My LLM agent was confident, eloquent, and wrong. The fallback handoff to a human agent fixed the wrongness. Confidence and eloquence had to be retrained from scratch.
Prompt, Humbled Conversational AI Agent
This section continues Section 37.4, which covered the upstream half of multi-turn dialogue: conversation repair, topic management, and guided flows. Here we cover the downstream half: fallback strategies and human handoff (what to do when the model cannot answer), context window overflow management (what to do when the conversation gets too long), and a head-to-head comparison of conversation flow strategies. These flow-control patterns directly shape the user-facing reliability of any LLM chatbot or production agent, since most user dissatisfaction comes not from wrong answers but from ungraceful failure modes.
Prerequisites
This section continues from Section 37.4, which introduced agent handoff and channel routing in conversational AI systems. Familiarity with the LLM-as-orchestrator pattern (earlier in Chapter 37), basic agent orchestration (Part 6), and the conversational design primitives covered throughout this module is assumed.
One of the longest-running debates in conversational AI design is the handoff phrase. 'Let me transfer you to a specialist' tested better than 'I cannot help with that' by a factor of three in customer satisfaction surveys, despite saying essentially the same thing. The lesson generalizes: when an LLM agent reaches its limit, the difference between graceful and abrupt is mostly tone, and tone can be A/B tested like any other product feature. Failure modes deserve copywriting too.
37.4.4 Fallback Strategies and Human Handoff
Every conversational system encounters situations it cannot handle. The quality of the fallback experience often determines user satisfaction more than the happy-path experience. A well-designed fallback hierarchy moves through increasingly robust recovery strategies before resorting to human handoff.
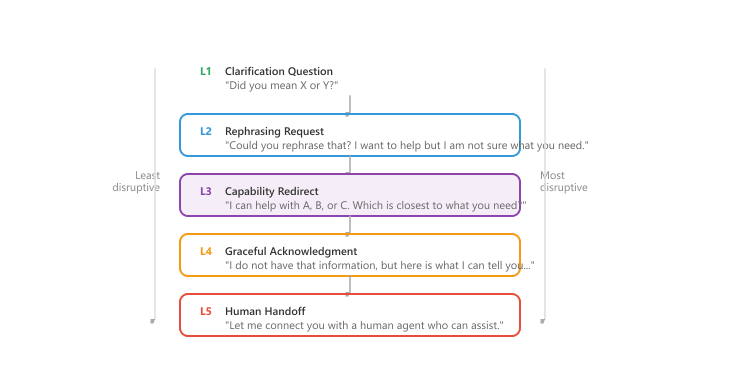
The best fallback strategies are invisible when they work. A clarification question that resolves the ambiguity, a topic redirect that moves the conversation to something the system can help with, or a graceful acknowledgment that narrows the user's request are all fallback strategies that the user may not even recognize as error recovery. The worst fallback is a generic "I don't understand" that provides no path forward. Figure 37.4.2a illustrates the fallback strategy hierarchy from least to most disruptive.
37.4.5 Context Window Overflow Management
As conversations grow long, the context window fills up. When the combined size of the system prompt, memory context, conversation history, and the new user message exceeds the model's context limit, something must be evicted. The strategy for what to remove and when to remove it has a significant impact on conversation quality.
Priority-Based Eviction
Priority-based eviction assigns importance scores to different types of content in the context window. When space runs out, the lowest-priority content is evicted first. System prompts and safety instructions always have the highest priority; routine conversation turns have the lowest.
# Define ContextPriority, ContextBlock, ContextBudgetManager; implement __init__, add_block, build_context
import tiktoken
from dataclasses import dataclass
from enum import IntEnum
class ContextPriority(IntEnum):
"""Priority levels for context window content.
Higher values are evicted last."""
SYSTEM_PROMPT = 100 # Never evict
SAFETY_RULES = 95 # Almost never evict
USER_PROFILE = 80 # High value, compact
ACTIVE_TASK_STATE = 75 # Critical for current task
KEY_FACTS = 70 # Important remembered facts
RETRIEVED_CONTEXT = 60 # RAG results
RECENT_TURNS = 50 # Last few conversation turns
SUMMARY = 40 # Compressed conversation history
OLDER_TURNS = 20 # Older conversation messages
EXAMPLES = 10 # Few-shot examples (first to go)
@dataclass
class ContextBlock:
"""A block of content in the context window."""
content: str
priority: ContextPriority
token_count: int
is_evictable: bool = True
label: str = ""
class ContextBudgetManager:
"""Manages context window allocation with priority-based eviction."""
def __init__(self, max_tokens: int = 128000,
reserve_for_output: int = 4096):
self.max_tokens = max_tokens - reserve_for_output
self.encoder = tiktoken.encoding_for_model("gpt-4o")
self.blocks: list[ContextBlock] = []
def add_block(self, content: str, priority: ContextPriority,
label: str = "", evictable: bool = True) -> None:
"""Add a content block to the context."""
