A good assistant remembers you. A great one knows when to forget.
Echo, Long-Memoried AI Agent
Short-term memory (covered in Section 37.3) keeps the current conversation coherent. Long-term memory is what lets a system carry knowledge across sessions, weeks, and months: vector stores that retrieve old context by meaning, user profiles that accumulate stable preferences, self-managing architectures like MemGPT/Letta where the LLM itself decides what to remember, and memory-as-a-service platforms that package all of this behind an API. This section ties those pieces together, compares them, shows how to consolidate and evaluate them, and closes with a hands-on lab that wires short-term and long-term memory into one chatbot.
Prerequisites
This section continues from Section 37.5. You should be familiar with the short-term memory patterns from Section 37.3 and with the basic conversational architecture from Section 37.1. The vector-store discussion here builds on vector index choices from Section 31.2.
This continuation of Section 37.5 picks up after the architectures and turns to memory operations. It covers the consolidation patterns that compress and prune memories so the store does not blow up over months of use, the evaluation metrics and benchmarks that tell you whether your memory layer is actually helping, and an end-to-end worked example that wires short-term and long-term memory into one chatbot.
37.6.1 Memory Consolidation Patterns
The biological metaphor of "memory consolidation during sleep" used to motivate LLM memory consolidation comes from neuroscience research on hippocampal replay during slow-wave sleep, first characterized in rats by Bruce McNaughton's lab in the 1990s. LLM agents do not literally need sleep, but the daily-batch consolidation pattern that has emerged in production conversation systems looks suspiciously like a digital version of REM-cycle housekeeping.
Raw memory accumulation is not enough. Over time, a memory system that only adds and never consolidates will drown in redundant, contradictory, and stale information. Memory consolidation, inspired by how the human brain processes memories during sleep, periodically reviews, merges, and prunes stored memories to maintain a coherent and useful knowledge base.
Why does consolidation matter? Without it, a user who mentions "I like coffee" in 50 different conversations will have 50 nearly identical memory entries. A user who says "I prefer PostgreSQL" in January and "I switched to MongoDB" in March will have contradictory memories with no resolution. A system that remembers everything equally cannot distinguish a passing preference from a deeply held value.
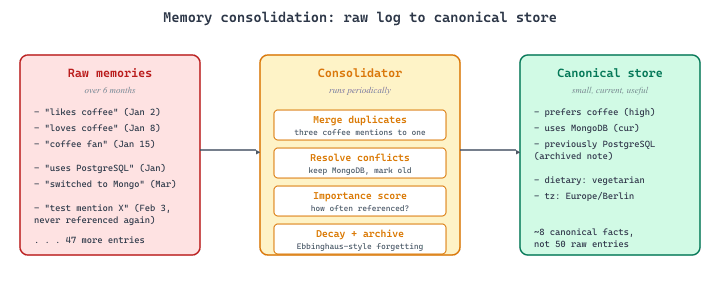
37.6.1.1 Importance Scoring
Not all memories are equally valuable. Importance scoring assigns a weight to each memory based on factors like: how many times the information has been referenced, whether the user explicitly stated it versus it being inferred, the specificity of the information (a specific dietary restriction matters more than a general comment about food), and temporal relevance (recent preferences may override old ones). An LLM call can assess importance, or heuristic rules can provide a cheaper approximation.
37.6.1.2 Periodic Consolidation
Consolidation runs on a schedule (after every N conversations, or nightly for active users) and performs three operations: merge duplicate or near-duplicate memories into a single canonical entry, resolve conflicts between contradictory memories by keeping the more recent or more frequently reinforced version, and compress verbose memories into their essential content. This is analogous to the progressive summarization from Section 37.3.3, but applied to the memory store rather than the conversation history.
37.6.1.3 Forgetting and Decay
Deliberate forgetting is a feature, not a bug. Memories that have not been accessed or reinforced over a long period should decay in importance and eventually be archived or deleted. Ebbinghaus-inspired forgetting curves (where memory strength decays exponentially with time but resets on each retrieval) provide a principled model for this. The MemoryBank system (Zhong et al., 2024, cited in the bibliography) implements this approach with tunable decay rates.
# Memory consolidation pipeline
from openai import OpenAI
from datetime import datetime, timedelta
client = OpenAI()
def consolidate_memories(
memories: list[dict],
current_date: datetime = None
) -> list[dict]:
"""
Consolidate a list of memories by merging duplicates,
resolving conflicts, and applying decay.
