"Half of search is reading what the user typed. The other half is reading what they meant."
Pixel, Curious Librarian Agent
Entry point (A) from Section 38.1 sits at the very front of the pipeline. Before the candidate generator can retrieve, before the ranker can score, the system has to turn the user's natural-language ask into something a structured retriever can consume. An LLM is unusually good at three steps in that translation: expanding a short query into a richer one, classifying the intent behind the query, and filling structured slots from free text. This section walks through each step with production-ready code.
A user types "comfy headphones for the gym." The catalog stores them under "ATH-M50xBT2 (Black, On-Ear, Bluetooth 5.3)." These two strings have roughly the same number of overlapping characters as English and Old Norse. Classical retrievers either translate badly or politely return nothing. The LLM acts as a bilingual concierge: it hears "comfy gym" and whispers to the catalog "sweat-resistant, secure fit, under 50 grams, wireless." Query understanding is essentially marriage counseling between humans who use adjectives and databases that only respect facets. The session ends with a JSON object, which is the database equivalent of "I love you too."
Prerequisites
This section assumes the reader has finished Section 38.1 (the four LLM entry points into recsys) and is comfortable with structured-output prompting from the prompt-engineering chapter and with the basic retrieval-augmented generation pipeline from Part VII.
38.2.1 The Query Understanding Problem
A user types "wireless headphones under $200 with noise cancelling." A traditional product search would tokenize the string, match keywords against an inverted index, and apply a price filter parsed by a regex. Five things go wrong. The retriever does not know that "wireless" and "Bluetooth" are synonyms in this catalog. It does not know whether the user is browsing (informational intent) or ready to buy (transactional intent). It does not know that "$200" is a maximum, not a target. It does not know that "noise cancelling" is a specific product attribute that has its own facet in the catalog. And it does not know that headphones come in over-ear, on-ear, and in-ear variants that the user did not specify and might need to be asked about.
An LLM-based query understanding layer attacks all five gaps in a single pass. It rewrites the query into a richer canonical form (query expansion), classifies the intent so downstream ranking can weight commercial signals appropriately (intent classification), and pulls out structured slots that the catalog facets can directly consume (slot filling). The output is a JSON object the rest of the pipeline can consume without further natural-language processing. Figure 38.2.1 shows the pipeline.
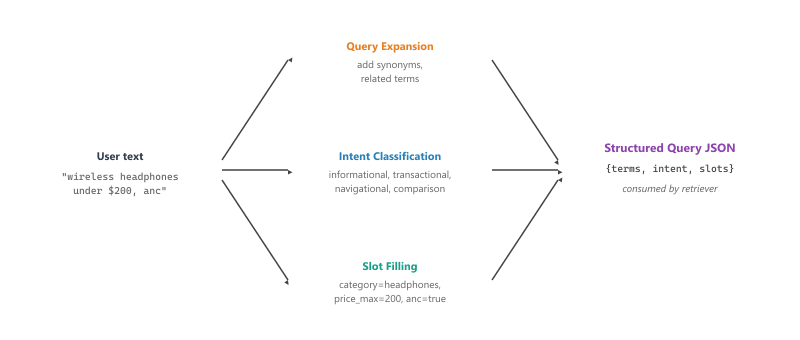
38.2.2 Query Expansion and Reformulation
Query expansion adds synonyms and related terms to a short query so that a lexical or hybrid retriever can match more relevant items. Classical expansion uses thesauri (WordNet), pseudo-relevance feedback (treat the top-k documents as expansion sources), or click-through logs. LLM-based expansion produces better results in three ways. The terms are catalog-aware when the LLM is prompted with examples from the catalog. The terms preserve the user's likely intent (an LLM understands that "running shoes" expanded to "track spikes" is wrong if the user mentioned a marathon). And the expansion handles compositional queries the classical methods cannot ("noise-cancelling Bluetooth headphones for plane travel" needs an LLM to understand that "for plane travel" implies battery life is a relevant facet).
The simplest LLM expansion is a prompt that asks for 5 to 10 paraphrases plus 5 to 10 related entity terms, returned as JSON. The expanded query is then sent to a hybrid retriever (BM25 plus dense embeddings), and the original query is kept as a strong signal alongside the expansions.
from openai import OpenAI
import json
client = OpenAI()
EXPAND_SYSTEM = """You expand product-search queries for an e-commerce site.
Given the raw user query, return STRICT JSON with two fields:
"paraphrases": 5 alternative phrasings preserving intent.
"related_terms": 5 attribute or entity terms a shopper might also want.
Do not invent product brands. Do not add intent or preference words the user did
not imply. Return ONLY the JSON object, no commentary."""
def expand_query(raw: str) -> dict:
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": EXPAND_SYSTEM},
{"role": "user", "content": raw},
],
response_format={"type": "json_object"},
temperature=0.2,
)
return json.loads(resp.choices[0].message.content)
print(expand_query("wireless headphones under $200 with noise cancelling"))
# {"paraphrases": ["bluetooth over-ear headphones with anc below 200 dollars", ...],
# "related_terms": ["active noise cancellation", "battery life", "transparency mode", ...]}
Code Fragment 38.2.1b: LLM-based query expansion. The system prompt insists on JSON output with a fixed schema and forbids the model from inventing brands or adding intent words the user did not imply. Temperature is low to keep the expansion stable across reruns.
