The best LLM system is the one that gets better every day without anyone noticing it changed.
Deploy, Silently Evolving AI Agent
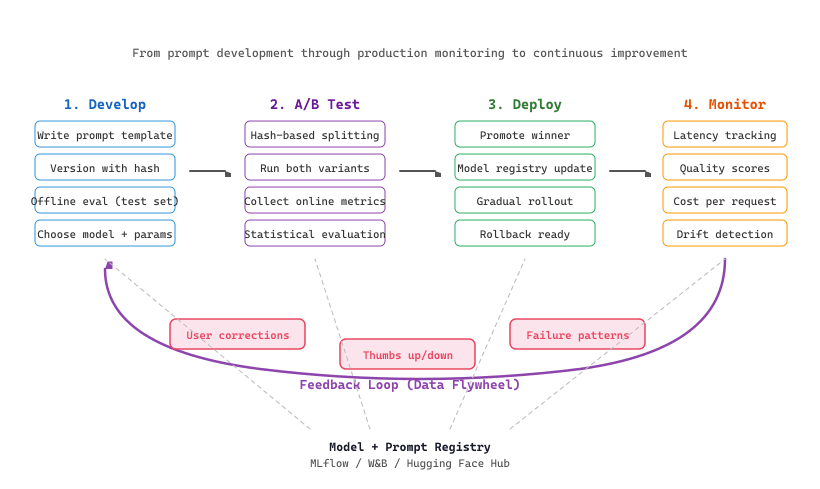
LLMOps extends MLOps with practices specific to language model applications. Prompts are code that must be versioned. Model behavior must be tested in production through A/B experiments with statistical rigor. User feedback must flow back into evaluation datasets, fine-tuning data, and prompt improvements to create a continuously improving system. Building on the evaluation practices from Chapter 42 and the observability tools from Section 42.6, this section covers the operational practices that separate prototype LLM apps from production-grade systems that improve over time.
Prerequisites
Before starting, make sure you are familiar with the production fundamentals from Section 62.1. The evaluation metrics covered earlier in the book provide the measurement framework that LLMOps builds upon. Application-architecture and deployment patterns are revisited in detail later in the book.
62.2.1 Prompt Versioning
When: always. If you cannot roll back, you cannot ship safely. How: treat (model_id, model_version, prompt_id, prompt_version, retriever_index_version) as a single deployable unit, versioned in a manifest. A deploy publishes the manifest to a feature flag or config store; rollback flips the pointer to the previous manifest in under 30 seconds. Watch for: stateful side effects that survive rollback (a retriever index migrated forward cannot be rolled back without dual-write, see Pattern P2 elsewhere in this chapter). Also: bake "rollback rehearsal" into your runbook quarterly. The first time you try to roll back at 3 a.m. is the worst possible time to discover that the previous manifest is missing a now-required field.
What it is: After each prompt or model change, route 5% of live traffic to BOTH old and new versions for 24h. Run an LLM-as-judge on the paired outputs. Alert if the new version loses on more than 15% of comparisons. Auto-promote if the new version wins by >10% with statistical significance.
When not to use it: Pre-launch or single-developer projects with no users yet. Canary infrastructure has setup cost; pay it once you have enough traffic that 5% provides statistical signal in a day.
What it is: Track outcomes that look like success at the protocol level (HTTP 200, parseable JSON, non-empty result) but are still business-failures (wrong answer, empty list, hallucinated content). Each path through the system has a "what counts as soft failure here" definition that gets monitored independently of the hard-failure rate.
When not to use it: Pure infrastructure services with no semantic notion of success/failure (a load balancer, a CDN). Soft-failure tracking requires a domain model.
Catalogue: See the full discussion + variants in this chapter's LLMOps coverage (Pattern P5).
The deep treatment of the underlying hallucination mechanism lives in Section 32.1. The discussion below focuses on production-side detection.