"""
current_date = current_date or datetime.now()
# Step 1: Score importance
for mem in memories:
age_days = (current_date - mem["created"]).days
access_count = mem.get("access_count", 1)
# Decay: halve importance every 30 days without access
decay = 0.5 ** (age_days / 30)
# Boost for frequently accessed memories
frequency_boost = min(2.0, 1.0 + 0.1 * access_count)
# Explicit statements are more important than inferences
source_weight = 1.5 if mem.get("source") == "explicit" else 1.0
mem["importance"] = decay * frequency_boost * source_weight
# Step 2: Merge duplicates and resolve conflicts using LLM
memory_texts = "\n".join(
f"[{m['importance']:.2f}] ({m['created'].strftime('%Y-%m-%d')}) {m['text']}"
for m in sorted(memories, key=lambda x: -x["importance"])
)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{
"role": "user",
"content": (
"Review these user memories. For each group of related memories:\n"
"1. Merge duplicates into one canonical entry\n"
"2. When memories conflict, keep the more recent version\n"
"3. Drop memories with importance below 0.1\n"
"4. Preserve the most specific version of each fact\n\n"
f"Memories:\n{memory_texts}\n\n"
"Return the consolidated list as one memory per line."
)
}],
temperature=0
)
consolidated_texts = response.choices[0].message.content.strip().split("\n")
return [
{"text": t.strip(), "created": current_date, "access_count": 0}
for t in consolidated_texts if t.strip()
]
# Example: 3 memories about database preference over time
memories = [
{"text": "User prefers PostgreSQL for databases",
"created": datetime(2024, 1, 15), "access_count": 3, "source": "explicit"},
{"text": "User mentioned liking PostgreSQL",
"created": datetime(2024, 2, 1), "access_count": 1, "source": "inferred"},
{"text": "User switched to MongoDB for their new project",
"created": datetime(2024, 6, 10), "access_count": 2, "source": "explicit"},
]
consolidated = consolidate_memories(memories)
# Result: single entry reflecting the most recent preferenceMemory consolidation that aggressively prunes or overwrites can lose information the user considers important. Always err on the side of keeping too much rather than too little, and provide users with the ability to pin important memories so they are never subject to decay. When resolving conflicts, the consolidation system should prefer explicit statements over inferences and more recent information over older information, but it should also consider whether the older information might still be valid in a different context.
37.6.2 Evaluating Memory Quality
How do you know whether your memory system is actually working? Retrieval accuracy (did we find the right memory?) is necessary but not sufficient. A memory system must also return information that is timely (not stale), relevant (useful for the current context), and precise (not cluttered with tangential entries). Several benchmarks and metrics have emerged to evaluate these dimensions.
Memory and Long-Context Benchmarks
LongBench (Bai et al., 2024) evaluates LLMs across six long-context task categories, including multi-document QA, summarization, and code completion, with input lengths ranging from 4K to 20K+ tokens. It tests whether models can locate and use information buried deep in long inputs. InfiniteBench (Zhang et al., 2024) pushes further, testing contexts beyond 100K tokens with tasks that require reasoning over extremely distant information. MemBench focuses specifically on conversational memory, evaluating whether systems can recall user-stated facts, preferences, and prior decisions across multi-session dialogues. Together, these benchmarks reveal that raw context length is not the same as usable memory; a model may support 128K tokens but still fail to retrieve a fact stated at token position 20K.
Memory Quality Metrics
Beyond benchmark scores, production memory systems should track four operational metrics. Memory precision measures the fraction of retrieved memories that are actually relevant to the current query (high precision means few irrelevant entries clutter the context). Memory recall measures the fraction of relevant memories that are successfully retrieved (high recall means important information is not missed). Staleness tracks how often the system surfaces outdated information that has been superseded by newer data, such as returning an old address after the user has provided an updated one. Relevance decay measures how retrieval quality degrades as conversations grow longer and the memory store accumulates more entries. Monitoring these metrics over time reveals whether your memory system is improving or degrading as usage scales.
Evaluating memory quality is inherently harder than evaluating retrieval accuracy because memory has a temporal dimension. A memory that was correct last week may be wrong today. Benchmark suites like MemBench include "preference update" test cases where the user explicitly changes a previously stated fact, testing whether the system correctly surfaces the updated version. The evaluation framework from Section 42.1 provides general-purpose metrics that complement the memory-specific measures described here.
