"Without provenance, a model is just a binary blob. With provenance, it becomes an asset you can govern."
Matei Zaharia, MLflow design notes, 2018
A model registry bridges the gap between experimentation and production. It provides a centralized catalog of trained models, each with version history, metadata, lineage back to training runs, and a promotion workflow that controls which model version serves live traffic. This section covers registry patterns in both W&B and MLflow, automated validation gates, CI/CD integration for model deployment, and strategies for managing the full lifecycle of LLM artifacts.
Prerequisites
This section assumes familiarity with W&B and MLflow tooling from Section 19.11 and with LLM evaluation fundamentals from Section 42.1. Familiarity with LoRA fine-tuning from Section 13.1 helps make sense of the adapter-versioning examples.
44.1.1 Why a Model Registry Matters
Weights & Biases was founded in 2017 by Lukas Biewald and Chris Van Pelt, both of whom had previously sold CrowdFlower (now Figure Eight) to Appen. The product's distinctive ability to log arbitrary objects as "artifacts" was reportedly designed in a single late-night session because Lukas was frustrated that he could not check pickle files into Git without breaking the diff view.
During experimentation, models live as checkpoint files scattered across training runs. That works for research, but production systems need a single source of truth: which model is currently serving, which version it replaced, who approved the transition, and what evaluation results justified the promotion. A model registry answers all of these questions.
Without a registry, teams fall into common failure modes. Engineers copy checkpoint paths into deployment configs by hand. Nobody knows which training run produced the model currently in production. Rollbacks require digging through experiment logs to find the previous best checkpoint. A registry eliminates these problems by formalizing the path from training to serving.
44.1.2 W&B Model Registry
W&B provides a model registry built on top of its Artifacts system (see Section 19.11 (Libraries & Frameworks)). You register a model by linking an artifact to a named collection, then promote versions through aliases that indicate readiness.
import wandb
# Step 1: Log the model artifact during training
run = wandb.init(project="llm-fine-tuning", job_type="training")
model_artifact = wandb.Artifact(
name="chatbot-lora-v2",
type="model",
description="LoRA-tuned Llama-3 for customer support",
metadata={
"base_model": "meta-llama/Llama-3-8B",
"lora_rank": 16,
"val_loss": 0.342,
"val_accuracy": 0.918,
"training_tokens": 12_500_000,
},
)
model_artifact.add_dir("checkpoints/best/")
run.log_artifact(model_artifact)
# Step 2: Link the artifact to a registered model collection
run.link_artifact(
artifact=model_artifact,
target_path="my-team/model-registry/chatbot-production",
)
run.finish()metadata dict embeds val_loss and val_accuracy at registration time so promotion decisions can read them later without re-running eval.Once linked, the model appears in the W&B Model Registry UI. Each version inherits the metadata and lineage from the original artifact, so you can trace any registered version back to the exact training run, dataset, and hyperparameters that produced it.
44.1.3 W&B Aliases and Promotion
W&B uses aliases to mark the status of model versions. Common aliases include staging, production, and candidate. Unlike fixed stages, aliases are flexible: you can define any naming scheme that fits your workflow.
import wandb
api = wandb.Api()
# Fetch the registered model collection
collection = api.artifact_collection(
type_name="model",
name="my-team/model-registry/chatbot-production",
)
# Get a specific version and add the "staging" alias
artifact = api.artifact("my-team/model-registry/chatbot-production:v7")
artifact.aliases.append("staging")
artifact.save()
# Later, after validation passes, promote to production
artifact.aliases.append("production")
artifact.save()
# Load the production model by alias
prod_artifact = api.artifact(
"my-team/model-registry/chatbot-production:production"
)
model_dir = prod_artifact.download()
print(f"Production model downloaded to: {model_dir}")staging then production aliases. Loading by alias (:production) is the indirection that lets serving infrastructure ask for "current prod" without hard-coding a version number.Use a "champion/challenger" pattern for safe model transitions. The current production model keeps the champion alias while the new candidate receives challenger. Run both in parallel with shadow traffic (see Section 10.7 (vLLM Deep Dive) on inference serving), and only swap aliases after the challenger proves itself on live data.
