"The omni demo is twenty seconds of magic followed by an API price list."
Pixel, Omni-Aspirational AI Agent
Four frontier omni models defined the 2024-2026 state of native multimodality. OpenAI's GPT-4o was the May 2024 unveiling that made native voice mode mainstream. Google DeepMind's Gemini 2.0 and 2.5 brought long-context multimodal (up to 2M tokens including image and audio) and tool-use to the same model. Meta released the open-weights Chameleon to prove early fusion at scale, then Llama-4-Omni in 2025 brought any-to-any to open source. This section unpacks each model's architecture, capability profile, and 2026 cost structure, plus the practical guidance on when each is the right pick.
Prerequisites
This section assumes the VLM and any-to-any architectures from Section 22.1 through Section 22.8, the speech and audio pipelines from Section 20.1, and the frontier-API platform shelf from Section 14.1.
22.9.1 GPT-4o and the Realtime API
The GPT-4o launch demo in May 2024 famously had the model laugh, sing, switch accents, and flirt with the presenters. Scarlett Johansson noted, with some chill, that the default "Sky" voice sounded remarkably like the AI she had played in the film Her. OpenAI pulled the voice within days. It remains the only time in modern AI that a frontier model launched a feature, got sued, and apologized in less than a week.
GPT-4o (omni), released May 2024, was OpenAI's first natively multimodal model. The full architecture was not disclosed, but the public information and behavior suggest:
- A single transformer trained on interleaved text, audio, and image tokens (early fusion).
- Discrete audio tokenization at ~24 Hz frame rate (compatible with low-latency streaming).
- Image inputs as patch tokens (likely SigLIP-style encoder).
- Output image generation through a separate diffusion decoder gated by the model's emit tokens (a hybrid pattern; see Section 22.8).
The capability headline was the Realtime API: an audio-in, audio-out conversational loop with under 320ms time-to-first-audio-token. Voice mode preserves paralinguistic cues (emotion, sarcasm, sighs) that pure-text pipelines lose. Pricing for the Realtime API in 2026 sits around $0.06 per minute of audio input and $0.24 per minute of audio output, with $5 / $20 per million text input/output tokens for the text path.
# GPT-4o Realtime API: WebSocket session for streaming audio.
# See Section 38.2 for the full protocol walkthrough.
import asyncio
import websockets
import json
async def realtime_voice_chat():
url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview"
headers = {"Authorization": f"Bearer {api_key}", "OpenAI-Beta": "realtime=v1"}
async with websockets.connect(url, extra_headers=headers) as ws:
await ws.send(json.dumps({
"type": "session.update",
"session": {
"modalities": ["text", "audio"],
"voice": "alloy",
"input_audio_format": "pcm16",
"output_audio_format": "pcm16",
"turn_detection": {"type": "server_vad"},
}
}))
# Stream PCM-16 audio chunks of ~100ms each.
async for chunk in mic_chunks():
await ws.send(json.dumps({
"type": "input_audio_buffer.append",
"audio": b64(chunk),
}))
# Server emits response.audio.delta events with TTS chunks.22.9.2 Gemini 2.0 and 2.5: Native Multimodal at Long Context
Google DeepMind's Gemini family was the first frontier-scale natively multimodal model (Gemini 1.0 in December 2023). Gemini 2.0 (December 2024) and Gemini 2.5 (mid-2025) deepened the capability:
- Long-context multimodal: Gemini 1.5 Pro shipped 2M-token context, including interleaved images, audio, and video frames. A 1-hour video can be passed in full at native temporal resolution. Gemini 2.5 Pro extended this to ~10M tokens with optimized retrieval.
- Native audio generation and understanding: voice and audio streams are tokenized at a higher rate than GPT-4o (sufficient for music understanding, not just speech).
- Tool use and agent capabilities: Gemini 2.0 was the first frontier model to ship with native agent tooling (web search, code execution, mouse-and-keyboard control) as built-in capabilities.