When the model is uncertain or the query is out of scope, have it say so rather than hallucinate. Train your system to recognize low-confidence responses and route to human agents, FAQ pages, or clarification requests.
Who: An ML engineer at a wealth management fintech serving 50,000 clients
Situation: Clients expected the chatbot to remember their portfolio preferences, risk tolerance, and prior conversations across sessions. A client who said "I told you last month I want to avoid tech stocks" expected that preference to persist.
Problem: Storing full conversation histories consumed the entire 128K context window within 3 to 4 sessions. Truncating older messages caused the bot to "forget" critical preferences and repeat questions, frustrating high-value clients.
Dilemma: Summarizing old conversations compressed them effectively but lost specific details (exact allocation percentages, named stocks). A vector-based retrieval memory preserved details but sometimes surfaced irrelevant old context that confused the current conversation.
Decision: They implemented a three-tier memory system: (1) a structured client profile storing key facts as explicit key-value pairs (risk tolerance: moderate, sector exclusions: [tech, tobacco]), (2) a rolling summary of the last 5 sessions, and (3) a vector store of all conversation turns for on-demand retrieval when the client referenced a specific past discussion.
How: After each session, an LLM extraction step updated the structured profile with any new preferences. The system prompt always included the profile and recent summary; vector retrieval was triggered only when the user explicitly referenced past conversations.
Result: Client satisfaction scores rose from 3.6 to 4.4 out of 5. The "repeated question" complaint rate dropped from 23% to 3%. Context window usage stayed under 40K tokens even for clients with 50+ sessions.
Lesson: Tiered memory (structured facts, summaries, and searchable archives) outperforms any single strategy because different types of information have different retrieval patterns and retention requirements.
Retrieval-augmented memory stores conversation history in a vector database and retrieves relevant past exchanges based on the current query, enabling effectively unlimited conversation length. Hierarchical memory architectures maintain multiple memory tiers (working memory, episodic memory, semantic memory) inspired by cognitive science, with different retention and retrieval policies for each tier. Memory compression with LLMs uses a smaller model to continuously summarize and consolidate conversation history, keeping the most important information within the context window. Research into shared memory across conversations is developing methods for agents to accumulate knowledge about users across sessions without violating privacy constraints.
Objective
Build a chatbot with a three-tier memory system: a short-term sliding window buffer (from Section 37.3), an LLM-powered conversation summarizer, and a vector-based long-term memory store for fact retrieval across sessions.
What You'll Practice
- Implementing a sliding window buffer for short-term conversation memory
- Building an LLM-powered progressive conversation summarizer
- Creating a vector-based long-term memory for user fact extraction and retrieval
- Combining memory layers into a unified context for the LLM
Setup
The following cell installs the required packages and configures the environment for this lab.
Steps
Step 1: Build the short-term memory buffer
Create a sliding window that keeps the most recent N messages.
class ShortTermMemory:
def __init__(self, max_turns=10):
self.messages = []
self.max_turns = max_turns
self.overflow = []
def add(self, role, content):
self.messages.append({"role": role, "content": content})
# Evict oldest messages when buffer is full
while len(self.messages) > self.max_turns:
self.overflow.append(self.messages.pop(0))
def get_messages(self):
return list(self.messages)
def get_overflow(self):
"""Return and clear evicted messages for summarization."""
evicted = list(self.overflow)
self.overflow.clear()
return evicted
# Test
stm = ShortTermMemory(max_turns=4)
stm.add("user", "Hi, my name is Alice")
stm.add("assistant", "Hello Alice!")
stm.add("user", "I work at Google as a ML engineer")
stm.add("assistant", "That sounds exciting!")
stm.add("user", "I'm interested in RAG systems")
print(f"Buffer: {len(stm.get_messages())} messages")
print(f"Overflow: {len(stm.overflow)} evicted")
for m in stm.get_messages():
print(f" [{m['role']}] {m['content']}")Hint
The overflow list collects messages that have been evicted from the buffer. These messages should be summarized before they are permanently discarded. The get_overflow() method returns and clears this list.
Step 2: Build the conversation summarizer
Create a component that progressively summarizes old conversation turns.
from openai import OpenAI
client = OpenAI()
class Summarizer:
def __init__(self):
self.running_summary = ""
def summarize(self, messages):
if not messages:
return self.running_summary
text = "\n".join(f"{m['role'].title()}: {m['content']}"
for m in messages)
prompt = (
f"Current summary:\n"
f"{self.running_summary or '(none yet)'}\n\n"
f"New turns to incorporate:\n{text}\n\n"
f"Write an updated summary capturing all key facts and "
f"user preferences. Keep it to 2 to 4 sentences."
