"Observability tells you what already broke. Eval-as-product tells you what will break tomorrow if you ship the new prompt today."
Eval, Replay-Native AI Agent
Between 2023 and 2026, evaluation moved out of CI and into a new product category. The CI-gated eval pipeline of Section 42.1 is still essential, but it leaves three jobs undone: scoring live production traffic as it happens, replaying historical traffic against new prompts and models, and comparing dozens of prompt-and-model variants in a UI that PMs and domain experts can actually use. A new generation of tools, Braintrust, Latitude, Laminar, LangSmith, Helicone, and others, has emerged to fill that gap, and the category has a name: eval-as-product. This section is about when to adopt one of these platforms, which one fits which team, and what the integration looks like in code. It is also about when not to adopt one: for fully automated, CI-gated evaluation, the platform fees and integration cost rarely pay back. The decision rests on whether human review and replay loops are central to your iteration cycle.
Prerequisites
This section assumes familiarity with the eval-as-CI pattern from Section 42.1 and basic observability concepts (traces, spans, metrics) from Section 44.4. Some familiarity with promptfoo or DeepEval from Section 45.2 helps with the comparison.
44.7.1 From Eval-as-CI to Eval-as-Product
When: any team iterating on prompts for a production LLM application with non-trivial traffic (more than a few hundred user-facing requests per day). How: sample 200-2000 representative production traces per week, store them in an eval platform's dataset, and re-run them against every prompt/model candidate before merging. Score each replay with the same LLM-as-judge or rule-based scorers, and surface side-by-side diffs in the platform UI. Watch for: sample-bias drift (production traffic shifts, your dataset stays stale), PII leakage (production traces contain user data, the eval dataset inherits it), and judge-rubric rot (the judge prompt that worked six months ago no longer matches what reviewers actually care about). Result: prompt regressions are caught in a UI review before they ship, not by users.
The eval-as-CI pattern from Section 42.1 is necessary but incomplete. It runs the same fixed golden set on every PR, blocks merges on metric thresholds, and reports a pass/fail. That works well for regression prevention: it catches cases where a new prompt or model degrades a well-understood behavior. It does not handle the three jobs that emerged as LLM apps got more complex:
- Scoring live traffic. A golden set is static; production traffic shifts daily. A reasonable score on yesterday's eval set does not guarantee a reasonable score on today's incoming queries. You need a way to score live traffic, at least on a sample, and surface trends as they emerge.
- Replaying historical traffic. When you want to try a new prompt, the question "would this prompt have produced better results on the last week of traffic?" is more decision-relevant than "does this prompt pass the golden set?" Replay against historical traces, with scoring side-by-side, is the core eval-as-product operation.
- Comparing many variants. A spreadsheet of 20 prompts and 4 models is 80 cells. CI gates only the merge candidate; they don't let a PM or domain expert sweep a candidate space. A UI that shows the 80 cells with per-cell scores, side-by-side diffs, and confidence intervals is a fundamentally different workflow than CI.
Eval-as-product is the category of tools that do those three jobs in one UI. The first generation (Promptfoo, OpenAI Evals) emphasized the static-eval job and had limited replay and live-traffic features. The second generation (Braintrust, Latitude, Laminar, LangSmith, Helicone, plus offerings from the major model providers) treats live-scoring, replay, and variant-comparison as first-class operations alongside static eval.