A teammate "just tweaks the system prompt real quick" in production. Response quality drops 15%. Nobody knows what changed because prompts live as string literals scattered across the codebase with no version history, no diff, and no rollback mechanism. In traditional software, this is the equivalent of editing production code without source control. It sounds absurd, yet most LLM teams operate exactly this way.
Prompt versioning solves this by treating every prompt as a versioned artifact with a content hash, metadata, and a deployment history.
The unofficial motto of LLMOps is "git for prompts, but also for the model, the data, the config, and your sanity." Most teams discover they need prompt versioning the same way most people discover they need backups: right after losing something important.
By the end of this section, you will have a complete LLMOps toolkit: content-addressable prompt registries, A/B testing frameworks with statistical rigor, and feedback loops that continuously improve your system. We start by building a prompt registry from scratch.
LLMOps is like running a professional kitchen where every recipe (prompt) lives in a version-controlled binder. When a chef modifies a recipe, the old version is preserved, the new one gets a date stamp, and you can always roll back to Tuesday's sauce if Wednesday's experiment flops. A/B testing is running two dishes as daily specials and tracking which one customers reorder. The feedback loop is reading the comment cards. Unlike a kitchen, though, your "recipes" are serving thousands of customers simultaneously, so a bad tweak scales instantly.
import json, hashlib
from datetime import datetime
from pathlib import Path
class PromptRegistry:
"""Version and manage prompts with content-addressable storage."""
def __init__(self, store_path: str = "prompts/"):
self.store = Path(store_path)
self.store.mkdir(exist_ok=True)
def register(self, name: str, template: str, metadata: dict = None):
content_hash = hashlib.sha256(template.encode()).hexdigest()[:12]
version = {
"name": name,
"hash": content_hash,
"template": template,
"metadata": metadata or {},
"created_at": datetime.utcnow().isoformat(),
}
path = self.store / f"{name}_{content_hash}.json"
path.write_text(json.dumps(version, indent=2))
return content_hash
def get(self, name: str, version_hash: str = None):
if version_hash:
path = self.store / f"{name}_{version_hash}.json"
return json.loads(path.read_text())
# Return latest version
versions = sorted(self.store.glob(f"{name}_*.json"))
return json.loads(versions[-1].read_text()) if versions else None
registry = PromptRegistry()
v1 = registry.register("summarizer", "Summarize: {text}")
v2 = registry.register("summarizer", "Provide a concise summary of: {text}")
print(f"v1={v1}, v2={v2}")
Conduct a 30-minute red-teaming session on any chatbot you have access to. Try to make it: (1) reveal its system prompt, (2) generate content it is supposed to refuse, (3) role-play as a different AI, (4) produce contradictory safety responses. Document what works and what does not. This exercise builds practical intuition for LLM safety that no policy document can provide.
Netflix once ran an A/B test on thumbnail images and discovered that showing a villain's face increased click-through rates more than showing the hero. LLMOps teams report a similar phenomenon: the prompt variant that "feels" best to engineers often loses to a shorter, blunter version when measured against real users.
The fundamental insight behind LLMOps is that prompts are code. They should be versioned, tested, reviewed, and deployed with the same discipline as application code. The difference is that prompts interact with a non-deterministic system, so testing must be statistical rather than deterministic (connecting back to the evaluation rigor from Section 42.2). A prompt change that improves average quality by 5% but introduces a 2% regression on edge cases requires the same cost-benefit analysis as a code change that speeds up the happy path but breaks an uncommon workflow.