)
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.3, max_tokens=200)
self.running_summary = resp.choices[0].message.content
return self.running_summary
# Test
summarizer = Summarizer()
summary = summarizer.summarize([
{"role": "user", "content": "My name is Alice, I work at Google"},
{"role": "assistant", "content": "Nice to meet you!"},
{"role": "user", "content": "I need help building a RAG system"},
])
print(f"Summary: {summary}")
Hint
Progressive summarization is key: each time new messages overflow, incorporate them into the existing summary rather than re-summarizing everything. This keeps cost constant regardless of conversation length.
Step 3: Build the long-term vector memory
Create a searchable store that extracts and indexes key facts.
from sentence_transformers import SentenceTransformer
import numpy as np
class LongTermMemory:
def __init__(self):
self.facts = []
self.embeddings = None
self.model = SentenceTransformer("all-MiniLM-L6-v2")
def extract_and_store(self, messages):
text = "\n".join(f"{m['role'].title()}: {m['content']}"
for m in messages)
# TODO: Use LLM to extract factual statements about the user
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user",
"content": f"Extract key facts about the user from this "
f"conversation. One fact per line.\n\n{text}"}],
temperature=0.3, max_tokens=200)
new_facts = [f.strip().lstrip("- ")
for f in resp.choices[0].message.content.strip().split("\n")
if f.strip()]
if new_facts:
self.facts.extend(new_facts)
self.embeddings = self.model.encode(self.facts)
return new_facts
def search(self, query, top_k=3):
if not self.facts or self.embeddings is None:
return []
qe = self.model.encode(query)
scores = np.dot(self.embeddings, qe) / (
np.linalg.norm(self.embeddings, axis=1) * np.linalg.norm(qe))
idx = np.argsort(scores)[::-1][:top_k]
return [(self.facts[i], scores[i]) for i in idx if scores[i] > 0.3]
# Test
ltm = LongTermMemory()
facts = ltm.extract_and_store([
{"role": "user", "content": "I'm Alice, ML engineer at Google"},
{"role": "user", "content": "I prefer PyTorch over TensorFlow"},
])
print(f"Extracted: {facts}")
print(f"Search 'employer': {ltm.search('Where does Alice work?')}")Hint
The extraction prompt should target specific, factual statements like "Alice works at Google" rather than impressions. The 0.3 similarity threshold filters out irrelevant results during search.
Step 4: Wire everything into a memory-augmented chatbot
Combine all three memory layers into a working conversational agent.
class MemoryChat:
def __init__(self):
self.stm = ShortTermMemory(max_turns=6)
self.summarizer = Summarizer()
self.ltm = LongTermMemory()
def chat(self, user_message):
# Search long-term memory for relevant facts
relevant = self.ltm.search(user_message)
facts_text = "\n".join(f"- {f}" for f, _ in relevant) or "None yet."
# Build context-enriched system prompt
sys = (f"You are a helpful assistant with memory.\n"
f"Summary: {self.summarizer.running_summary or 'New conversation.'}\n"
f"Relevant facts:\n{facts_text}")
# Assemble message list
msgs = [{"role": "system", "content": sys}]
msgs.extend(self.stm.get_messages())
msgs.append({"role": "user", "content": user_message})
# Generate response
resp = client.chat.completions.create(
model="gpt-4o-mini", messages=msgs,
temperature=0.7, max_tokens=300)
reply = resp.choices[0].message.content
# Update memories
self.stm.add("user", user_message)
self.stm.add("assistant", reply)
# Process overflow
overflow = self.stm.get_overflow()
if overflow:
self.summarizer.summarize(overflow)
self.ltm.extract_and_store(overflow)
return reply
# Run a multi-turn conversation
bot = MemoryChat()
conversation = [
"Hi! I'm Bob, a data scientist at Netflix.",
"I'm building a recommendation system using collaborative filtering.",
"We have about 50 million user interaction records.",
"Considering switching from TensorFlow to PyTorch.",
"I prefer Python 3.11 for stability.",
"Can you remind me what I said I was working on?",
"What company do I work at?",
]
for msg in conversation:
print(f"\nUser: {msg}")
reply = bot.chat(msg)
print(f"Bot: {reply}")
print(f" [STM: {len(bot.stm.get_messages())} | "
f"Summary: {len(bot.summarizer.running_summary)} chars | "
f"LTM: {len(bot.ltm.facts)} facts]")
Hint
The last two questions test memory recall. "What am I working on?" should be answered from the summary (if the message was already evicted from the buffer). "What company?" should come from long-term memory fact retrieval.