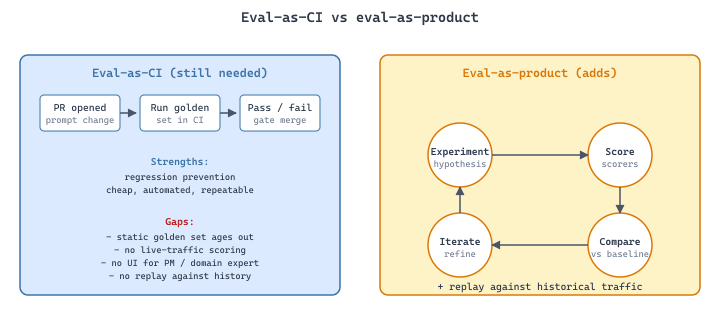
It is easy to confuse eval-as-product with LLM observability platforms (Langfuse, Arize Phoenix, Honeycomb's LLM features). Observability is read-only: it captures traces, lets you query them, and computes aggregate metrics. Eval-as-product adds the active components: you can replay a captured trace against a new prompt, score the historical run against new judges, and A/B compare variants. The line is blurry, modern platforms increasingly do both, but the core distinction is read-only vs replay-capable.
44.7.2 The Eval-First Workflow: Experiment, Score, Compare, Iterate
The workflow that eval-as-product platforms optimize for has four steps, and the shape of the workflow is what distinguishes good platforms from bad ones.
Step 1: Experiment. Define a hypothesis (a new prompt, a new model, a new tool, a new retrieval strategy), and a dataset (production traces, a curated golden set, a synthetic eval set). The platform runs the hypothesis against the dataset and produces a result table: one row per dataset item, one column per metric.
Step 2: Score. Each row's output is scored along multiple axes: rule-based metrics (exact-match, JSON validity), LLM-as-judge scores (helpfulness, faithfulness), and custom metrics (latency, cost, token count). The good platforms make adding a custom metric a 5-minute job: write a function that takes (input, output, expected) and returns a score, register it as a scorer.
Step 3: Compare. The platform diffs your experiment against a baseline (the production prompt, the last shipped version). Per-row diffs highlight which items improved, which regressed, and by how much. Aggregate diffs show overall direction. This is the step where most teams catch the cases that CI gates miss: a 0.5% aggregate improvement that masks a 20% regression on one specific user segment.
Step 4: Iterate. Based on the comparison, refine the prompt, retry, score, compare. The fastest platforms make this loop tight (sub-minute for small datasets). The slow ones make it slow enough that teams stop using them after a week.
The crucial insight is that this is the same loop that ML researchers run for fine-tuning experiments, but with a UI tailored for prompt-engineering iteration cycles instead of training-run cycles. The platforms that have succeeded in 2025-2026 are the ones that nailed the UI ergonomics, the ones that treated this as an ML-platform problem in disguise.
44.7.3 Braintrust: The Polished Default
Braintrust (braintrust.dev) is the most polished of the three platforms covered here, and it has captured a large share of the venture-backed AI-product market. Its design choices reflect that audience: rich playground for prompt iteration, deep integration with OpenAI and Anthropic SDKs, automatic regression detection against the previous experiment, and a Python/TypeScript SDK that maps cleanly onto existing eval patterns.
The core abstractions are datasets (collections of input/expected-output pairs), experiments (a run of your task against a dataset), and scorers (functions that judge each row of an experiment). The Braintrust scorer library includes pre-built scorers for many common metrics: Factuality (LLM-as-judge for factual accuracy), Faithfulness (RAG-style faithfulness scoring), AnswerRelevancy, JSONDiff (structural diff for JSON outputs), Levenshtein, NumericDiff, Sql (SQL-equivalence checking), and others. You can add custom scorers by writing a Python or TypeScript function.
Strengths:
- Rich scoring DSL. The scorer library is broad and well-curated. The same scorer interface works for batch eval, live scoring, and replay.
- OpenAI/Anthropic native. First-class integration with both major provider SDKs. Drop-in proxy mode that captures all calls without code changes is a major time-saver for teams already on those SDKs.
- Automatic regression detection. Compare any new experiment against the production baseline with one click; the UI surfaces per-row regressions and aggregates.
- Playground. Interactive prompt editing with side-by-side comparison across models, useful for the PM-and-domain-expert audience.
Weak spots:
- Enterprise pricing. The free tier is generous for small projects, but enterprise pricing scales with traffic volume and gets expensive quickly. Teams running millions of traced requests per day are typically looking at five-figure annual contracts.
