"Without data, you're just another person with an opinion. Without evaluation, you're just another model with a prediction."
Eval, Chronically-Skeptical AI Agent
You have built something (Parts III-VIII). How do you know if it works? This chapter is the eval chapter: classical metrics, LLM-as-judge, eval-driven quality gates, observability, OpenTelemetry, long-context benchmarks, and the experimental rigor that separates "ships features" from "ships working features." Eval is the most under-invested part of every team's LLM stack; this chapter is the corrective.
Chapter Overview
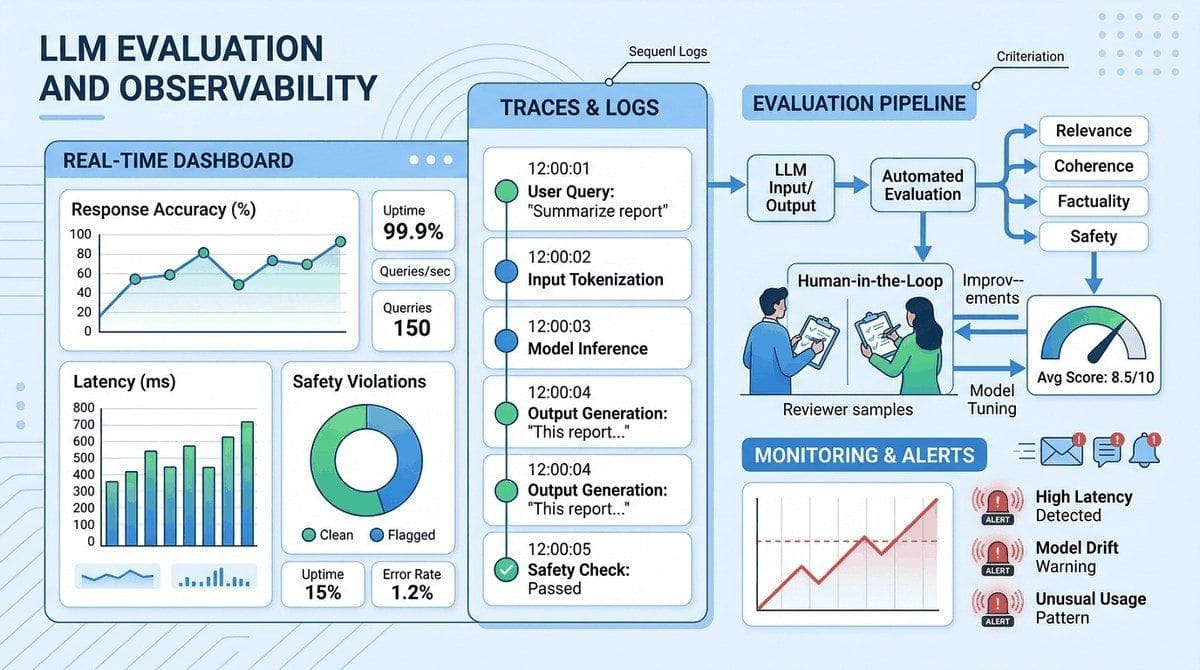
Building LLM applications is only half the challenge; knowing whether they actually work is the other half. Unlike traditional software where correctness is binary, LLM outputs are probabilistic, subjective, and context-dependent. A model that performs brilliantly on one prompt may fail catastrophically on a slight rephrasing. This fundamental uncertainty makes rigorous evaluation, principled experiment design, and continuous observability essential for every LLM project.
This chapter covers the complete evaluation and monitoring lifecycle. It begins with core evaluation metrics (perplexity, BLEU, ROUGE, BERTScore, LLM-as-Judge) and standard benchmarks (MMLU, HumanEval, MT-Bench, Chatbot Arena). It then addresses experimental design with statistical rigor, including bootstrap confidence intervals, paired tests, and ablation studies. Specialized evaluation for RAG and agent systems follows, covering RAGAS metrics, trajectory evaluation, and frameworks like DeepEval and Phoenix.
The chapter also covers testing strategies for LLM applications (unit tests, red teaming, prompt injection testing, CI/CD integration), evaluation-driven quality gates, and arena-style evaluation with Elo ratings. Advanced topics include LLM-as-Judge reliability and debiasing, long-context benchmarks (Needle-in-a-Haystack, RULER, LongBench), human feedback tooling, research methodology for LLM papers, and inference performance benchmarking across hardware platforms. Observability, monitoring, and reproducibility practices are covered in the companion sections later in this chapter.
You cannot improve what you cannot measure. This chapter covers LLM evaluation methods including automated metrics, human evaluation, and LLM-as-judge approaches. The evaluation frameworks here apply to every system built in this book, from simple API calls to complex multi-agent pipelines.