44.1.4 MLflow Model Registry in Depth
MLflow's model registry (introduced in Section 19.12 (Libraries & Frameworks)) provides version management with either stage-based transitions or the newer alias system. The registry stores models in MLflow's standard model format, which bundles the model weights, a signature describing input/output schemas, and a conda.yaml or requirements.txt for environment reproduction.
import mlflow
from mlflow import MlflowClient
client = MlflowClient()
# Register a model from an existing run
model_uri = "runs:/abc123def456/model"
result = mlflow.register_model(
model_uri=model_uri,
name="chatbot-lora-production",
tags={
"task": "customer-support",
"base_model": "llama-3-8b",
"framework": "transformers",
},
)
print(f"Registered version: {result.version}")
# Set a model alias (MLflow 2.9+)
client.set_registered_model_alias(
name="chatbot-lora-production",
alias="champion",
version=result.version,
)
# Load the model by alias
champion_uri = "models:/chatbot-lora-production@champion"
model = mlflow.transformers.load_model(champion_uri)register_model on a tracked run URI plus set_registered_model_alias to mark the champion. The models:/name@alias URI scheme is the 2.9+ replacement for the deprecated Staging/Production stage transitions.The alias-based approach is more flexible than fixed stages. You can define aliases like champion, challenger, rollback-target, or ab-test-variant-b, each pointing to a specific version number. Moving an alias to a new version is an atomic operation, which makes deployment transitions safe.
MLflow's legacy stage transitions (Staging, Production, Archived) are deprecated as of MLflow 2.9 and will be removed in a future release. Migrate to the alias-based API now to avoid breaking changes. If your existing pipelines depend on transition_model_version_stage(), plan the migration before upgrading.
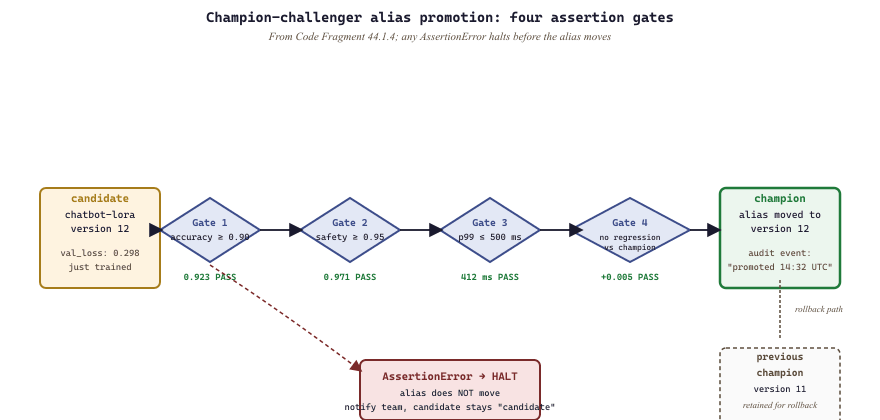
champion alias from version 11 to version 12 in an atomic operation that emits the audit event the section's "Key Insight" callout invokes. Any AssertionError halts before the alias moves, so the registry never advertises a version that failed validation. The previous champion is retained on a dashed rollback path.44.1.5 Automated Validation Gates
Promoting a model to production should not be a manual decision. Instead, build automated validation gates that verify the model meets quality, safety, and performance thresholds before promotion proceeds.
import mlflow
from mlflow import MlflowClient
client = MlflowClient()
def validate_and_promote(model_name: str, candidate_version: int):
"""Run validation checks and promote if all pass."""