- Closed-source. Self-hosting is not an option; if you need on-premises evaluation (regulated industries, air-gapped environments), Braintrust is off the table.
- Vendor lock-in risk. The scorer DSL is proprietary; migrating away requires rewriting the eval definitions.
44.7.4 Latitude: The Open-Source Alternative
Latitude (latitude.so) takes the opposite design stance: open-source under an MIT-style license, self-hostable, prompt-versioning as the central abstraction. The hosted SaaS version exists, but Latitude's pitch is the on-premises option. For regulated industries (finance, healthcare, defense) and for teams that already run Postgres-and-Docker infrastructure, the self-hostable property dominates other considerations.
Latitude's primary abstraction is a prompt, with versioning, parameters, and metadata as first-class properties. Datasets and experiments build on top of prompts. The LLM-as-judge functionality is built in: you write a judge prompt in the same DSL as a regular prompt, and Latitude scores experiments using it.
Strengths:
- Open-source and self-hostable. Run it on your own Postgres and Docker. The license is permissive enough for commercial use.
- Prompt-versioning-first. Treats prompts as the unit of work, with diff, history, and rollback. For teams whose iteration is mostly prompt-engineering (rather than full-stack agent development), this is a natural fit.
- Built-in LLM-as-judge. Judge prompts are first-class objects, not custom scorer code.
- Cheap. Self-hosted incurs only your infra cost; the hosted tier is priced below Braintrust.
Weak spots:
- Less polished UI. The trade-off for being open-source: the UX is functional but lags Braintrust in places.
- Smaller scorer library. You will write more custom judges; the pre-built scorer catalogue is thinner.
- Younger community. Fewer Stack Overflow answers, fewer integration examples for niche provider SDKs.
44.7.5 Laminar: Observability Plus Eval, Span-Based
Laminar (lmnr.ai) sits in a third position: it merges observability and eval into a single span-based system, treating every LLM call (and every tool call, every retrieval, every span in your trace) as both an observability event and a potential eval target. The unit of work is the span, and you can attach scorers to spans the same way you attach metrics to traces.
Laminar's design choices favor agent-style applications where the trace is the primary object of analysis: long traces, many tool calls, multi-turn conversations, hierarchical span structure. For teams whose evaluation question is "did this 30-step agent trajectory succeed?" rather than "did this single LLM call produce the right answer?", Laminar's span-centric model maps more cleanly.
Strengths:
- Cheap and fast. Pricing is among the lowest in the category. Ingestion latency is low; queries on large trace sets are fast.
- Span-based filtering and scoring. Filter traces by any span property; attach scorers at span granularity rather than trace granularity. Useful for agent debugging.
- Combined observability and eval. One platform for both jobs, with a unified trace model. Fewer tools to integrate, fewer SDKs to learn.
Weak spots:
- Newer and less mature. Smaller team, fewer integrations, fewer pre-built scorers than Braintrust. Documentation gaps in places.
- Self-hosting requires more legwork. The open-core model exists, but the deployment story is rougher than Latitude's.
- Less polished playground. The interactive prompt-editing UX is functional but not the equal of Braintrust's.
Comparison table
The decision matrix below summarizes the three platforms (and includes LangSmith and OpenAI Evals as anchors) across the dimensions that typically drive selection.
