The goal is not to build a smaller model, but to build a smaller model that remembers what the bigger one learned.
Distill, Memory-Retentive AI Agent
Knowledge distillation is the art of making small models behave like large ones. A 70B-parameter teacher model contains vast knowledge but is expensive to serve. By training a smaller student model to mimic the teacher's output distribution (not just its final answers), the student can inherit much of the teacher's capability at a fraction of the inference cost. This technique has produced some of the most remarkable results in the LLM space: Microsoft's Phi-3 models distilled from GPT-4 demonstrate that a 3.8B model can match models 10x its size. DeepSeek distilled its R1 reasoning model into compact variants that retain strong chain-of-thought abilities. The pretraining objectives from Section 6.2 explain how these teacher models acquired their knowledge in the first place.
Prerequisites
This section continues from Section 17.5. You should be comfortable with LoRA and QLoRA from this chapter and with full fine-tuning fundamentals from Section 16.1. The distillation discussion assumes basic familiarity with the Transformer architecture and with the cross-entropy loss from Section 0.1.
This continuation of Section 17.5 picks up the practical distillation pipeline and extends it to three production-relevant topics: the licensing constraints that decide whether you are even allowed to distill from a given teacher, speculative distillation that uses a small student to accelerate inference of a large model, and reasoning-trace distillation that transfers chain-of-thought capability into a model that otherwise could not afford it.
The term "distillation" comes from chemistry: extracting the essence of a substance by heating it and collecting what evaporates. Hinton, who coined the term for neural networks, liked the metaphor because the teacher's soft probability distribution contains richer information than hard labels alone. When a teacher says "this is 70% cat, 25% tiger, 5% dog," the student learns that cats and tigers are related. Hard labels ("cat") throw away that nuance entirely.
17.6.1 Distillation Licensing and Usage Policies
Before building a distillation pipeline, you must understand the legal constraints imposed by model providers. Most major LLM providers restrict or prohibit using their model outputs to train competing models. Violating these terms can result in service termination, legal liability, or both. The landscape varies significantly across providers.
17.6.1.1 Provider Policies (as of 2026)
| Provider | Output Usage for Training | Key Restriction |
|---|---|---|
| OpenAI | Prohibited for competing models | You may not use outputs to "develop any artificial intelligence models that compete with our Products and Services." Fine-tuning through OpenAI's own API is permitted. |
| Anthropic | Restricted | Usage policy prohibits using outputs to train models that compete with Anthropic's services. Research and internal use cases should be reviewed against current terms. |
| Google (Gemini) | Restricted | Terms of Service prohibit using Gemini outputs to develop "competing generative AI products." Google Cloud enterprise agreements may include different terms. |
| Meta (Llama) | Permitted with conditions | The Llama open license permits distillation. However, models with over 700 million monthly active users must request a separate license. |
| Mistral | Permissive | Apache 2.0 licensed models have no output restrictions. Commercial models accessed through API may have separate terms. |
| DeepSeek | Permissive | MIT license places no restrictions on output usage for training. |
The practical implication is clear: if you plan to distill knowledge from a proprietary API into your own model, verify that the provider's terms permit it. For many production use cases, starting with an open-weight teacher (Llama, Mistral, DeepSeek) avoids licensing uncertainty entirely. When using a proprietary API, the safest approach is to use the provider's own fine-tuning service rather than extracting outputs for external training.
Licensing terms change frequently. Always check the current Terms of Service before starting a distillation project. A policy that was permissive six months ago may have been revised. Enterprise agreements sometimes override standard terms, so consult your legal team if the project involves proprietary API outputs.
17.6.2 Speculative Distillation
Speculative decoding uses a small "draft" model to propose multiple tokens at once, which a larger model then verifies in a single forward pass. Speculative distillation trains the draft model specifically to mimic the larger model's token distribution, improving the acceptance rate (how often the large model agrees with the draft) and thus the overall throughput. This technique turns distillation into a serving-time optimization rather than just a training-time technique. Figure 17.6.3a shows this propose-and-verify workflow.
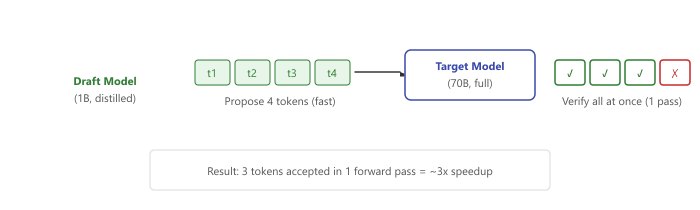
17.6.3 Distillation for Reasoning: Chain-of-Thought Preservation
Standard distillation transfers a teacher's input-output mapping to a smaller student, but this approach discards the teacher's intermediate reasoning. When a 70B model solves a math problem, it internally constructs a chain of logical steps before arriving at the answer. A student trained only on final answers learns what to output but not how to reason, limiting its ability to generalize to novel problems. Chain-of-Thought (CoT) distillation addresses this by training the student to reproduce the teacher's explicit reasoning traces alongside the final answers.
