"The question is not whether neural networks have interpretable structure, but whether we have the patience and ingenuity to find it."
Probe, Relentlessly Curious AI Agent
Part II so far has been about LLMs as systems: how they are trained, what families exist, how they reason, how they are served. This chapter turns inward: what is actually happening inside the weights? You will learn how to read attention patterns, run probing classifiers, identify circuits and induction heads, and use sparse autoencoders to find interpretable features. Interpretability sits in Part II because every Part-III-onward chapter implicitly assumes the model behaves predictably, and this chapter is where you learn the tools to verify that.
Chapter Overview
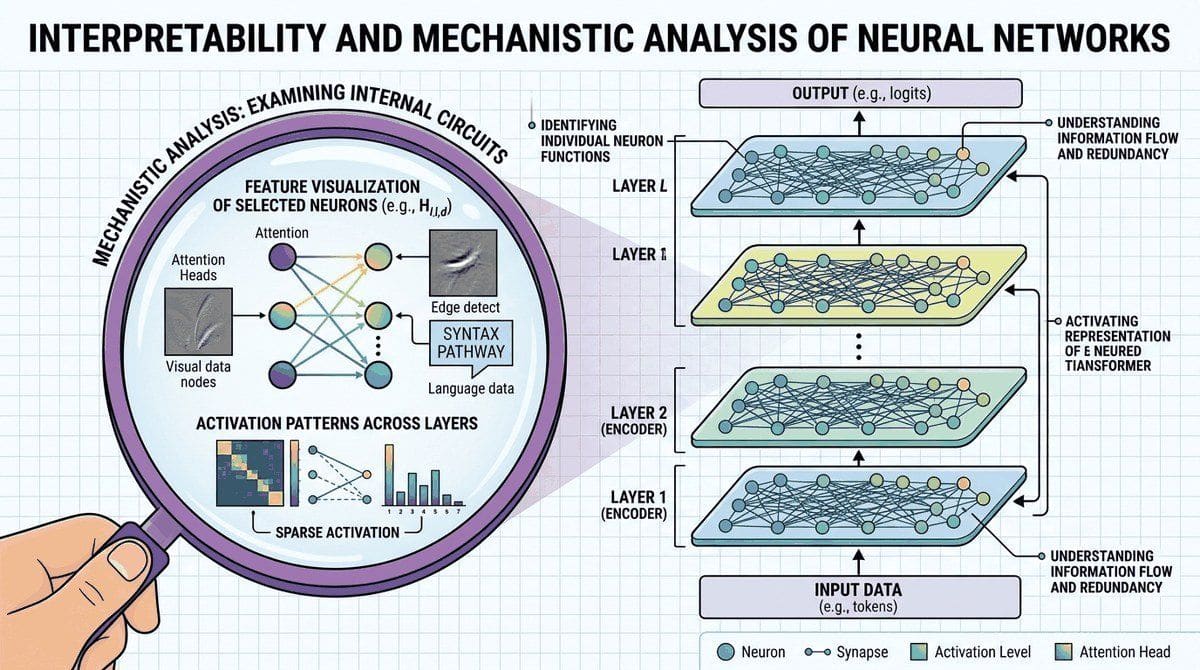
Imagine deploying a medical AI that recommends a treatment, and a doctor asks, "Why this recommendation?" You open the model's attention weights and find it fixated on a patient's zip code, not their symptoms. Without interpretability tools, you would never have caught this failure. As large language models are deployed in high-stakes applications, the question "why did the model produce this output?" becomes critical. Interpretability research aims to open the black box of transformer models, revealing the internal computations that drive predictions, the features that neurons encode, and the circuits that implement specific behaviors.
This chapter covers the full spectrum of interpretability methods for LLMs. It begins with attention analysis and probing classifiers, which offer accessible entry points for understanding model internals. It then advances to mechanistic interpretability, the ambitious program of reverse-engineering neural networks at the level of individual features and circuits. The chapter also covers practical interpretability tools for debugging, model editing, and representation engineering, as well as formal attribution methods for explaining transformer predictions.
By the end of this chapter, you will be able to analyze attention patterns to understand model behavior, use probing classifiers to test what information is encoded in hidden states, apply sparse autoencoders to extract interpretable features, and employ attribution methods to explain individual predictions.