model_uri = f"models:/{model_name}/{candidate_version}"
model = mlflow.transformers.load_model(model_uri)
# Gate 1: Core accuracy threshold
accuracy = run_eval_suite(model, dataset="eval_golden_set")
assert accuracy >= 0.90, f"Accuracy {accuracy:.3f} below threshold 0.90"
# Gate 2: Safety evaluation
safety_score = run_safety_checks(model, dataset="safety_test_cases")
assert safety_score >= 0.95, f"Safety score {safety_score:.3f} below 0.95"
# Gate 3: Latency benchmark
p99_latency_ms = run_latency_benchmark(model, num_requests=1000)
assert p99_latency_ms <= 500, f"P99 latency {p99_latency_ms}ms exceeds 500ms"
# Gate 4: Regression check against current champion
champion_uri = f"models:/{model_name}@champion"
champion_accuracy = run_eval_suite(
mlflow.transformers.load_model(champion_uri),
dataset="eval_golden_set",
)
assert accuracy >= champion_accuracy - 0.01, (
f"Candidate {accuracy:.3f} regresses vs champion {champion_accuracy:.3f}"
)
# All gates passed: promote
client.set_registered_model_alias(
name=model_name, alias="champion", version=candidate_version,
)
print(f"Version {candidate_version} promoted to champion")
validate_and_promote("chatbot-lora-production", candidate_version=12)AssertionError halts promotion before set_registered_model_alias runs, so the registry never advertises a version that failed validation.Each gate checks a different dimension. Accuracy validates the model's core capability. Safety checks guard against harmful outputs (see Chapter 11 on safety and alignment). Latency benchmarks ensure the model meets serving SLAs. The regression check prevents promoting a model that is worse than the current production version. If any gate fails, the promotion halts and the team is notified.
44.1.6 CI/CD Integration
The registry decides which model version is current (via aliases such as champion or candidate). CI/CD picks up that decision and rolls it out: pull the candidate, run the same validation gates from 44.1.5, build a serving image, and deploy. The pipeline plumbing is conventional GitHub Actions (or GitLab CI / Jenkins / Argo Workflows); the LLM-specific part is the validation step, which calls the same validate_and_promote() assertions that the registry-side promotion uses. Keeping that policy in one Python file (rather than duplicating in two YAML files) is what prevents "the registry says promote but CI rejects" drift.
A minimal model-deployment workflow has three stages: (1) load the candidate version from the registry, (2) run the validation suite (accuracy, safety, latency), exit non-zero on any failure, (3) build the serving container and roll out to staging. Rollbacks are straightforward in the same model: point the registry alias back to the previous version and rerun the workflow. The CI YAML and the validate_model.py helper live alongside training code in .github/workflows/ and scripts/, versioned in the same repo so the gating logic moves with the model.
MLflow's mlflow models build-docker command creates a self-contained Docker image with the model, dependencies, and a REST API endpoint. For LLMs that require GPU inference, you will typically use a custom serving image based on vLLM or TGI instead (see Section 10.7 (vLLM Deep Dive) on inference serving). The registry still manages version tracking and promotion; only the serving infrastructure differs.
44.1.7 LLM-Specific Registry Considerations
Large language models introduce challenges that traditional ML model registries were not designed for. A fine-tuned LLM checkpoint can be 15 GB or more, adapter weights add another layer of versioning on top of the base model, and prompt templates are part of the model's effective behavior but live outside the weights.