| Property | Braintrust | Latitude | Laminar | LangSmith | OpenAI Evals |
|---|---|---|---|---|---|
| Self-hostable | No | Yes (MIT) | Partial (open-core) | Enterprise only | Yes (Apache-2) |
| Free tier | Generous | Cloud free; OSS free | Free up to N spans | Limited | N/A (self-run) |
| SOC-2 | Type II | Type II (cloud) | In progress | Type II | N/A |
| Python SDK | Mature | Good | Good | Mature | Basic |
| TypeScript SDK | Mature | Good | Good | Mature | Community |
| Pre-built scorers | ~25 | ~10 | ~15 | ~12 | ~10 |
| Multi-judge support | Yes | Yes | Yes | Yes | Manual |
| Live-traffic scoring | Yes | Yes | Yes (span-based) | Yes | No |
| Replay UX | Best-in-class | Good | Span-based | Good | CLI only |
| Best for | Polished default | Regulated / OSS | Agents / spans | LangChain stacks | Static CI eval |
This category is moving fast. The features, pricing, and SOC-2 status of each platform have shifted at least once per quarter through 2024-2026. Treat the table above as a starting point for a 2026 selection, not a permanent reference. Verify the specifics from each vendor's docs before committing to a contract; a feature that wasn't available six months ago may be GA by the time you read this section.
44.7.6 Wiring Braintrust Into a Production Agent Loop
The simplest useful Braintrust integration: instrument your production agent to log every run to Braintrust, then run a nightly job that scores the previous day's runs and surfaces the results in the Braintrust UI.
# Input: prod traces logged to Braintrust by braintrust.wrap_openai()
# Output: nightly scored experiment in the Braintrust UI
import braintrust
from braintrust import init_dataset, Eval
from autoevals import Factuality, AnswerRelevancy, JSONDiff
# 1) at app startup, wrap OpenAI so every prod call is auto-logged
from openai import OpenAI
client = braintrust.wrap_openai(OpenAI()) # traces -> project "prod-agent"
# 2) nightly: pull yesterday's traces as a dataset, score against scorers
def nightly_score():
dataset = init_dataset(project="prod-agent", name="yesterday",
filter="created > now() - interval '1 day'")
Eval(
name="prod-agent-nightly",
data=lambda: dataset,
task=lambda row: row["output"], # replay-mode: score existing outputs
scores=[Factuality(), AnswerRelevancy(), JSONDiff()],
)
if __name__ == "__main__":
nightly_score() # cron: 0 3 * * *wrap_openai() call at app startup captures every LLM call without code changes; the nightly cron rescores the captured traces against your scorer library.The same pattern works in TypeScript, in Latitude (with a different SDK shape), and in Laminar (with a span-filter instead of a trace-filter). The interesting part is not the SDK, it is the workflow: scoring happens after the fact, on real traffic, with the latest version of your scorer library. If you change a scorer's prompt, you can rescore the last month of traffic with one command and see whether the new scorer agrees with the old one on the same data.
44.7.7 When Not to Use Eval-as-Product
Eval-as-product is not a universal good. The platforms have real costs (subscription fees, integration effort, vendor lock-in), and there are workflows where those costs do not pay back.
Fully automated, CI-gated eval. If your eval is 100% rule-based or unit-test-style (exact-match against expected outputs, JSON-schema validation, latency thresholds), and there is no human review loop, then a simple promptfoo or pytest harness running in CI is sufficient. The eval-as-product features (replay UX, side-by-side comparison, live scoring) add little value to a workflow that does not use them.
Tiny traffic, slow iteration. A team shipping a low-volume internal tool that updates its prompts once a quarter does not need a replay loop. The fixed cost of adopting a platform exceeds the savings.
Regulated environments without self-hosting. If you cannot send production data to a third-party SaaS, Braintrust and Laminar's hosted tiers are off the table. Latitude's self-host option or a custom-built solution becomes the relevant choice.
When your eval workflow is fundamentally upstream of LLMs. If your team's evaluation is mostly about classical ML (a tabular classifier, an embedding retriever, a search-quality A/B test), MLflow or Weights and Biases are a better fit. Eval-as-product platforms are optimized for LLM-shaped evaluation; using them for non-LLM workloads is forcing a square peg into a round hole.
An early-stage startup integrated Braintrust during their first three weeks, before they had any production traffic. They built scorer rubrics, set up nightly jobs, and configured dashboards. Over the next six weeks, the eval setup consumed about 30% of one engineer's time, and the dashboards showed nothing useful because there was no traffic. When traffic eventually arrived, the prompts had changed enough that the original scorers no longer matched the task. Lesson: eval-as-product platforms shine when there is enough live traffic to replay and enough prompt iteration to compare. Before that, a simple pytest harness is fine, and a paid platform is premature. The right time to adopt is usually somewhere between the first 1,000 production requests per week and the first major prompt-revision cycle.