- Video generation: Veo 3 (the Gemini-aligned video model) integrates with the LLM for prompt expansion and post-generation editing.
Pricing in 2026: Gemini 2.5 Pro is $1.25 per million input tokens and $10 per million output tokens for the standard context window, with audio and image tokens billed at modality-specific rates. Gemini 2.0 Flash is roughly 5x cheaper and remains the workhorse for high-volume multimodal applications.
22.9.3 Chameleon and Llama-4-Omni: Open-Source Frontier
Meta's Chameleon (Team, 2024) was a milestone: the first open-weights frontier-scale early-fusion multimodal model. Chameleon-7B and Chameleon-34B handle interleaved text and image input and output, all through a single autoregressive transformer over discrete tokens. The model uses:
- A VQ-VAE-style image tokenizer producing 1024 tokens per 512x512 image.
- BPE text tokenizer with vocabulary extended by the image codebook.
- Standard decoder-only transformer (similar to Llama-2) with QK-norm for training stability.
Chameleon's released image generation capability was limited (the open weights had it disabled at launch for safety reasons), but the architectural blueprint influenced everything that followed.
Llama-4-Omni (Meta, 2025) inherits Chameleon's early-fusion DNA and extends it with audio I/O. The model is positioned as the open-source competitor to GPT-4o, with three sizes (8B, 70B, 400B+ MoE) and weights released under a permissive license for research. Inference cost on commodity hardware: a Llama-4-Omni-8B serves voice conversations at ~$0.01 per minute on a single A10G, an order of magnitude cheaper than GPT-4o Realtime.
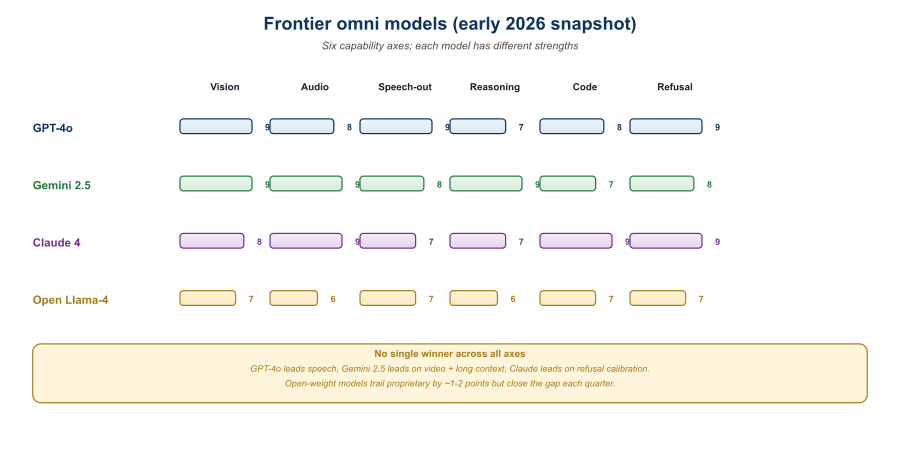
22.9.4 Capability and Cost Matrix
| Capability | GPT-4o | Gemini 2.5 Pro | Llama-4-Omni | Chameleon |
|---|---|---|---|---|
| Text reasoning (MMLU-Pro) | ~75% | ~80% | ~73% | ~62% |
| Image understanding (MMMU) | ~70% | ~76% | ~67% | ~50% |
| Audio in (speech ASR) | Strong | Strong | Strong | None |
| Audio out (TTS) | Strong | Strong | Moderate | None |
| Image generation | Yes (gated diffusion head) | Yes | Yes | Disabled in open weights |
| Video generation | Via Sora 2 | Via Veo 3 | Limited | None |
| Long context | 128k | 2M to 10M | 128k | 4k to 16k |
| Realtime audio API | Yes | Yes (Gemini Live) | Self-hosted | No |
| Open weights | No | No | Yes | Yes (partial) |
| Approx. 2026 cost per 1M tokens | $5 in / $20 out | $1.25 in / $10 out | Self-hosted | Self-hosted |
Llama-4-Omni's release was the first time an open-weights model approached the capability frontier on every modality. For research and on-premises deployment (regulated industries, latency-critical applications, fine-tuning), this is a step change. The downside: omni models are expensive to serve, and the open-weights versions assume you have multi-GPU infrastructure. For pure cloud consumption, Gemini and GPT-4o remain easier defaults.