To handle these challenges, adopt a layered versioning strategy. Register the base model once as a shared artifact. Register adapter weights (LoRA, QLoRA) as separate, lightweight artifacts that reference the base model version. Store prompt templates and system instructions alongside the adapter weights so that the complete "model" (base + adapter + prompts) is versioned as a unit.
import wandb
run = wandb.init(project="llm-registry", job_type="register")
# Register adapter weights separately from the base model
adapter_artifact = wandb.Artifact(
name="customer-support-adapter",
type="model-adapter",
metadata={
"base_model": "meta-llama/Llama-3-8B",
"base_model_version": "v1.0",
"adapter_type": "lora",
"rank": 16,
"target_modules": ["q_proj", "v_proj", "k_proj", "o_proj"],
"val_loss": 0.298,
},
)
adapter_artifact.add_dir("adapters/customer-support/")
# Include the prompt template as part of the artifact
adapter_artifact.add_file("prompts/system_prompt.txt")
adapter_artifact.add_file("prompts/few_shot_examples.json")
run.log_artifact(adapter_artifact)
run.link_artifact(
artifact=adapter_artifact,
target_path="my-team/model-registry/cs-adapter-prod",
)
run.finish()base_model_version metadata field is the hash pin that prevents the base-model-drift bug described in the next warning.This layered approach keeps artifact sizes manageable. When you update the prompt template without retraining, you create a new adapter artifact version that bundles the same weights with the updated prompts. When you retrain the adapter, the new version references the same base model. The registry tracks the full lineage in both cases.
44.1.8 Deployment Patterns Summary
The table below summarizes common deployment patterns and when to use each one. The right choice depends on your risk tolerance, traffic volume, and how quickly you need to detect regressions.
| Pattern | Description | Best For |
|---|---|---|
| Blue/Green | Two identical environments; switch traffic atomically | Low-risk transitions with instant rollback |
| Canary | Route a small percentage of traffic to the new model | Gradual rollouts with real-time monitoring |
| Shadow | New model receives live traffic but responses are discarded | Validating latency and output quality before any user impact |
| A/B Test | Split traffic between models and measure business metrics | Comparing user-facing impact of different model versions |
Blue-green deployment runs two complete, identical environments side by side. Blue serves all live traffic while green is brought up with the new model version and warmed (weights loaded, caches primed, health checks green). Promotion is a single atomic change at the load balancer or router: traffic flips from blue to green in one step rather than draining gradually. Because blue stays running and untouched, rollback is just flipping the pointer back, giving near-instant recovery if green misbehaves. The trade-off is cost: you pay for double the serving capacity during the overlap, which is steep for GPU-bound LLM replicas, so blue-green suits high-stakes, low-frequency model swaps where instant rollback matters more than hardware efficiency.
Regardless of the deployment pattern, the model registry remains the single source of truth. The serving infrastructure reads the current alias (e.g., champion) from the registry and loads the corresponding model version. Changing the alias triggers a redeployment, and the full history of alias transitions provides an audit trail.
The reference for tracking, versioning, and promoting model artifacts across the LLM lifecycle. A registry answers four questions: what is in production right now? how did it get there? can I roll back? what trained it? We cover MLflow, Weights & Biases Registry, Hugging Face Hub, Vertex AI Model Registry, and SageMaker Model Registry, plus the LLM-specific twist that prompts and LoRA adapters are now first-class artifacts alongside weights.
The conceptual treatment of production engineering and lifecycle management lives in Chapter 62 (Production Engineering). This section is the practitioner reference: the exact MLflow API calls for promoting a model, the difference between W&B's run-linked registry and MLflow's standalone one, why Hugging Face Hub is the de facto registry for open weights, and when the cloud-provider offerings (Vertex, SageMaker) are worth using. Cross-references to Section 19.11 (Libraries & Frameworks) for the upstream training-side and Section 10.7 (Libraries & Frameworks) for the downstream serving-side are flagged inline.
44.1.9 What a Registry Is For
A model registry is the system of record between training and serving. It stores immutable versions of an artifact (weights, an adapter, a prompt, or a bundle of all three), associates each version with metadata (training run, eval scores, lineage), and exposes promotion stages so the serving layer can ask "give me the current production model" rather than encoding a path or a hash. Without a registry, the question "what is running in prod?" requires reading the Kubernetes manifest, ssh-ing into a pod, or grepping a deploy log; with a registry, it is an API call.