The single largest failure mode of LLM query expansion is drift: the model adds terms that look reasonable but change the intent. "Running shoes" expanded to "trail runners and hiking boots" pulls the retrieved set into a different category. Two guards help. First, keep the original query as one of the retrieved-query variants and weight it more heavily than expansions. Second, log the expansions in an offline harness and review the top 100 expansions per week for drift. A weekly review caught the "running shoes to hiking boots" drift in one team's pipeline before it shipped.
38.2.3 Intent Classification
The information retrieval community has long taxonomized queries into three or four buckets. Andrei Broder's 2002 taxonomy is the classical version: informational (the user wants to learn something), navigational (the user wants a specific known site or page), and transactional (the user wants to do something, often buy). E-commerce teams add a fourth: comparison (the user is weighing two or more products against each other).
Intent matters because the downstream ranker should weight features differently for each bucket. A transactional query benefits from boosting in-stock items and items with high conversion rates. An informational query benefits from boosting tutorial or review pages. A comparison query should boost items in the same price bracket and category as the explicitly named comparator.
Before LLMs, intent classifiers were small text classifiers trained on labeled query logs. They worked well on common queries and poorly on the long tail. A few-shot LLM classifier covers the long tail without retraining and ships with a confidence score the system can use to route ambiguous queries.
from openai import OpenAI
import json
client = OpenAI()
INTENT_SYSTEM = """Classify the search-query intent into exactly one of:
- informational: user wants to learn (reviews, guides, comparisons in general)
- navigational: user wants a specific known brand, model, or page
- transactional: user is ready to buy or take action
- comparison: user is weighing two or more specific items
Return STRICT JSON: {"intent": "...", "confidence": 0.0 to 1.0, "reason": "..."}.
Examples:
"best wireless earbuds 2026" -> informational, 0.9
"sony wh-1000xm5" -> navigational, 0.95
"buy refurbished iphone 14 pro 256gb" -> transactional, 0.95
"airpods pro vs sony wf-1000xm5" -> comparison, 0.95"""
def classify_intent(query: str) -> dict:
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": INTENT_SYSTEM},
{"role": "user", "content": query},
],
response_format={"type": "json_object"},
temperature=0.0,
)
return json.loads(resp.choices[0].message.content)
print(classify_intent("wireless headphones under $200 with noise cancelling"))
# {"intent": "transactional", "confidence": 0.85,
# "reason": "explicit price ceiling and required feature suggest the user is shopping."}
Code Fragment 38.2.2: Few-shot LLM intent classifier. Four labeled examples in the system prompt cover the four intent buckets. The confidence score lets the downstream router fall back to a clarifying question when the LLM is uncertain.
Intent rarely changes for the same query, so the call is a near-perfect caching target. A simple Redis key of the form intent:<sha1(query)> with a 7-day TTL cuts the LLM call count by an order of magnitude on a real production traffic shape, because the head of the query distribution is heavily repeated. Cache the slot-fill output too.
38.2.4 Slot Filling for Structured Queries
Slot filling extracts attribute-value pairs from free text into a structured object the catalog already understands. The pre-LLM approach combined a named entity recognizer (Section 1.4) with a rule-based normalizer (Pendlebury's regex for prices, dateutil for dates). The result was brittle: "$200 or less," "below $200," "two hundred bucks," and "under two C-notes" all mean the same price ceiling but defeat the regex.
An LLM with a well-specified schema handles all four phrasings. The cost is one extra inference call, plus the cost of the schema design work. The savings are the elimination of an entire NER plus normalization pipeline plus the long tail of phrasings it could never cover.
from openai import OpenAI
import json
client = OpenAI()
SLOT_SCHEMA = {
"category": "headphones | speakers | laptops | phones | other",
"subcategory": "over-ear | on-ear | in-ear | true-wireless | null",
"price_min": "number or null (USD)",
"price_max": "number or null (USD)",
"brand": "string or null",
"must_have_features": "list of strings, drawn from {anc, transparency, ipx7, foldable, 30h+ battery, wireless, microphone, multipoint}",
"exclude_features": "list of strings, same vocabulary",
"use_case": "string or null (e.g., 'plane travel', 'office calls', 'gym')",
}
SLOT_SYSTEM = f"""Extract structured slots from a product-search query.
Schema (return STRICT JSON with these keys only):
{json.dumps(SLOT_SCHEMA, indent=2)}
Normalize all monetary amounts to USD numbers.
Map informal phrasings to canonical feature names: "noise cancelling" -> "anc",
"sweat resistant" -> "ipx7", "long battery" -> "30h+ battery".