Formally, given a question $q$, the teacher produces a reasoning trace $r = (r_1, r_2, \ldots, r_k)$ followed by an answer $a$. Plain answer-only distillation trains the student to maximize $\log p_S(a \mid q)$, marginalizing the reasoning away. CoT distillation instead trains on the joint sequence $(r, a)$:
where the trajectory $y_{1:k+|a|}$ concatenates reasoning steps and the answer. The extra $\log p_S(r \mid q)$ term is what carries the procedural knowledge from teacher to student.

The procedure is straightforward. First, the teacher model generates solutions to a large set of training problems using chain-of-thought prompting, producing step-by-step reasoning followed by a final answer. Second, these complete reasoning traces become the training targets for the student. The student learns to generate the full chain of thought, not just the conclusion. This approach was central to the Distilled DeepSeek-R1 models, where 800K reasoning traces from the R1 teacher were used to fine-tune Qwen and Llama base models. The resulting students (1.5B to 70B parameters) achieved reasoning performance competitive with models several times their size.
CoT distillation introduces a design choice: should the student be trained on the teacher's complete reasoning trace, or should the traces be filtered and curated? In practice, filtering is essential. Teacher models sometimes produce redundant steps, circular reasoning, or incorrect intermediate conclusions that happen to reach the right final answer. A robust pipeline filters traces by (1) verifying the final answer against a ground truth, (2) checking that intermediate steps are logically consistent, and (3) removing excessively long or repetitive reasoning chains. The Orca series demonstrated that curating high-quality explanations (with explicit reasoning structure: "First, ..., Therefore, ..., Finally, ...") produces better students than training on raw, unfiltered teacher outputs.
A key finding from reasoning distillation research is that the student's reasoning format does not need to match the teacher's. A teacher that uses verbose, natural-language reasoning can be distilled into a student that produces compact, structured reasoning (numbered steps or symbolic notation) as long as the training data is reformatted accordingly. This flexibility allows practitioners to optimize the student's reasoning format for their deployment constraints: verbose reasoning for user-facing explanations, compact reasoning for latency-sensitive applications where the chain of thought is used internally but not shown to the user.
The aha: reasoning, from the model's point of view, is not a hidden internal process; it is a sequence of tokens the teacher wrote out. When a 7B student learns to produce "Step 1: identify the variables. Step 2: apply the formula. Step 3:..." in the same order the teacher did, it is not magically gaining the teacher's reasoning circuit, it is learning that this token pattern reliably precedes correct answers in training. The cheap part of intelligence (writing the steps) turns out to be most of intelligence: once the student emits the scaffolding tokens, they steer its own next-token predictions onto the correct path, the same way a human "thinks out loud" to reason past their working-memory limit. That is why CoT distillation collapses the apparent size-reasoning gap.
The critical success factor in CoT distillation is the quality and diversity of the reasoning traces, not the size of the dataset. Research consistently shows that 10K high-quality, verified reasoning traces outperform 100K unfiltered traces. Invest in building a pipeline that generates, verifies, and curates reasoning data from the teacher before scaling up the dataset size.
For knowledge distillation, use data from your target domain rather than generic pretraining data. A student model trained on 50K domain-specific examples from the teacher often outperforms one trained on 500K generic examples.
The success of distillation in creating small reasoning models (like DeepSeek-R1-Distill and Phi-4-mini) has demonstrated that chain-of-thought capabilities can transfer from large to small models more effectively than previously assumed. Research on progressive distillation applies multiple rounds of compression, gradually shrinking models while preserving capabilities at each stage.
An open frontier is distilling not just model outputs but internal representations and reasoning patterns, with techniques like feature distillation showing promise for preserving capabilities that output matching alone misses.
Objective
Implement knowledge distillation by training a small student model (DistilGPT-2) to mimic the output distribution of a larger teacher model (GPT-2 Medium), using KL divergence on soft targets with temperature scaling.
What You'll Practice
- Computing soft targets with temperature-scaled softmax
- Implementing the KL divergence distillation loss
- Balancing hard-label and soft-label loss components
- Comparing student performance before and after distillation
Setup
The following cell installs the required packages and configures the environment for this lab.
Steps
Step 1: Load teacher and student models
Load a larger teacher (frozen) and a smaller student (trainable).