tokens = len(self.encoder.encode(content))
self.blocks.append(ContextBlock(
content=content, priority=priority,
token_count=tokens, is_evictable=evictable,
label=label
))
def build_context(self) -> list[dict]:
"""Build the final context, evicting low-priority content if needed."""
total = sum(b.token_count for b in self.blocks)
if total <= self.max_tokens:
# Everything fits
return self._blocks_to_messages()
# Need to evict. Sort evictable blocks by priority (ascending)
evictable = [b for b in self.blocks if b.is_evictable]
evictable.sort(key=lambda b: b.priority)
tokens_to_free = total - self.max_tokens
freed = 0
evicted_labels = []
for block in evictable:
if freed >= tokens_to_free:
break
self.blocks.remove(block)
freed += block.token_count
evicted_labels.append(
f"{block.label} ({block.token_count} tokens)"
)
print(f"Evicted {len(evicted_labels)} blocks: "
f"{', '.join(evicted_labels)}")
return self._blocks_to_messages()
def get_budget_report(self) -> dict:
"""Report on how the context budget is allocated."""
total = sum(b.token_count for b in self.blocks)
by_priority = {}
for b in self.blocks:
name = b.priority.name
by_priority[name] = by_priority.get(name, 0) + b.token_count
return {
"total_tokens": total,
"max_tokens": self.max_tokens,
"utilization": total / self.max_tokens,
"allocation": by_priority,
"blocks": len(self.blocks)
}
def _blocks_to_messages(self) -> list[dict]:
"""Convert blocks to chat message format."""
# Sort by priority (highest first) for message ordering
sorted_blocks = sorted(
self.blocks, key=lambda b: b.priority, reverse=True
)
messages = []
for block in sorted_blocks:
role = "system" if block.priority >= 70 else "user"
messages.append({"role": role, "content": block.content})
return messagesSystem prompts containing safety rules, behavioral constraints, and guardrails should never be evictable. If the context window fills up and safety instructions are removed, the model may exhibit unexpected or harmful behavior. Always mark safety-critical content with the highest priority and set is_evictable=False. This is especially important for customer-facing applications where the safety prompt may contain refusal instructions or compliance requirements (see Chapter 47 for a full treatment of production safety).
37.4.6 Comparing Conversation Flow Strategies
| Strategy | Use Case | User Experience | Implementation Complexity |
|---|---|---|---|
| Free-form | Open-ended chat, creative writing | Natural, flexible | Low (model handles flow) |
| Guided flow | Onboarding, troubleshooting, intake | Structured, predictable | Medium (step definitions) |
| Hybrid flow | Customer support with tasks | Balanced | High (routing + flows) |
| Clarification-first | High-stakes, low-error tasks | Thorough but slower | Medium (detection logic) |
| Progressive disclosure | Complex products, education | Gradual, not overwhelming | Medium (step sequencing) |
Who: A conversational AI team at an online travel agency processing 200,000 bookings per month
Situation: Customers frequently changed requirements mid-conversation ("Actually, make it two rooms instead of one," or "Can we fly out a day earlier?"). The booking flow involved interdependent slots: changing the departure date affected flight availability, hotel pricing, and car rental schedules.
Problem: The linear slot-filling approach treated each change as a reset, forcing customers to re-confirm details they had already provided. A 5-slot booking that should take 8 turns often ballooned to 20+ turns when customers revised requirements.
Dilemma: Allowing free-form mid-conversation edits risked creating inconsistent booking states (e.g., a hotel checkout date before the check-in date). Strict validation after every change felt robotic and slowed the conversation.
Decision: They implemented a dependency graph for booking slots. When a slot changed, only dependent slots were re-validated. Independent slots (e.g., meal preferences) were preserved. Batch validation ran once before the final confirmation step.
How: The conversation state was stored as a structured JSON object with slot values, confidence scores, and dependency edges. The LLM received this state object in every turn and was instructed to output only the delta (changed slots). A rules engine propagated changes through dependencies.
Result: Average turns-to-completion dropped from 14 to 9. The "started over" frustration metric fell by 56%. Booking completion rate improved from 67% to 81% for multi-change conversations.
Lesson: Multi-turn systems that track slot dependencies and propagate changes selectively create a much smoother user experience than systems that either ignore changes or force a full restart.
Everything above (slot filling, repair, fallback, context budgeting) applies one-to-one to voice agents; the difference is that you now need VAD, ASR, an LLM, and TTS connected in a sub-second-latency pipeline. The pipecat-ai framework (Daily.co, 2024 to 2026) is the canonical Python orchestrator for that pipeline: it exposes each component as a Frame Processor, wires them into a Pipeline, and handles barge-in interruption and turn detection for you. Reach for it before stitching together Twilio, Deepgram, and ElevenLabs by hand.
