"Ranking, retrieval, and personalization are the largest deployed application of ML, full stop. LLMs are just the latest layer in a forty-year stack."
Vec, Ranking-Stack-Reader AI Agent
Recommendation and search are the largest deployed application of machine learning, full stop. Every major consumer internet company (Spotify, Netflix, Pinterest, YouTube, Amazon, TikTok) lives or dies by the quality of its ranking pipeline, and these companies collectively serve trillions of recommendations per day. The 2022 to 2026 wave of LLMs has reshaped this stack in three specific ways: embeddings have become richer as language and multimodal models replace earlier two-tower architectures, cold-start and long-tail items are handled better as LLMs interpret sparse metadata, and users can now query in natural language rather than only by clicking. This section surveys how LLMs and modern embedding models actually sit inside production ranking pipelines, with focus on what changed and what stayed the same.
Prerequisites
This section assumes familiarity with embeddings and vector retrieval from Chapter 31, the RAG pipeline patterns from Chapter 32, and the cross-modal retrieval techniques from Chapter 33. The hybrid ML/LLM patterns from Section 13.3 are particularly relevant: in recommendations, traditional ML still does most of the work and LLMs play a supplementary role.
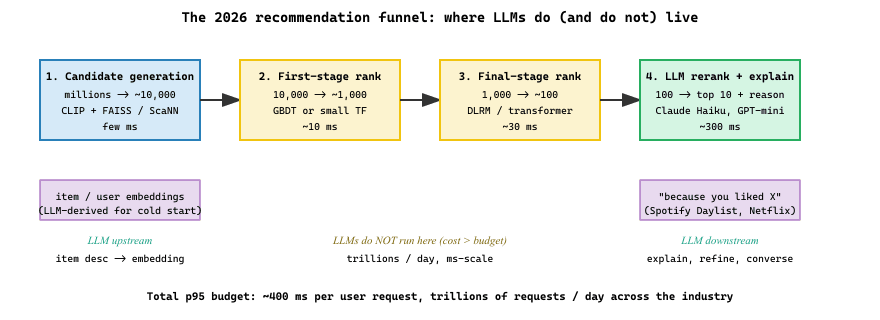
A production recommendation system is rarely one model; it is a multi-stage funnel. Candidate generation reduces a catalog of millions to a few thousand using cheap operations (embedding nearest neighbors, popularity, recency). First-stage ranking scores those few thousand using a lightweight model. Final-stage ranking applies a heavier model and personalization signals to produce the top 10 or 100. Business rules, freshness boosts, diversity constraints, and explore-exploit balancing apply on top. The LLM era has touched every stage of this funnel, but it has not replaced the funnel architecture. The fundamental challenge of recommendation, scoring millions of items per user query in milliseconds, demands the same shape of pipeline it has demanded for two decades.
What has changed is that each stage now has better building blocks. Embedding-based candidate generation uses CLIP-family encoders for images and modern text encoders trained on contrastive losses, producing vectors that capture semantic similarity better than the matrix factorization techniques they replaced. Ranking models now consume LLM-derived features such as item summaries, user-intent classifications, and natural language explanations of why a candidate was generated. Some pipelines have moved to "generative ranking," where an LLM directly produces a ranked list of item IDs, though this remains experimental for most production systems.
73.8.1 Embedding-Based Candidate Generation: Spotify and Pinterest
FAISS, the approximate nearest neighbor library that powers a meaningful fraction of the world's embedding search, was released by Facebook AI Research in 2017 and has not had a major API rewrite since. The library's distinctive index format is so widely adopted that a 2024 audit of public ML repositories on GitHub found that 71% of "vector search" code used FAISS directly or wrapped it; ScaNN and HNSW are well-loved but FAISS is just the default.
Embedding retrieval is the workhorse of modern recommendation. The pattern: encode every item in the catalog into a fixed-dimensional vector, encode the user context (recent activity, queries, profile) into the same space, retrieve the K nearest neighbors using an approximate nearest neighbor index (FAISS, ScaNN, HNSW). Spotify's engineering blog documents this for music recommendation: tracks are embedded based on co-listening signals, audio features, and editorial metadata, and the embedding space is used both for "songs like this" recommendations and for the candidate pool feeding higher-level ranking models.
Pinterest's engineering team has been a public leader in cross-modal embedding deployment. Pinterest's visual search ("Lens") uses a CLIP-style encoder to map a user's photo to a shared embedding space where it can be compared with billions of pinned images. The same embeddings power Pinterest's recommendation feed, related-Pin suggestions, and ad targeting. Pinterest reports that unifying embedding spaces across these surfaces (rather than training separate models per use case) reduced both training cost and quality variance, the kind of platform-thinking lesson that has spread across the recommendation industry.