44.7.8 The Platform vs. Build Decision
The recurring question: should we adopt a platform or build the equivalent in-house? For most teams in 2026, the answer is platform. The integration effort is hours to days, not weeks; the feature surface (replay, side-by-side, scorer library, live scoring, multi-judge orchestration) is hard to replicate quickly; and the platforms genuinely move faster than internal eval teams can.
The cases where building in-house pays back are narrow but real:
- Air-gapped or PII-saturated environments. Where no SaaS option is acceptable and Latitude's OSS does not fit your stack.
- Highly domain-specific scoring. If your eval is dominated by a single bespoke metric (code-execution success, theorem-proving validity, drug-interaction safety) and the platform's pre-built scorers add little value, a thin in-house harness around your bespoke scorer may be enough.
- Eval as part of a larger ML platform. If your organization already runs MLflow or W&B at scale, integrating LLM eval into that stack may produce a more coherent system than adding a separate platform.
For everyone else, the platform-or-build calculus comes out heavily in favor of adopting one of the three platforms covered here, ideally after running a 2-week trial with at least two of them on your real data.
Three trends to watch in 2026-2027:
- Synthetic eval generation. Platforms are starting to generate eval datasets from production logs automatically (taking real traces, clustering them, sampling representative examples). This reduces the manual cost of building eval sets but introduces its own bias: the synthetic set reflects the model's current strengths, not the failure modes you care about.
- Live judge calibration. Tools that automatically detect when an LLM-as-judge has drifted from human preferences, by sampling a small fraction for human review and recalibrating the judge prompt or model. Promising but still early.
- Agent-trajectory eval. For multi-step agents, the unit of eval is no longer a single LLM call but a full trajectory (planning, tool use, recovery). Platforms are scrambling to add hierarchical span scoring; expect the agent-eval feature gap to close in 2026-2027.
Explore Further: Run a side-by-side trial of Braintrust and Latitude on the same 200 production traces. Define three scorers, two automatic and one LLM-as-judge, and run the same experiment in both platforms. Compare ingestion latency, UI ergonomics, and scorer agreement. The result is your team's data-driven choice between the two.
In late 2024 Braintrust's seed-stage pitch deck reportedly opened with a slide that just read "Stripe of Evals". The line caught fire: by Q2 2025 at least three competitors (Latitude, Laminar, and Helicone's eval module) used variations of "Stripe for X" to describe their own positioning to investors. Bessemer Venture Partners' "State of the Cloud" recap that year had to add a footnote acknowledging that the LLM-eval segment had quietly invented a new sub-genre of pitch-deck cliche. The pattern persists: in 2026, calling a startup "the Stripe of evals" is both a compliment and a recruiter's red flag, depending on which side of the screen you are on.
- Eval-as-product is a distinct category from eval-as-CI and from observability. Its core operations are live scoring, replay, and side-by-side comparison.
- Braintrust is the polished default; Latitude is the OSS choice; Laminar is the span-native option. Pick based on hosting constraints, scorer library needs, and trace-shape priorities.
- Adopt when iteration is active and traffic is non-trivial. Premature adoption (before traffic exists) wastes engineering time on dashboards no one reads.
- Replay is the most underused feature. Most teams adopt for live scoring and discover the replay loop later; consider designing your integration to use replay from day one.
- Keep eval-as-CI alongside. Eval-as-product complements CI gates, it does not replace them. Both should run.
Exercises
You are choosing an eval platform for a healthcare-AI startup that processes patient-derived text and is subject to HIPAA. Production traffic is ~10,000 LLM calls per day, the team has 3 engineers, and the prompt iteration rate is weekly. Pick a platform, justify the choice, and identify the top three risks of your selection.