- Select and compute appropriate evaluation metrics for different LLM tasks (generation, retrieval, reasoning, code)
- Design statistically rigorous experiments with bootstrap confidence intervals, paired tests, and proper ablation controls
- Evaluate RAG pipelines using RAGAS metrics and agent systems using trajectory-based evaluation
- Build automated test suites for LLM applications including unit tests, integration tests, and red-team adversarial tests
- Instrument LLM applications with distributed tracing using LangSmith, Langfuse, or Phoenix
- Detect and respond to prompt drift, model version drift, and embedding drift in production systems
- Implement reproducibility practices including prompt versioning, config management, and experiment tracking
- Integrate evaluation into CI/CD pipelines using assertion-based testing and promptfoo
- Design quality monitoring dashboards with alerting for production LLM applications
- Use arena-style evaluation with Elo ratings and pairwise comparison for model ranking
- Navigate evaluation harness ecosystems including lm-eval-harness, HELM, and BigBench for systematic model comparison
- Identify and mitigate LLM-as-Judge biases (position bias, verbosity bias, self-enhancement) for reliable automated evaluation
- Evaluate long-context models using Needle-in-a-Haystack, RULER, and LongBench benchmarks
- Benchmark LLM inference performance (TTFT, TPOT, throughput) across GPU, TPU, and alternative hardware
Prerequisites
- Chapter 11: LLM APIs (chat completions, message formatting, model parameters)
- Chapter 12: Prompt Engineering (prompt design, structured outputs, chain-of-thought)
- Chapter 32: Retrieval-Augmented Generation (embedding search, vector stores, RAG pipelines)
- Chapter 26: AI Agents (agent architectures, tool use, planning patterns)
- Familiarity with Python testing frameworks (pytest) and basic statistics
Sections
- 42.1 LLM Evaluation Fundamentals You cannot improve what you cannot measure, and measuring LLM quality is surprisingly hard. Entry
- 42.2 Experimental Design & Statistical Rigor Claiming that Model A outperforms Model B on a benchmark means nothing without statistical evidence. Entry
- 42.3 Testing LLM Applications LLM applications need automated testing just as much as traditional software, but the testing strategies are fundamentally different. Intermediate
- 42.4 LLM-Specific Monitoring & Drift Detection LLM applications degrade silently. Intermediate
- 42.5 Evaluation-Driven Quality Gates Using evaluation metrics as automated deployment gates, regression testing, and continuous quality assurance for LLM applications. Intermediate
- 42.6 Observability & Tracing You cannot debug what you cannot see. Intermediate
- 42.7 LLM Experiment Reproducibility Reproducibility in LLM experiments is harder than in traditional ML, and also more important. Intermediate
- 42.8 Long-Context Benchmarks and Context Extension Methods The "context length" listed on a model card is a theoretical maximum, not a guarantee of effective utilization. Intermediate
- 42.9 OpenTelemetry for LLM Applications OpenTelemetry instrumentation for LLM apps: API calls, trace propagation, token tracking, and OpenLLMetry auto-instrumentation. Intermediate
- 42.9a OTel Dashboards for LLM Operations Building OpenTelemetry dashboards for latency, token usage, cost attribution, error tracking, and SLO panels. Intermediate
- 42.10 Research Methodology for LLM Papers Rigorous methodology separates LLM science from LLM folklore. Advanced
- 42.11 Structured-Output Validity Testing By 2026 most production LLM traffic is not free-form text, it is structured output. Advanced
- 42.12 Classical ML Evaluation Metrics For a comprehensive discussion of evaluation methodology, train/validation/test splits, and cross-validation, see Section 42.12: ML Basics: Features, Optimization & Generalization. Advanced
Objective
Stand up a reusable evaluation harness using inspect-ai (the AISI framework) that scores an LLM on a custom dataset with both standard and custom metrics. By the end you will have a CI-runnable eval suite, plus a clear feel for the difference between leaderboard metrics and what you actually need to track.
Steps
- Step 1: Define the task. Pick something narrow: "summarize a news article in 3 sentences" or "answer a coding interview question." Curate 50 high-quality examples in
tasks.jsonl. - Step 2: Install Inspect.
pip install inspect-ai. Write a task in the@taskdecorator pattern: solver =generate(), scorer =model_graded_qa(). - Step 3: Run baseline.
inspect eval my_task.py --model openai/gpt-4o-mini. View the report in the Inspect UI. Note overall accuracy. - Step 4: Add a custom metric. Define a custom scorer that combines: (a) F1 of key entities present, (b) ROUGE-L, (c) length penalty for >120 words. Register it with
@scorer. - Step 5: Multi-model sweep. Re-run against 3 models (gpt-4o-mini, claude-haiku-4.6, llama-3.3-70b via Together). Generate a comparison table with all metrics.
- Step 6: Wire into CI. Add a GitHub Action that runs
inspect evalon every PR, fails if the score drops >5 points. This is the regression-evals pattern Chapter 44 builds on.
Expected Output
Expected time: 3 hours. Difficulty: intermediate. Artifact: a Git-versioned eval suite + CI integration.
What's Next?
Next: Chapter 43: Specialized Evaluation, RAG, Agents, Multimodal, Long-Context. The metrics in Chapter 42 (BLEU, ROUGE, accuracy, perplexity) were designed for the pre-LLM world and quietly miss what matters in 2026. Chapter 43 covers the new evaluation surface: RAG faithfulness and groundedness, agentic trajectory eval, code-gen pass@k, multimodal grounding, and the long-context benchmarks (Needle-in-a-Haystack, RULER) that expose the gap between context-window-marketing and context-window-reality.