Set a slot to null if the user did not mention it. Do not invent values."""
def fill_slots(query: str) -> dict:
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": SLOT_SYSTEM},
{"role": "user", "content": query},
],
response_format={"type": "json_object"},
temperature=0.0,
)
return json.loads(resp.choices[0].message.content)
print(fill_slots("wireless headphones under $200 with noise cancelling"))
# {"category": "headphones", "subcategory": null, "price_min": null,
# "price_max": 200, "brand": null,
# "must_have_features": ["anc", "wireless"], "exclude_features": [],
# "use_case": null}
Code Fragment 38.2.3: LLM slot filling. The schema is inlined into the system prompt so the model sees the exact vocabulary it must use. The normalization rules ("noise cancelling" to "anc") would otherwise live in a brittle regex layer.
Three separate LLM calls add latency. In production, the expansion, intent, and slot-fill tasks are usually fused into a single call with a combined JSON output. Latency drops to one LLM round trip, cost drops by roughly two thirds, and the prompts share a single set of few-shot examples. The fused prompt is harder to debug because a failure in one task can corrupt the JSON for all three, so keep the separated prompts available as a fallback that the router can switch to when the fused call fails to parse.
38.2.5 From Structured Query to Retrieval
Once the three LLM steps produce their outputs, the downstream pipeline consumes them as follows. The expanded query terms feed a hybrid dense plus sparse retriever. The intent label routes between rankers tuned for each intent bucket. The filled slots become hard filters (category, price range) and soft boosts (must-have-features) on the retriever. The same retrieval-as-recsys pattern from Chapter 32 applies: the candidate set comes from a cheap retriever, an LLM (or a learned reranker) reorders the top fifty.
The query-rewriting prompt patterns in this section are direct cousins of the HyDE (Hypothetical Document Embeddings) and Multi-Query Retrieval patterns covered for RAG in Section 32.5. The recsys-specific twist is the structured slot output, which RAG usually does not need.
If the rest of the pipeline already uses llama-index, the filled slots can drive a custom NodePostprocessor that drops candidates failing hard filters and boosts those matching soft preferences. This keeps the slot-fill output inside the framework rather than bolted on the side, and the post-processor composes with other rerankers (cross-encoder, MMR).
langchain.chains.query_constructorIf the pipeline lives in LangChain instead, langchain.chains.query_constructor ships a ready-made structured-query extractor. Declare a list of AttributeInfo entries naming the catalog facets (category, price, brand, must-have-features) plus their types and allowed values, hand the LLM a content description, and the chain emits a typed StructuredQuery object that combines a free-text portion (for dense retrieval) with a typed Filter tree (for hard catalog filters). It is the LangChain-native equivalent of Code Fragment 38.2.3 and saves the schema-handcoding step at the cost of accepting the framework's vocabulary of comparators and operators. The Self-Query Retriever in LangChain composes on top of query_constructor for the end-to-end retrieve-and-filter pattern.
38.2.6 When to Ask a Clarifying Question
The intent classifier returns a confidence score, the slot filler can detect missing required slots, and the expansion can flag ambiguous polysemy ("python" the language or the snake?). When any of those signals fires, the right move is to ask a clarifying question rather than to run the retriever on a fuzzy query. The clarifying-question generator is yet another LLM call, prompted with the partial structured query and asked to phrase the smallest follow-up that resolves the ambiguity. Section 38.4 develops the full conversational pattern; for now, treat the clarifying question as the natural fallback when query understanding flags low confidence.
Suppose a user types "blue dress." Which of the three LLM steps in Figure 38.2.1 should fire most strongly? Why might the structured query alone not be enough, and what clarifying question would resolve the ambiguity?
Show Answer
Slot filling captures category=dress and color=blue, but it cannot resolve the much larger missing dimensions: occasion (wedding, work, beach), size, price range, and length. Query expansion adds the wrong synonyms ("navy," "cobalt," "teal") if the user actually meant a specific shade. Intent classification probably returns "transactional, low confidence." The right next move is a clarifying question that targets the most retrieval-relevant missing slot. For dresses, that is usually "what is the occasion?", because occasion is a coarse partition of the catalog that collapses many other ambiguities at once.
Query and intent understanding is the cheapest LLM entry point into a recsys: it touches a single string at the front of the pipeline and produces a structured object the rest of the system already knows how to consume. The three jobs (expansion, intent classification, slot filling) can be three separate calls or one fused call. The output replaces three legacy components (thesaurus expansion, hand-coded intent classifier, NER plus normalizer) and handles the long tail of phrasings that defeated them.
What Comes Next
The next section, Section 38.3: LLMs for Item-Side Enrichment, moves to entry point (B). The query side is now structured. The remaining problem is that the catalog itself is often too sparse for a content-based retriever to do its job. Section 38.3 covers the LLM enrichment passes that turn a one-line product record into the dense, descriptive text that an embedding model can actually work with.