Expected Output
- The chatbot maintains coherent conversation across all turns
- "What company do I work at?" correctly retrieves "Netflix" from long-term memory
- The running summary progressively captures key user facts
- Long-term memory stores specific facts like "Bob is a data scientist" and "Bob works at Netflix"
Stretch Goals
- Add session persistence: save summary and facts to JSON for cross-restart memory
- Implement a forgetting mechanism that deprioritizes old facts by access recency
- Add episodic memory: store complete conversation episodes retrievable by date or topic
Complete Solution
from openai import OpenAI
from sentence_transformers import SentenceTransformer
import numpy as np
client = OpenAI()
class ShortTermMemory:
def __init__(self, max_turns=6):
self.messages, self.max_turns, self.overflow = [], max_turns, []
def add(self, role, content):
self.messages.append({"role": role, "content": content})
while len(self.messages) > self.max_turns:
self.overflow.append(self.messages.pop(0))
def get_messages(self): return list(self.messages)
def get_overflow(self):
e = list(self.overflow); self.overflow.clear(); return e
class Summarizer:
def __init__(self): self.running_summary = ""
def summarize(self, msgs):
if not msgs: return self.running_summary
t = "\n".join(f"{m['role']}: {m['content']}" for m in msgs)
r = client.chat.completions.create(model="gpt-4o-mini",
messages=[{"role":"user","content":f"Summary:\n{self.running_summary or '(none)'}\n\nNew:\n{t}\n\nUpdate (2-4 sentences):"}],
temperature=0.3, max_tokens=200)
self.running_summary = r.choices[0].message.content
return self.running_summary
class LongTermMemory:
def __init__(self):
self.facts, self.embeddings = [], None
self.model = SentenceTransformer("all-MiniLM-L6-v2")
def extract_and_store(self, msgs):
t = "\n".join(f"{m['role']}: {m['content']}" for m in msgs)
r = client.chat.completions.create(model="gpt-4o-mini",
messages=[{"role":"user","content":f"Extract user facts (one per line):\n{t}"}],
temperature=0.3, max_tokens=200)
nf = [f.strip().lstrip("- ") for f in r.choices[0].message.content.strip().split("\n") if f.strip()]
if nf: self.facts.extend(nf); self.embeddings = self.model.encode(self.facts)
return nf
def search(self, q, k=3):
if not self.facts: return []
qe = self.model.encode(q)
s = np.dot(self.embeddings, qe)/(np.linalg.norm(self.embeddings,axis=1)*np.linalg.norm(qe))
idx = np.argsort(s)[::-1][:k]
return [(self.facts[i],s[i]) for i in idx if s[i]>0.3]
class MemoryChat:
def __init__(self):
self.stm, self.sum, self.ltm = ShortTermMemory(6), Summarizer(), LongTermMemory()
def chat(self, msg):
rel = self.ltm.search(msg)
facts = "\n".join(f"- {f}" for f,_ in rel) or "None"
sys = f"Helpful assistant with memory.\nSummary: {self.sum.running_summary or 'New.'}\nFacts:\n{facts}"
ms = [{"role":"system","content":sys}] + self.stm.get_messages() + [{"role":"user","content":msg}]
r = client.chat.completions.create(model="gpt-4o-mini",messages=ms,temperature=0.7,max_tokens=300)
reply = r.choices[0].message.content
self.stm.add("user",msg); self.stm.add("assistant",reply)
ov = self.stm.get_overflow()
if ov: self.sum.summarize(ov); self.ltm.extract_and_store(ov)
return reply
bot = MemoryChat()
for m in ["Hi! I'm Bob, data scientist at Netflix.","Building a rec system with collab filtering.",
"50M interaction records.","Switching TF to PyTorch.","Prefer Python 3.11.",
"What am I working on?","What company do I work at?"]:
print(f"\nUser: {m}\nBot: {bot.chat(m)}")
The brute-force np.dot / norm works for tens of facts but degrades fast. Swap the search method for sklearn (small N) or FAISS (large N) and you get the same top-k ranking in a handful of lines.