62.2.2 A/B Testing Framework
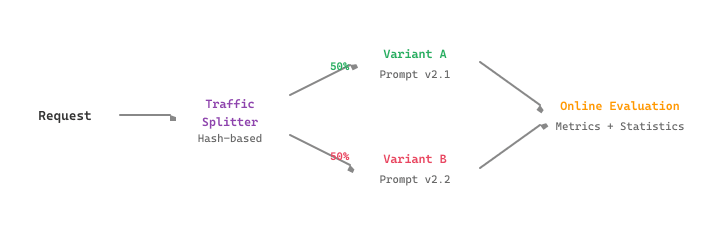
Figure 62.2.1b illustrates the end-to-end A/B testing pipeline, from hash-based traffic splitting through to online metric collection and statistical evaluation.
import hashlib, random
from dataclasses import dataclass
@dataclass
class ABExperiment:
"""Simple A/B test for prompt variants."""
name: str
variant_a: str
variant_b: str
traffic_split: float = 0.5 # fraction going to variant B
def assign(self, user_id: str) -> str:
"""Deterministic assignment based on user ID hash."""
h = hashlib.md5(f"{self.name}:{user_id}".encode()).hexdigest()
bucket = int(h[:8], 16) / 0xFFFFFFFF
if bucket < self.traffic_split:
return "B"
return "A"
def get_prompt(self, user_id: str) -> str:
variant = self.assign(user_id)
return self.variant_a if variant == "A" else self.variant_b
exp = ABExperiment(
name="summarizer_prompt",
variant_a="Summarize the following text:\n{text}",
variant_b="Write a 2-sentence summary:\n{text}",
)
for uid in ["user_101", "user_202", "user_303"]:
print(f"{uid} -> variant {exp.assign(uid)}")62.2.3 Online Evaluation and Feedback Loops
This snippet implements an online evaluation pipeline that collects user feedback and logs quality metrics in production.
from dataclasses import dataclass, field
from datetime import datetime
import statistics
@dataclass
class FeedbackCollector:
"""Collect and aggregate user feedback for LLM outputs."""
records: list = field(default_factory=list)
def log(self, request_id: str, variant: str, rating: int,
feedback_text: str = "", latency_ms: float = 0):
self.records.append({
"request_id": request_id, "variant": variant,
"rating": rating, "feedback": feedback_text,
"latency_ms": latency_ms,
"timestamp": datetime.utcnow().isoformat(),
})
def summary(self):
by_variant = {}
for r in self.records:
v = r["variant"]
by_variant.setdefault(v, []).append(r["rating"])
return {
v: {"mean": statistics.mean(ratings), "n": len(ratings)}
for v, ratings in by_variant.items()
}
Set a minimum sample size before drawing conclusions from A/B test results. A common mistake is stopping a test after 50 queries because variant B "looks 8% better." With small samples, random fluctuation easily produces 8% swings. Use at least 200 observations per variant for rating-based metrics, and 500 or more per variant for binary metrics like thumbs-up rate, to achieve statistical power above 80%.
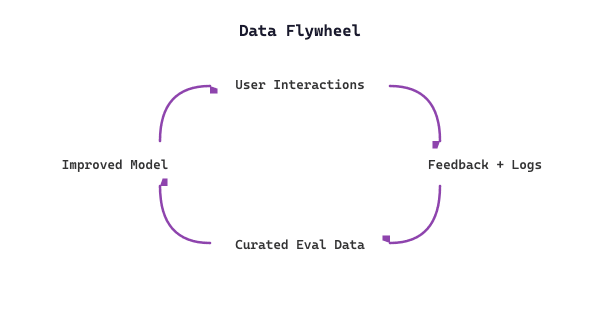
Over time, the feedback from A/B tests feeds into a continuous improvement loop. Figure 62.2.3a depicts this data flywheel, where user interactions generate feedback that becomes curated evaluation data for model improvement.
