by domain experts depend on click-through verification; (iii) bug isolation: when an answer is wrong, citations let you immediately see whether the retriever or the generator failed. (b) Models can hallucinate citations: emit "[1]" markers that point to plausible-sounding sources but which were never actually used in producing the answer. The marker is decorative, not load-bearing. (c) Close the gap with post-generation verification: for each cited claim, retrieve the cited source and run an entailment check (does source X actually entail claim C?). Failed checks mean the citation is removed or the claim is flagged. This shifts citation correctness from a model-trust assumption to a verifiable gate.
You add "Cite each claim with the source ID" to your prompt. Predict: (a) what fraction of generated claims will be cited; (b) the false-citation rate (claims that cite a source that doesn't actually support them); (c) which one of these moves substantially with model size.
Answer Sketch
(a) Frontier models comply with citation instructions ~80-95% of the time on factual questions; weaker models drop to 50-70%. Compliance is high but never universal. (b) False-citation rate is typically 10-30% even for frontier models; the model has a strong prior to attach a marker that "looks right" rather than verifying. (c) Compliance scales well with size; false-citation rate barely improves. This is because false citation is a calibration problem, not a capability problem: even GPT-4 confidently mis-attributes a claim to the most plausible-looking nearby source. The fix is post-generation verification, not better prompting.
Sketch a 10-line function that takes (answer_text, retrieved_docs, citations) where citations is a list of (claim_span, doc_id) pairs, and returns a verified-claims list with confidence scores. Use a small NLI model.
Answer Sketch
from transformers import pipeline
nli = pipeline("zero-shot-classification", model="MoritzLaurer/DeBERTa-v3-base-mnli-fever-anli")
def verify(answer, docs_by_id, citations):
verified = []
for claim, doc_id in citations:
premise = docs_by_id[doc_id].text
r = nli(premise + " [SEP] " + claim, candidate_labels=["entails", "contradicts", "neutral"])
label, score = r["labels"][0], r["scores"][0]
verified.append({"claim": claim, "doc_id": doc_id, "verdict": label, "score": score})
return verifiedThis returns per-claim entailment evidence. In production, claims with verdict "entails" + score > 0.7 get rendered with a green check; "contradicts" or low-confidence get the citation stripped or flagged. NLI models are 100-1000x cheaper than running a frontier LLM as judge and are good enough for this verification task.
List four ways your RAG citations can be technically present but functionally broken, and propose one mitigation for each.
Answer Sketch
(1) Cited but unsupported: marker [3] is attached to a claim source 3 doesn't actually entail. Mitigation: post-gen NLI verification (above). (2) Stale source: cited document was updated after the answer was generated; the user clicks and sees different content. Mitigation: snapshot or version the retrieved chunk, and surface a "based on data as of..." timestamp. (3) Citation collapse: model attaches all citations at the end of a paragraph rather than per-sentence. Mitigation: span-level prompting, or post-hoc sentence segmentation with per-sentence verification. (4) Missing citations on inferred claims: the model derives a claim by combining sources and cites neither. Mitigation: include "every claim must have a citation; uncited claims will be removed" in the prompt and strip uncited sentences from the answer. The recurring lesson: citation must be enforced by the system, not requested from the model.
Fine-grained attribution research is exploring token-level and span-level source linking, where each phrase in a generated answer traces back to a specific passage and character offset in the source. Multi-document attribution extends citation to claims that synthesize information from multiple sources, requiring the system to cite all contributing documents. Self-attributed generation trains models to produce citations as part of their generation process rather than as a post-hoc verification step, improving both accuracy and efficiency. Research into attribution for chain-of-thought reasoning aims to verify not just the final answer but each intermediate reasoning step.
What Comes Next
This concludes the RAG chapter. In Chapter 37: Building Conversational AI Systems, we apply the retrieval and generation techniques covered throughout this chapter to build complete conversational systems with memory, context management, and multi-turn dialogue.