Show code
from sklearn.metrics.pairwise import cosine_similarity
import faiss
# Small-scale: one-shot batched cosine
sims = cosine_similarity(self.model.encode([q]), self.embeddings)[0]
top_idx = sims.argsort()[::-1][:k]
# Large-scale: persistent FAISS index
self.index = faiss.IndexFlatIP(self.embeddings.shape[1])
self.index.add(self.embeddings / np.linalg.norm(self.embeddings, axis=1, keepdims=True))sklearn + FAISS replace the linear scan.A normalized FAISS inner-product index gives you cosine top-k in O(N) but in tight C++ loops, and scales to millions of facts where the NumPy brute force will stall.
Show code
import faiss, numpy as np
index = faiss.IndexFlatIP(self.embeddings.shape[1])
faiss.normalize_L2(self.embeddings)
index.add(self.embeddings)
qe = self.model.encode([query]); faiss.normalize_L2(qe)
scores, idx = index.search(qe, top_k)IndexFlatIP, so fact retrieval stays cosine-ranked but runs in C++ and scales to millions of stored memories.- Vector retrieval enables long-term recall: Embedding-based memory search allows the system to retrieve relevant information from weeks or months ago based on what the user is currently discussing, transcending the limitations of recency-only approaches.
- Self-managed memory is the frontier: MemGPT/Letta demonstrates that LLMs can manage their own memory through function calls, creating more flexible and context-aware memory systems than hand-coded heuristics. This approach works best with capable models and careful prompt engineering.
- Profiles bridge sessions: A structured user profile (preferences, biographical facts, interaction patterns) is the most compact long-term memory layer and the one with the strongest cost-per-personalization ratio.
- Buy vs. build: Memory-as-a-service platforms (Mem0, Zep, Letta) handle deduplication, conflict resolution, and forgetting; most teams should start with one and migrate to a custom implementation only when control requirements demand it.
- Consolidate or drown: A memory store that only appends will eventually contradict itself. Periodic merging, decay, and importance scoring are not optional for long-running systems.
- Measure memory, not just retrieval: Precision, recall, staleness, and relevance decay are operational metrics worth tracking in production, alongside benchmark scores from LongBench, InfiniteBench, and MemBench.
Show Answer
Show Answer
Show Answer
Exercises
Explain the difference between short-term memory, long-term memory, and session persistence in a conversational system. Give an example of information stored in each.
Show Answer
Short-term: recent conversation turns, kept in the context window (e.g., "I just asked about pricing"). Long-term: persistent knowledge from past conversations (e.g., "user prefers dark mode"). Session persistence: state that survives between sessions (e.g., "user's order ID from yesterday").
Explain how embedding-based memory retrieval works. A user mentioned their dog's name 50 messages ago. How would vector store memory retrieve this when the user says "How is Buddy doing?"
Show Answer
Each message is embedded and stored with its text. When the user says "How is Buddy doing?", the embedding of this query is similar to the embedding of the earlier message "My dog Buddy loves walks in the park." Vector search retrieves the relevant past message even though it was far back in the conversation.
Describe the three memory tiers in the MemGPT architecture. How does the LLM decide when to move information between tiers?
Show Answer
Working context (in-context, small, actively used), archival memory (persistent vector store, large, searchable), recall memory (conversation history, searchable by time). The LLM uses function calls (memory_write, memory_search, memory_update) to manage tiers, triggered by its own assessment of what information to retain or retrieve.
What is memory consolidation, and why is it necessary for long-running conversations? How does it differ from simple summarization? How do these patterns extend to Section 26.1?
Show Answer
Memory consolidation merges, deduplicates, and resolves conflicts across multiple memory entries. Unlike summarization (which compresses one conversation), consolidation operates across sessions, updating facts (e.g., "user moved from NYC to LA" should replace, not coexist with, the old location). Agent memory systems in Chapter 26 apply the same tiered patterns but add tool-use context and task completion tracking.
Build a memory system that embeds each user message and stores it in a vector database. On each new message, retrieve the 3 most relevant past messages and include them in the context.
Create a system that extracts user preferences (name, interests, preferences) from conversation turns and maintains a structured user profile that persists across sessions.
Build a test harness that measures memory quality: insert 20 specific facts across a 50-turn conversation, then ask 20 recall questions. Measure what percentage of facts the system correctly remembers. Compare sliding window, summarization, and vector memory approaches.
What's Next?
In the next chapter, Chapter 38: LLM-Powered Recommender Systems, we continue building on the topics covered here.