62.2.4 Model Registry
| Registry Feature | MLflow | W&B | Hugging Face Hub |
|---|---|---|---|
| Model versioning | Yes (stages) | Yes (aliases) | Yes (revisions) |
| Prompt versioning | Via artifacts | Via artifacts | Via model card |
| A/B experiment tracking | Native | Native | Limited |
| Deployment integration | SageMaker, Azure ML | Launch | Inference Endpoints |
| Self-hosted option | Yes (open source) | Enterprise | Yes (enterprise) |
# Experiment tracking setup
import mlflow
# Log a prompt experiment to MLflow
with mlflow.start_run(run_name="prompt_v2.1_test"):
mlflow.log_param("prompt_version", "v2.1")
mlflow.log_param("model", "gpt-4o-mini")
mlflow.log_param("temperature", 0.7)
# Log evaluation metrics
mlflow.log_metric("mean_rating", 4.2)
mlflow.log_metric("hallucination_rate", 0.03)
mlflow.log_metric("p50_latency_ms", 820)
mlflow.log_metric("cost_per_request", 0.0023)
# Log the prompt template as an artifact
mlflow.log_text(
"Write a 2-sentence summary of:\n{text}",
"prompt_template.txt"
)Prompt versioning should capture not just the template text but also the model name, temperature, max tokens, system prompt, and any few-shot examples. A prompt that works well with GPT-4o may fail with Claude or Llama, so the model is part of the prompt's identity.
A/B tests on LLM outputs require larger sample sizes than traditional web experiments because LLM quality metrics (like human ratings or LLM-as-Judge scores) have high variance. Plan for at least 200 to 500 samples per variant before drawing conclusions, and always compute confidence intervals rather than relying on point estimates.
The data flywheel is the most powerful long-term advantage of a production LLM system. Every user interaction generates data that can improve evaluation sets, fine-tuning corpora, and retrieval indices. Teams that invest in feedback collection infrastructure early will compound improvements over time, while teams that skip it remain stuck with static prompts and models.
Who: An AI product team at a SaaS company with 2 million support tickets per year
Situation: The team deployed an LLM to auto-summarize support conversations for agent handoffs. Initial quality was acceptable but inconsistent.
Problem: Without structured feedback, the team had no way to identify which summaries were helpful and which were misleading. A/B testing prompt variants took weeks because they lacked infrastructure to track variant assignments.
Dilemma: Investing in feedback infrastructure would delay the next feature launch by a month. Skipping it meant continuing to iterate blindly on prompt quality.
Decision: They built a lightweight feedback loop: thumbs up/down on each summary, plus a "needs correction" option that captured the agent's edited version.
How: Each summary was tagged with the prompt version hash, model name, and temperature. Weekly reports aggregated ratings by prompt version. Edited summaries became evaluation gold data and eventually fine-tuning examples.
Result: After three months, the feedback dataset contained 12,000 rated summaries and 800 corrected versions. A fine-tuned model trained on corrections scored 23% higher on faithfulness than the original prompted approach.
Lesson: The data flywheel is not theoretical; it produces measurable quality gains within months, but only if feedback collection infrastructure is built before optimization begins.
Open Questions:
- What does a mature LLMOps practice look like, and how does it differ from traditional MLOps? LLMs challenge existing MLOps assumptions about model training, versioning, and A/B testing.
- How should organizations manage prompt versioning and migration when prompts are a critical part of the application logic?
Recent Developments (2024-2025):
- Prompt management platforms (2024-2025) like PromptLayer, Humanloop, and Langfuse added version control, A/B testing, and rollback capabilities for prompts, treating them as first-class deployment artifacts.
Explore Further: Set up a prompt versioning workflow for an LLM application using an open-source tool. Create three prompt versions, A/B test them against your evaluation set, and practice a rollback when one underperforms.
- Version prompts with content-addressable hashing and store the complete configuration (model, temperature, system prompt, few-shot examples) alongside the template.
- Use hash-based traffic splitting for deterministic A/B assignment that remains consistent across user sessions.
- Collect structured feedback (thumbs up/down, ratings, corrections) on every production response to fuel the data flywheel.
- Plan for large sample sizes (200 to 500 per variant) and compute confidence intervals for LLM A/B tests due to high output variance.
- Track experiments in a model registry (MLflow, W&B) that captures prompts, metrics, and model configurations together.
- The data flywheel is a production LLM system's most valuable long-term asset; invest in feedback infrastructure early.