# Load teacher (gpt2-medium, frozen) and student (gpt2, trainable).
# The student will learn to mimic the teacher's output distribution.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
teacher = AutoModelForCausalLM.from_pretrained("gpt2-medium").to(device)
teacher.eval()
for p in teacher.parameters():
p.requires_grad = False
student = AutoModelForCausalLM.from_pretrained("distilgpt2").to(device)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
t_params = sum(p.numel() for p in teacher.parameters())
s_params = sum(p.numel() for p in student.parameters())
print(f"Teacher: {t_params:,} params")
print(f"Student: {s_params:,} params")
print(f"Compression: {t_params / s_params:.1f}x")Hint
Both GPT-2 variants share the same tokenizer. The teacher must be frozen (eval mode, requires_grad=False) so only the student gets updated during training.
Step 2: Implement the distillation loss
Write the core loss that combines KL divergence on soft targets with cross-entropy on hard targets.
import torch
# Distillation loss: KL divergence on temperature-scaled soft targets
# blended with cross-entropy on hard (ground-truth) labels.
import torch.nn.functional as F
def distillation_loss(student_logits, teacher_logits, labels,
temperature=3.0, alpha=0.5):
"""Combined distillation loss with soft and hard targets."""
# TODO: Compute soft targets from teacher (temperature-scaled softmax)
# TODO: Compute soft predictions from student (temperature-scaled log-softmax)
# TODO: KL divergence between student and teacher distributions
# TODO: Standard cross-entropy on hard labels
# TODO: Combine: alpha * T^2 * KL + (1-alpha) * CE
pass
# Quick test
b, s, v = 2, 10, 50257
loss = distillation_loss(torch.randn(b,s,v), torch.randn(b,s,v),
torch.randint(0, v, (b,s)))
print(f"Test loss: {loss.item():.4f}")Test loss: 11.2438
Hint
Soft targets: F.softmax(teacher_logits / T, dim=-1). KL loss: F.kl_div(F.log_softmax(student_logits / T, dim=-1), soft_targets, reduction='batchmean'). Multiply KL by T² to keep gradients balanced across temperatures.
Step 3: Run the distillation training loop
Load text data and train the student to mimic the teacher's outputs.
import torch
# Training loop: forward both teacher and student on each batch,
# compute the combined distillation loss, and update student only.
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
dataset = dataset.filter(lambda x: len(x['text'].strip()) > 50)
def tokenize(examples):
return tokenizer(examples['text'], truncation=True,
max_length=128, padding='max_length')
tokenized = dataset.select(range(2000)).map(
tokenize, batched=True, remove_columns=['text'])
tokenized.set_format('torch')
loader = DataLoader(tokenized, batch_size=8, shuffle=True)
optimizer = torch.optim.AdamW(student.parameters(), lr=5e-5)
student.train()
for epoch in range(2):
total_loss = 0
for batch in tqdm(loader, desc=f"Epoch {epoch+1}"):
input_ids = batch['input_ids'].to(device)
attn = batch['attention_mask'].to(device)
student_out = student(input_ids, attention_mask=attn)
with torch.no_grad():
teacher_out = teacher(input_ids, attention_mask=attn)
loss = distillation_loss(
student_out.logits, teacher_out.logits, input_ids)
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item()
print(f"Epoch {epoch+1} avg loss: {total_loss / len(loader):.4f}")
Epoch 1: 100%|##########| 250/250 [01:42<00:00, 2.44it/s] Epoch 1 avg loss: 4.7261 Epoch 2: 100%|##########| 250/250 [01:38<00:00, 2.53it/s] Epoch 2 avg loss: 3.8934
Hint
The teacher forward pass is wrapped in torch.no_grad() since we never update its weights. If you run out of memory, reduce batch size to 4.
Step 4: Evaluate with perplexity
Compare perplexity for the original student, distilled student, and teacher.
from transformers import AutoModelForCausalLM
from torch.utils.data import DataLoader
from datasets import load_dataset
import torch
# Evaluate perplexity: compare original student, distilled student,
# and teacher to quantify how much knowledge transferred.
import math
def compute_perplexity(model, eval_loader):
model.eval()
total_loss, total_tokens = 0, 0
with torch.no_grad():
for batch in eval_loader:
ids = batch['input_ids'].to(device)
attn = batch['attention_mask'].to(device)
out = model(ids, attention_mask=attn, labels=ids)
total_loss += out.loss.item() * attn.sum().item()
total_tokens += attn.sum().item()
return math.exp(total_loss / total_tokens)
eval_data = load_dataset("wikitext", "wikitext-2-raw-v1", split="validation")
eval_data = eval_data.filter(lambda x: len(x['text'].strip()) > 50)
eval_tok = eval_data.select(range(500)).map(
tokenize, batched=True, remove_columns=['text'])
eval_tok.set_format('torch')
eval_loader = DataLoader(eval_tok, batch_size=8)
original = AutoModelForCausalLM.from_pretrained("distilgpt2").to(device)
print(f"Teacher PPL: {compute_perplexity(teacher, eval_loader):.2f}")
print(f"Original student PPL: {compute_perplexity(original, eval_loader):.2f}")
print(f"Distilled student PPL: {compute_perplexity(student, eval_loader):.2f}")
Teacher PPL: 24.87 Original student PPL: 46.13 Distilled student PPL: 36.41
Hint
Typical results: teacher ~25, original student ~45, distilled student ~35. The distilled student should show a 10 to 20% perplexity improvement while remaining 4x smaller than the teacher.