For LLM systems, the LLM-specific twist is that the deployable artifact is rarely just weights. It is often a tuple of (base model, LoRA adapter, prompt template, RAG configuration); changing any one of these changes the system's behavior and must be versioned together. A registry that treats prompts as first-class (Langfuse, LangSmith, W&B 2025 LLM extensions) is materially more useful than one that only versions weights. We come back to this below.
44.1.10 Promotion Stages and the Lifecycle Loop
The canonical promotion stages, dating back to MLflow's first registry release in 2019 and adopted by most subsequent tools, are None (just created), Staging (passed offline eval, available for shadow or canary), Production (currently serving), and Archived (retired but kept for audit). Section 44.1.3 above showed the modern alias-based API that has replaced legacy transition_model_version_stage calls; the same four conceptual stages map to aliases candidate, staging, champion, and archived. The transition emits an audit event (who promoted, when, from which version) and the previous champion is retained, so a rollback is a single alias-reassignment API call. Both properties matter when a regulator asks which model was serving on a specific date.
The registry's value is not the storage, S3 already stores artifacts cheaply. The value is the immutable version-to-stage mapping plus the audit trail. If you can answer "what was in production at 14:32 UTC on March 8?" with a single API call, your registry is doing its job; if you cannot, you do not have a registry, you have a folder.
44.1.11 The Five Registries in the 2024-2026 Market
MLflow Model Registry (Apache 2.0) is the OSS default and the most commonly self-hosted option. MLflow 2.x added first-class LLM support in 2024 (prompt logging, RAG logging, eval harness). Use when you want vendor-neutral self-host. Weights & Biases Registry (SaaS + on-prem) couples tightly to W&B Experiments so a registered model carries its full training-run context; 2024-2025 added prompt versioning and LLM-as-judge flows. Use when training is already on W&B. Hugging Face Hub is the de facto registry for open weights: Llama, Mistral, Qwen, DeepSeek, Phi all live on the Hub with Git-LFS storage, model cards, and a download API; enterprise can self-host or use HF Enterprise Hub. Unique among the five, the Hub also versions PEFT adapters and prompt datasets. Vertex AI and SageMaker Model Registry integrate deeply with their serving and pipeline products (one-call deploy, IAM-scoped governance); pick when your stack is already locked to the cloud.
| Registry | License / Hosting | LLM-Specific Features | Best Fit |
|---|---|---|---|
| MLflow | Apache 2.0, self-host or Databricks | Prompt logging, eval harness (2024+) | Vendor-neutral, multi-cloud |
| W&B Registry | SaaS + on-prem option | Run-linked context, prompt versioning | W&B-centric training shops |
| Hugging Face Hub | SaaS + Enterprise self-host | De facto for open weights, PEFT adapters | Open-weights distribution, fine-tuning shops |
| Vertex AI Registry | GCP-managed | One-click Vertex endpoint deploy | GCP-native stacks |
| SageMaker Registry | AWS-managed | IAM-scoped governance, Pipelines integration | AWS-native stacks |
44.1.12 Prompts and Adapters as First-Class Artifacts
Until roughly 2023, registries assumed the deployable was a weights file plus a tokenizer. For modern LLM stacks the deployable is a bundle: base model identifier, one or more LoRA / QLoRA adapters, a prompt template, few-shot examples, and a RAG configuration (index name, embedding model, top-k). All five can change independently and each change is a behavior change that must be versioned. Three patterns work in 2025: bundle into the MLflow PyFunc so one version captures everything; cross-link MLflow and Langfuse where MLflow versions weights and Langfuse versions prompts, with each storing the other's version ID; or use Hugging Face Hub for everything, with model repos for weights, adapter repos for PEFT, and dataset repos for prompt and eval data.