1. Why should prompt versioning use content-addressable hashing rather than sequential version numbers?
Show Answer
2. Why is hash-based traffic splitting preferred over random assignment in A/B tests?
Show Answer
3. What is a data flywheel and why is it important for LLM applications?
Show Answer
4. What metadata should be stored alongside a prompt version for full reproducibility?
Show Answer
5. Why do LLM A/B tests require larger sample sizes than traditional web experiments?
Show Answer
Exercises
Explain why prompts should be treated as versioned artifacts, similar to source code. Describe the minimum metadata that should be stored alongside each prompt version.
Answer Sketch
Prompts directly control model behavior, so untracked changes can cause regressions. Minimum metadata: content hash (for identity), author, timestamp, target model, evaluation scores on a standard test set, deployment status (draft/staging/production), and a description of the change. This enables rollback, A/B testing, and audit trails, just as Git provides for code.
Describe how to set up an A/B test comparing two system prompt variants for a customer support chatbot. Include: traffic splitting, metrics to track, statistical test to use, and minimum sample size calculation.
Answer Sketch
Traffic splitting: randomly assign users (not requests) to variant A or B using a consistent hash on user_id. Metrics: task completion rate (primary), user satisfaction score, average handle time, escalation rate. Statistical test: chi-squared test for completion rate, Mann-Whitney U for satisfaction scores. Sample size: for a 5% minimum detectable effect on a 60% baseline completion rate at 80% power and 5% significance, you need approximately 1,500 users per variant. Run for at least one full business cycle (7 days) to account for daily patterns.
Design a feedback collection system that captures thumbs-up/thumbs-down ratings, optional text feedback, and automatic quality signals (response length, latency, tool call success rate). Describe the data pipeline from collection to actionable improvements.
Answer Sketch
Collection: UI sends feedback events with {trace_id, rating, comment, timestamp}. Pipeline: (1) Store in an analytics database joined with trace data. (2) Aggregate daily quality metrics. (3) Flag low-rated responses for human review. (4) Export highly-rated (prompt, response) pairs to a fine-tuning dataset. (5) Export low-rated responses to a "hard examples" evaluation set. (6) Surface patterns in negative feedback (e.g., topic clustering) to guide prompt improvements. The key is closing the loop: feedback must flow back into evaluation data and system improvements.
Sketch the end-to-end LLMOps pipeline for a production chatbot, from prompt change to deployment. Include: prompt version control, automated evaluation, A/B testing, monitoring, and feedback-driven improvement. Identify the manual vs. automated steps.
Answer Sketch
Pipeline: (1) Engineer edits prompt in version control (manual). (2) CI runs automated evaluation suite (automated). (3) If scores pass threshold, deploy to staging (automated). (4) Run canary tests on staging (automated). (5) If canary passes, start A/B test with 10% traffic (automated). (6) After reaching sample size, analyze results (semi-automated). (7) If A/B test wins, promote to 100% (manual approval, automated execution). (8) Monitor quality metrics (automated). (9) Collect user feedback (automated). (10) Review feedback and plan next iteration (manual). Steps 2-5 and 8-9 should be fully automated; steps 1, 6-7, and 10 benefit from human judgment.
Your LLM chatbot starts generating offensive responses after a provider model update. Describe the incident response process, from detection to resolution, including immediate containment, investigation, and post-mortem steps.
Answer Sketch
Detection: output guardrail alerts or user reports trigger the incident. Containment (minutes): roll back to the previous model version or activate a safe-mode prompt with stricter instructions. Investigation (hours): analyze flagged responses, identify the root cause (model update, prompt interaction, new attack vector). Resolution: implement additional guardrails, update the canary test suite to cover the failure mode, and coordinate with the provider. Post-mortem: document the timeline, root cause, impact, and preventive measures. Update the incident playbook and add regression tests.
What Comes Next
In the next chapter, Chapter 47: Safety, Ethics, and Regulation, we shift to security threats, hallucination detection in Section 49.5, regulation, and governance for LLM systems.