22.9.5 Architecture Deep-Dive Notes
Detailed architectures are confidential for the proprietary models, but the open papers and the behavior in production give consistent clues:
- GPT-4o: appears to be early fusion at the input, late fusion for image generation. Audio in/out uses a discrete codec at ~25 Hz. Estimated parameter count: 200B to 400B in MoE form.
- Gemini 2.5: native multimodal training on Pathways infrastructure, with TPU v5p deployment. Long context relies on a learned compression scheme that retrieves relevant chunks from a memory bank, similar in spirit to Section 32.1's RAG patterns but learned end-to-end.
- Llama-4-Omni: early fusion, RVQ audio tokenizer at 50 Hz, image tokenizer at ~1024 tokens per image. MoE for the 400B variant; dense for smaller sizes. Released alongside training code, which makes the architecture inspectable.
- Chameleon: dense decoder-only, fully early fusion, 7B and 34B sizes. Used QK-norm and clamped attention to stabilize training across modalities, an architectural lesson that propagated to most subsequent omni models.
22.9.6.2026 The 2026 Pick List
Who: A 2026 product team standing up a new multimodal assistant and deciding which frontier omni model to anchor on.
Situation: The team had budget to integrate one or two omni models and needed to map each candidate to a concrete workload (voice, long-context video, on-prem fine-tuning, image generation, agent tooling, cheap-bulk).
Problem: No single model dominated on all six axes; picking the wrong anchor would force a rewrite once the product's modality emphasis shifted.
Dilemma: Pick one model for simplicity and risk capability gaps, or compose multiple models behind a router and accept the integration cost.
Decision: They used a router pattern that selects per-request based on the dominant modality.
How: The team built the following pick list and wired it to the router from Section 22.6:
- You need the smoothest voice agent experience and have OpenAI account: GPT-4o Realtime.
- You need long-context video or document understanding: Gemini 2.5 Pro.
- You need to fine-tune for an on-premises voice assistant: Llama-4-Omni.
- You are doing academic research on multimodal training: Chameleon or Llama-4-Omni (open weights, reproducible).
- You need image generation tightly coupled with conversation: Gemini 2.5 Pro or GPT-4o.
- You need agent tooling natively integrated: Gemini 2.5 Pro.
- You need lowest cost at scale and can tolerate quality gap: Gemini 2.0 Flash or self-hosted Llama-4-Omni-8B.
Result: A common 2026 production stack emerged from this list: Gemini 2.5 Pro for offline analysis and long-context tasks, GPT-4o Realtime for live voice, and Llama-4-Omni for on-prem fine-tuned use cases, with the router choosing per request.
Lesson: The right pick depends on which of the six workload axes matters most for your application, and most production stacks compose multiple frontier omni models behind a request router rather than betting on a single anchor.
22.9.7 Evaluation: Beyond the Leaderboards
Benchmark scores (MMLU-Pro, MMMU, MMB, LiveBench) capture capability under standardized conditions but miss two factors that often dominate production decisions:
- Voice agent tone and persona: GPT-4o Voice's prosody feels noticeably different from Gemini Live's. Audition the models with your actual application prompts before committing.
- Latency under real load: published TTFT figures assume warm cache, light load. Production load patterns can double the latency on any of these systems.
The recommended evaluation protocol: 100 to 500 real prompts from your domain, run each through every candidate model, score the outputs on a 5-point rubric covering accuracy, helpfulness, tone, and latency. The cost of running such an eval (~$200 in API spend plus a few hours of human time) is dwarfed by the cost of picking the wrong frontier model.