Show code
pip install "pipecat-ai[daily,deepgram,openai,cartesia,silero]"
import asyncio
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineTask
from pipecat.services.deepgram.stt import DeepgramSTTService
from pipecat.services.openai.llm import OpenAILLMService
from pipecat.services.cartesia.tts import CartesiaTTSService
from pipecat.transports.services.daily import DailyTransport
from pipecat.audio.vad.silero import SileroVADAnalyzer
async def main():
transport = DailyTransport(
room_url, token, "Bot",
params=DailyTransport.params_cls(vad_analyzer=SileroVADAnalyzer()),
)
pipeline = Pipeline([
transport.input(),
DeepgramSTTService(api_key=DG_KEY),
OpenAILLMService(api_key=OPENAI_KEY, model="gpt-4o-mini"),
CartesiaTTSService(api_key=CART_KEY, voice_id="..."),
transport.output(),
])
await PipelineRunner().run(PipelineTask(pipeline))
asyncio.run(main())LLM-as-judge for conversations uses a separate LLM to evaluate dialogue quality across dimensions like coherence, helpfulness, and persona consistency, reducing the need for expensive human evaluation. Automated red-teaming generates adversarial conversation flows designed to trigger safety failures, persona breaks, or Section 37.2. Conversation simulation frameworks (e.g., LMSYS Chatbot Arena, MT-Bench) are standardizing how we compare conversational systems. Research into preference-based evaluation is developing methods that directly optimize for user satisfaction rather than proxy metrics like BLEU or perplexity.
- Repair mechanisms are essential: Clarification, correction, and confirmation patterns transform a brittle system into a robust one. The confidence threshold for triggering clarification is one of the most important tuning parameters.
- Topic management prevents context loss: A topic stack preserves context for suspended topics, allowing seamless switching and resumption. Without it, users lose progress every time they ask an off-topic question.
- Guided flows need flexibility: Structured conversation flows should allow temporary deviations and return gracefully. Rigidly refusing off-script questions creates a terrible user experience.
- Fallbacks should be invisible: The best fallback strategies resolve problems without the user noticing. Work through a hierarchy from least disruptive (clarification) to most disruptive (human handoff).
- Context overflow is an engineering problem: Priority-based eviction ensures the most important content survives when the context window fills up. Safety rules and system prompts must never be evicted, while examples and old turns can be sacrificed first.
Show Answer
Show Answer
Show Answer
Show Answer
Show Answer
Exercises
Name three types of conversation repair patterns and give an example of each.
Show Answer
(a) Self-correction: "Wait, I meant Tuesday, not Monday." (b) Clarification request: "Can you be more specific about which account?" (c) Confirmation check: "Just to confirm, you want to cancel the subscription?"
A user is discussing billing, then switches to a technical question, then asks to go back to billing. How should the topic management system handle this sequence?
Show Answer
Use a topic stack: push "billing" context when the conversation starts, push "technical" when the user switches (saving billing context), pop "technical" when user says "go back to billing" and restore the saved billing context. This preserves state for each topic.
Compare free-form conversation with guided conversation flows. When should a system switch from free-form to a guided flow?
Show Answer
Free-form is good for open-ended queries and exploration. Switch to guided flows when the task requires specific information in a specific order (e.g., filing a claim, making a reservation). The trigger is usually an identified intent that maps to a known structured task.
List the fallback strategies from least to most disruptive. Why should the system exhaust lower-level strategies before escalating?
Show Answer
Least to most disruptive: (1) clarification question, (2) offer suggestions, (3) rephrase and retry, (4) narrow the scope, (5) offer alternative channels, (6) escalate to human. Lower levels preserve conversation flow; escalation breaks it and adds cost.
A customer support conversation has reached 50 turns and the context window is full. Describe a strategy that keeps the conversation coherent without losing critical information from earlier turns.
Show Answer
Maintain a structured summary of the conversation so far (key facts, decisions, open issues) that is updated every 10 turns. Use vector memory for specific details. The context window contains: system prompt + structured summary + last 5 turns + any retrieved memories relevant to the current question.
Write a classifier that detects when a user is correcting a misunderstanding (e.g., "No, I meant...", "That is not what I asked"). Test on 20 example utterances.
Implement a topic stack that detects topic switches, saves the context of the previous topic, and resumes it when the user returns. Test with a conversation that switches between 3 topics.
Build a simple guided conversation flow engine that walks the user through a multi-step process (e.g., filing a support ticket). Handle out-of-order responses and missing information gracefully.
Build an automated conversation quality evaluator that scores a multi-turn dialogue on: (a) task completion, (b) coherence, (c) repair effectiveness, and (d) user satisfaction estimation. Use LLM-as-judge for each metric.
What Comes Next
In the next section, Section 37.5: Long-Term Memory and Self-Managing Architectures, we return to memory: vector stores, MemGPT/Letta, user profiles, memory-as-a-service platforms, consolidation, and how to evaluate memory quality. After that, Section 39.1: Voice Agents and Speech Interfaces takes conversational AI beyond text into voice and multimodal interaction.
For the long-context and memory architectures (summarization buffers, retrieval-based memory) that make multi-turn coherent at scale, see Section 32.1: RAG Foundations. For the dialogue-evaluation datasets (MultiWOZ, MT-Bench, Arena) that grade conversation quality, see Section 40.3: Datasets and Benchmarks. For the conversational-safety guardrails (policy refusals, jailbreak-resistance), see Section 48.1: What Guardrails Are.