LoRA and QLoRA adapters are tied to a specific base-model version. If the base is Llama-3.2-8B revision abc123 and you transparently upgrade the base to abc456 on Hugging Face Hub (because someone pushed a fix to the tokenizer or the config), the adapter may still load but produce subtly different outputs. Pin the base-model revision hash in your registry metadata and in the serving config; do not rely on main or floating branch names. The 2024 HF revision= parameter on from_pretrained() is the API for this.
44.1.13 Real-World Cases
Three named 2024-2025 cases. Databricks publishes its Unity Catalog + MLflow Registry as the enterprise lifecycle pattern, with three-level namespacing and row-level governance; this is what regulated industries adopt. Meta uses Hugging Face Hub as the public distribution channel for Llama-3 weights with revision hashes pinned in the model card, the canonical open-weights pattern. Anthropic's vendor-hosted Claude models are versioned via API snapshot identifiers; from the customer's perspective the snapshot ID is the registry version and is referenced in serving config, which is why the Section 44.3 (Drift Detection) hash-pinning discussion lives here too. For the upstream training side see Experiment Tracking; for the downstream see vLLM & Inference Servers (vLLM and TGI can resolve a registered model by name or pull from HF Hub at startup).
- Chapter 62 (Production Engineering) for the conceptual lifecycle framing.
- Section 19.11 (Libraries & Frameworks) for the upstream side: MLflow Experiments, W&B runs.
- Section 10.7 (Libraries & Frameworks) for the downstream side: how the serving stack resolves a registered model.
- Section 71.1 (Platforms) for the rollout patterns that consume registry promotions as their input event.
- A registry is the system of record between training and serving; its value is the immutable version-to-stage mapping plus audit trail, not the artifact storage.
- Promotion stages (None / Staging / Production / Archived) plus a transition API are the standard lifecycle primitive; treat them as the contract between training and serving teams.
- Pick by stack: MLflow for vendor-neutral self-host, W&B for run-linked context, Hugging Face Hub for open weights and adapters, Vertex / SageMaker for cloud-native locked-in stacks.
- For LLMs, prompts and LoRA adapters are first-class artifacts. Bundle them into the model (MLflow PyFunc), cross-link to a prompt registry (Langfuse / LangSmith), or use HF Hub repos for each artifact type.
- Always pin base-model revision hashes when registering adapters; floating branches lead to silent compatibility drift.
Reliability engineering for LLMs is forcing a rethink of two SRE staples: the SLO and the model registry. Classical SLOs measure availability and latency, where ground truth is unambiguous. For an LLM, "did the response satisfy the user" is itself a model output. LLM-as-judge evaluation (Zheng et al., 2023, MT-Bench, arXiv:2306.05685) provides a scalable proxy, and the 2024 work on G-Eval (Liu et al., NAACL 2023, arXiv:2303.16634) and Prometheus 2 (Kim et al., 2024) provides judge models calibrated for production telemetry.
On the registry side, the 2025 research on continuous fine-tuning (LoRAX, Predibase 2024) and online RLHF (Ji et al., Beavertails 2024) is pushing registries toward versioning a stream of small updates rather than discrete checkpoints, raising open questions about how to define an SLO when the model itself is changing under traffic. OpenLineage (LF AI and Data, 2024) is extending data-lineage standards to capture prompt versions and adapter ancestry, and Model Cards 2.0 work (Mitchell et al., follow-on, 2024) is integrating SLO compliance into the card schema.
The direction the field is moving: SLOs that combine traditional availability with quality budgets (allow X percent of outputs to fall below judge score Y), registries that version every artifact in the prompt-plus-adapter-plus-weights bundle, and incident-response runbooks that diff registry entries automatically. The 2026 question is whether quality SLOs will be enforced through automated rollback the way latency SLOs already are.
With a registry in place, you have the substrate that the rest of Chapter 66 builds on: SLO dashboards keyed by model version, canary deployments that compare registered candidates against the current champion, and incident runbooks that diff registry entries to find what changed. The dashboards and observability tooling that consume registry metadata live in Section 44.2: LLM Evaluation Dashboards.