The 2026 frontier omni landscape is GPT-4o, Gemini 2.5, Llama-4-Omni, and Chameleon, with capability profiles differentiated by modality strength, context length, and licensing. Gemini leads on long context and tool integration; GPT-4o leads on conversational voice; Llama-4-Omni leads on open-weights deployability; Chameleon's contribution is the architectural template for early-fusion training. The right pick depends on which of the four mattering most for your application, and most production stacks compose multiple of them.
Vision-language models are converging on three open research questions in 2025-2026. First, native multimodal pretraining versus connector-based VLMs: Chameleon (Chameleon Team, Chameleon: Mixed-Modal Early-Fusion Foundation Models, arXiv:2405.09818) and successor work argue that interleaved early-fusion training beats projecting frozen vision encoders into an LLM, but training cost is much higher. Second, high-resolution and long-video handling: dynamic tiling (Liu et al., LLaVA-NeXT: Improved reasoning, OCR, and world knowledge, 2024) and token-merging schemes like LongVILA (Chen et al., LongVILA: Scaling Long-Context Visual Language Models for Long Videos, arXiv:2408.10188) attack the quadratic blow-up, but the trade-off between resolution, frames, and context budget is still ad-hoc.
Third, grounded reasoning and spatial understanding. Open VLMs from 2024-2026 such as Qwen2-VL (Wang et al., Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution, arXiv:2409.12191) demonstrate strong OCR and visual grounding, yet benchmarks like MMMU and BLINK reveal that compositional and physical reasoning remain weak. Expect 2026 work to focus on world-model integration and 3D-aware perception.
Objective
Run the same 20-question vision QA suite through GPT-4o and Claude Sonnet 4.7, judge the answers against a small gold set, and report accuracy plus per-image cost. By the end, you will know which model wins on your domain, and by how much, with hard numbers rather than vibes.
Setup
You need an OpenAI key, an Anthropic key, and 20 images: 5 charts, 5 photos with text (signs or receipts), 5 diagrams, 5 natural scenes. Write 1 question per image plus a 1-sentence gold answer. Place the images in data/vqa/ and the gold set in data/vqa.jsonl.
pip install openai anthropic pillow pandasSteps
- Encode the images: Convert each image to a base64 data URL (OpenAI) and to the Anthropic image content block format. Cache the encoded payloads so you only pay the encoding cost once.
- Call both models: For each item, send the question plus image to
gpt-4o-2024-11-20andclaude-sonnet-4-7-20251022withtemperature=0,max_tokens=200. Record the response, latency, and reported token counts. - Score the answers: Use an LLM-as-judge (a third model, GPT-4o-mini with a strict rubric) to mark each answer as Correct, Partial, or Wrong against the gold sentence. Sanity-check 5 random items by hand.
- Compute cost: Multiply input and output tokens by the published rates (USD per million). Report per-image cost and aggregate cost per model.
- Tabulate and visualize: Build a pandas DataFrame with columns model, category, correctness, latency_ms, cost_usd. Print accuracy by category and the cost-per-correct-answer metric.
Expected Output
Typical results show roughly 75 to 90% accuracy for both models, with one model 10 to 20 percentage points stronger on a specific category (often OCR or charts). Per-image cost should land between $0.01 and $0.05; cost-per-correct-answer is the metric that actually matters for production routing.
Extension
Add a third candidate (Gemini 2.5 Pro or an open-weights Qwen2-VL-72B run through OpenRouter) and turn the script into a continuous-eval cron that re-runs weekly so capability drift is visible.
Show Answer
Show Answer
Show Answer
Show Answer
What Comes Next
Chapter 37 closes here. Chapter 39: Streaming and Real-Time Multimodal goes deeper on the protocols and latency engineering that make conversational omni-model UX possible.