As LLMs become more capable, understanding what they have learned and why they produce specific outputs becomes critical. Interpretability tools like probing, attention analysis, and mechanistic interpretability complement the alignment and safety techniques in Chapter 18 (Alignment, RLHF & DPO) and Chapter 48 (Guardrails & Runtime Safety), helping you build systems you can trust and debug.
- Visualize and interpret attention patterns, including induction heads, previous-token heads, and positional patterns
- Design and train probing classifiers to test whether specific linguistic or semantic features are encoded in hidden states
- Explain the logit lens and tuned lens techniques for inspecting intermediate representations
- Describe the circuits and features framework for mechanistic interpretability and the role of sparse autoencoders
- Apply activation patching to localize which model components are responsible for specific behaviors
- Use TransformerLens and nnsight for hands-on mechanistic analysis of transformer models
- Apply feature attribution methods (Integrated Gradients, SHAP) to explain individual predictions
- Perform representation engineering and model editing (ROME, MEMIT) to modify specific model knowledge
- Compare attention rollout, gradient-weighted attention, and perturbation-based explanation methods
Prerequisites
- Chapter 3: The Transformer Architecture (multi-head attention, feed-forward layers, residual stream)
- Chapter 7: Modern LLM Landscape (model families, next-token prediction, embedding spaces)
- Chapter 1: Foundations of NLP & Text Representation (embeddings, vector spaces, similarity)
- Comfortable with PyTorch, including hooks, autograd, and tensor manipulation
- Linear algebra fundamentals (matrix multiplication, eigendecomposition, SVD)
Sections
- 10.1 Attention Analysis & Probing Attention patterns and probing classifiers are the most accessible tools for understanding what transformers learn. Entry
- 10.2 Mechanistic Interpretability Mechanistic interpretability aims to fully reverse-engineer neural networks into human-understandable components. Advanced
- 10.3 Practical Interpretability for Applications Interpretability is not just a research curiosity; it is a practical toolkit for building better models. Intermediate
- 10.3a Model Editing, Concept Erasure & Debugging Surgical weight editing (ROME, MEMIT), provable concept erasure (LEACE), CoT faithfulness, and debugging workflows. Intermediate
- 10.4 Explaining Transformers No single explanation method tells the whole truth about a Transformer architecture's predictions. Intermediate
- 10.5 Interpretability Tooling, Evaluation, and LLM-Assisted Explanation Production XAI libraries (Captum, LIME, BertViz), faithfulness vs. plausibility evaluation, and LLMs as explanation assistants for other models. Intermediate
- 10.6 Platforms Part II's platform question shifts from "where do I run a 100-million-parameter model" to "where do I run a 70-billion-parameter model when I do not own an H100". Intermediate
- 10.7 Interpretability Tools & Transformers Deep Dive The model-loading stack, tokenizer trio, mech-interp tier (TransformerLens, nnsight, SAELens), plus the Hugging Face Transformers deep dive. Intermediate
- 10.8 Serving Runtimes (vLLM, TGI, SGLang) vLLM with PagedAttention and continuous batching, Hugging Face Text Generation Inference (TGI), and SGLang. The three production runtimes for high-throughput serving. Intermediate
- 10.9 Datasets & Benchmarks Part II's datasets split into two roles: pretraining corpora (the trillions of tokens a frontier model ingested) and evaluation benchmarks (the suites researchers run to compare models). Intermediate
- 10.10 Models This section is a practical companion to the quantization theory in Chapter 10. Advanced
- 10.11 External Reading & Communities Part II's external-reading list is centrally about three things: keeping current with the frontier model zoo, going deep on tokenization, and going deep on mechanistic interpretability. Advanced
What's Next?
Next: Chapter 11: Working with LLM APIs, and with it, Part III. Parts I and II built up the model: from gradient to tensor to transformer to scaling law to interpretable circuit. From here we stop opening the engine and start driving. Part III shows you how to actually call these models in production code (OpenAI, Anthropic, Google, open routers), how to prompt them to behave, and when an LLM is the wrong tool for the job. The shift is from mechanics to behavior, from understanding to using.