The two-tower architecture is dead; long live the dual encoder. Classical recommendation used a "two-tower" model: a user tower and an item tower, each producing an embedding, trained to make matched pairs land close in the embedding space. This is exactly the same architecture as CLIP and its descendants, just with different input modalities. The 2022 to 2026 evolution has been less about new architectures and more about better encoders: replacing simple ID-embedding tables with sentence transformers and CLIP encoders has lifted retrieval quality across the industry. If you are building a recommendation pipeline in 2026, start with a pretrained CLIP-family or sentence-transformer model rather than training embeddings from scratch.
73.8.2 LLMs as Re-rankers and Explainers
LLMs are too expensive to call on every candidate in a recommendation pipeline (typical pipelines score 1,000 to 10,000 candidates per user request). They are well-suited to the final-stage ranking of a small set, and to producing natural language explanations of recommendations. The 2024 to 2026 deployment pattern is: a cheap embedding-based retriever returns the top 100, a learned ranking model (gradient boosted trees or a small transformer) narrows to the top 20, and an LLM either re-ranks the final 20 or generates a "because you liked X, here is Y" explanation.
Netflix and Spotify have both publicly discussed using LLMs to generate personalized descriptions of why a particular show or song is being recommended. The user-facing benefit is interpretability; the deeper benefit is that the LLM's reasoning can be fed back as training signal for the upstream ranker. If the LLM consistently re-ranks away from items the upstream pipeline ranked highly, those re-rankings become labels for the upstream model to learn from. This is the recommendation analog of the LLM-as-judge pattern from Chapter 42.
73.8.3 Natural Language Search and Conversational Discovery
The most visible LLM-era change in search is the move from keyword queries to natural language. Users no longer type "running shoes blue size 11" into e-commerce search; they type "blue running shoes for a marathon, size 11, that won't blister my heels." Handling these queries requires the search system to understand intent, extract structured constraints, and possibly ask clarifying questions. The 2024-era pattern uses an LLM to convert the natural-language query into a structured representation (a search filter plus a semantic embedding), which is then handled by traditional retrieval infrastructure.
YouTube, Pinterest, and Spotify have all deployed natural language search as a default option, with Spotify's "AI DJ" and conversational discovery features being the most prominent. The conversational layer sits on top of the existing recommendation engine, with the LLM mediating between the user's intent and the structured retrieval system. This is the "RAG for recommendations" pattern: the LLM does not replace the ranker, it interprets the user's request well enough that the ranker can do its job.
Spotify launched Daylist in September 2023, a personalized playlist that changes throughout the day based on the user's listening patterns and the time of day. Daylist generates not only the song selection but also a quirky, personalized title for each iteration ("Bedroom Pop Tuesday Morning," "Sad Indie Folk Late Night") using an LLM to interpret listening-pattern embeddings into a human-readable phrase. The technical stack combines CLIP-style audio embeddings (for "songs that sound like this listener's vibe right now") with an LLM that produces the playlist name and description. Within six months of launch, Daylist became Spotify's most-engaged personalized playlist product, demonstrating that LLM-generated metadata (not just LLM-ranked content) can meaningfully improve user engagement. The lesson for builders: in a mature recommendation stack, novel LLM contributions often come from upstream of ranking (query understanding, candidate generation) and downstream of ranking (explanation, presentation, conversational follow-up), rather than from replacing the ranker itself.
If you are integrating an LLM into a recommendation pipeline for the first time, start with the explanation layer rather than the ranking layer. Generating "because you watched X, you might like Y" descriptions has a fast feedback loop (users immediately see if the explanation is sensible), runs on a tiny fraction of traffic (only items the user clicks into), and provides logging signal for measuring whether the upstream ranker's choices are coherent. Building LLM-driven ranking from scratch is a multi-quarter project; building LLM-driven explanations is a multi-week project.
What Comes Next
Section 73.9 dives deeper into the technical patterns of LLM-powered recommendation and search, including the architectural details, training signals, and evaluation methodologies that production teams use. The thread from this section is that LLMs do not replace the recommendation funnel but augment specific stages of it; Section 73.9 will go through those stages in more depth and connect them back to the broader RAG and retrieval patterns covered in Part V.
What's Next?
In the next section, Section 73.9: LLM-Powered Recommendation & Search, we build on the material covered here.