Answer Sketch
Latitude (self-hosted) is the strongest fit: HIPAA-compliance on a SaaS requires either a BAA (some platforms offer one, some do not) or self-hosting; the 10K/day traffic and weekly iteration rate justify a real platform over a custom harness; the team size is small enough that the OSS option is manageable. Risks: (1) UI maturity lags Braintrust, slowing the iteration loop; (2) smaller pre-built scorer library means more in-house scorer work; (3) Latitude OSS deployment maintenance is your team's responsibility, including security patches and upgrades. Mitigation: budget for 0.25 FTE on eval-platform maintenance.
You set up a replay loop on production traces, sampling 500 traces per week. After three months, your replay-based regression detection misses an important regression that users complain about. Hypothesize three reasons the replay sample missed it, and propose mitigations.
Answer Sketch
(1) Sampling bias: random sampling under-represents rare failure modes. Mitigation: stratified sampling that oversamples segments where past failures have occurred. (2) Distribution drift: production traffic changed faster than the sample refreshed (e.g., a new user segment arrived). Mitigation: shorten the replay window and add a freshness check that compares the current sample's distribution to the previous sample. (3) Scorer-rubric drift: the regression manifests on a dimension the current scorers do not measure (e.g., tone, brand voice). Mitigation: periodically review user-complaint themes and add scorers for dimensions that complaints surface.
Implement a script that takes two experiment IDs from Braintrust (or Latitude), pulls the per-row scores from each, and reports the rows where experiment B regressed more than 20% relative to experiment A on any scorer. Sort the regressions by magnitude.
Answer Sketch
Use the platform's Python SDK to fetch both experiments' rows. Match rows by input ID (each row has a unique input identifier). For each matched pair, compute the per-scorer delta (B - A) and identify rows where any scorer's relative delta is below -20%. Sort by absolute relative delta, descending. Print a table of (input_id, scorer_name, score_A, score_B, relative_delta). Optionally, fetch the input text and outputs for the top 10 regressions and write them to a CSV for manual review.
You want to use three different LLMs as judges (GPT-4o, Claude Opus, Gemini 2.5 Pro) and aggregate their scores. Describe (a) the aggregation rule, (b) how to handle the case where one judge consistently disagrees with the other two, and (c) the cost-benefit trade-off of multi-judge versus single-judge.
Answer Sketch
(a) For categorical judgments (win/lose/tie), use majority vote with ties handled explicitly; for numeric scores, use median (robust to single-judge drift). (b) Track per-judge agreement rate against the consensus; if one judge consistently disagrees, audit its prompt or replace it. Persistent disagreement may indicate genuine ambiguity in the task, not judge failure. (c) Multi-judge typically reduces noise and bias but costs 3x the API spend; the break-even depends on the decision stakes: high-stakes release gates justify multi-judge, day-to-day prompt iteration usually does not.
You have a team of two ML engineers and a budget of one engineer-month to set up evaluation infrastructure. List the features you would build in-house first (rank them) and identify the point at which adopting a platform becomes the right move.
Answer Sketch
Priority order: (1) a static eval harness around pytest with a fixed golden set and rule-based scorers; (2) trace logging to Postgres with PII redaction; (3) a simple replay script that runs prompts against the trace store; (4) a basic LLM-as-judge integration for one or two judges. The point at which a platform pays back: when you start needing side-by-side UIs that PMs and domain experts can use, when you have more than three concurrent prompt experiments to track, or when your eval-set curation becomes a multi-engineer effort. In dollar terms, when the engineering time spent on internal eval tooling exceeds the platform's annual fee, switch.
What Comes Next
The next section covers self-hosted eval orchestration: when the off-the-shelf platforms don't fit, how to build a credible in-house eval pipeline using open-source primitives (Postgres for trace storage, Temporal for replay orchestration, Prefect for nightly jobs). Continue to Section 45.1: Platforms.