Expected Output
- Distilled student perplexity improves 10 to 20% over the original student
- The student remains ~4x smaller than the teacher
- Training loss should decrease steadily over 2 epochs
Stretch Goals
- Experiment with temperatures (T=1, 3, 5, 10) and plot how each affects the distilled student's perplexity
- Try different alpha values (0.3, 0.5, 0.7) and find the optimal balance
- Implement intermediate layer distillation: also match hidden states between teacher and student layers
Complete Solution
# Complete distillation lab: load teacher/student, train with KL
# divergence loss, evaluate perplexity before and after distillation.
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from torch.utils.data import DataLoader
import torch, torch.nn.functional as F, math
from tqdm import tqdm
device = "cuda" if torch.cuda.is_available() else "cpu"
teacher = AutoModelForCausalLM.from_pretrained("gpt2-medium").to(device)
teacher.eval()
for p in teacher.parameters(): p.requires_grad = False
student = AutoModelForCausalLM.from_pretrained("distilgpt2").to(device)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def distillation_loss(s_logits, t_logits, labels, T=3.0, alpha=0.5):
soft_t = F.softmax(t_logits / T, dim=-1)
soft_s = F.log_softmax(s_logits / T, dim=-1)
kl = F.kl_div(soft_s, soft_t, reduction='batchmean')
ce = F.cross_entropy(s_logits.view(-1, s_logits.size(-1)), labels.view(-1))
return alpha * (T**2) * kl + (1 - alpha) * ce
ds = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
ds = ds.filter(lambda x: len(x['text'].strip()) > 50)
def tok(ex): return tokenizer(ex['text'], truncation=True, max_length=128, padding='max_length')
train_tok = ds.select(range(2000)).map(tok, batched=True, remove_columns=['text'])
train_tok.set_format('torch')
loader = DataLoader(train_tok, batch_size=8, shuffle=True)
opt = torch.optim.AdamW(student.parameters(), lr=5e-5)
student.train()
for epoch in range(2):
total = 0
for batch in tqdm(loader, desc=f"Epoch {epoch+1}"):
ids, attn = batch['input_ids'].to(device), batch['attention_mask'].to(device)
s_out = student(ids, attention_mask=attn)
with torch.no_grad(): t_out = teacher(ids, attention_mask=attn)
loss = distillation_loss(s_out.logits, t_out.logits, ids)
loss.backward(); opt.step(); opt.zero_grad(); total += loss.item()
print(f"Epoch {epoch+1}: {total/len(loader):.4f}")
def ppl(model, dl):
model.eval(); tl, tt = 0, 0
with torch.no_grad():
for b in dl:
i, a = b['input_ids'].to(device), b['attention_mask'].to(device)
o = model(i, attention_mask=a, labels=i)
tl += o.loss.item()*a.sum().item(); tt += a.sum().item()
return math.exp(tl/tt)
ev = load_dataset("wikitext","wikitext-2-raw-v1",split="validation")
ev = ev.filter(lambda x: len(x['text'].strip())>50)
ev_t = ev.select(range(500)).map(tok, batched=True, remove_columns=['text'])
ev_t.set_format('torch')
el = DataLoader(ev_t, batch_size=8)
orig = AutoModelForCausalLM.from_pretrained("distilgpt2").to(device)
print(f"Teacher: {ppl(teacher,el):.2f}")
print(f"Original: {ppl(orig,el):.2f}")
print(f"Distilled: {ppl(student,el):.2f}")Epoch 1: 100%|##########| 250/250 [01:42<00:00, 2.44it/s] Epoch 1: 4.7261 Epoch 2: 100%|##########| 250/250 [01:38<00:00, 2.53it/s] Epoch 2: 3.8934 Teacher: 24.87 Original: 46.13 Distilled: 36.41
- Knowledge distillation trains small students to mimic large teachers, reducing inference cost by 10x or more while retaining most of the teacher's capability.
- Soft targets with temperature scaling provide richer training signal than hard labels by encoding the teacher's uncertainty and inter-class relationships.
- White-box distillation (logit access) produces better students than black-box (text-only), but black-box is the only option for API-based teachers.
- Distill the reasoning process, not just answers. Chain-of-Thought traces, explanations, and step-by-step solutions produce dramatically better students (as shown by Orca and DeepSeek-R1).
- Data quality trumps model size. The Phi series proved that small models trained on textbook-quality synthetic data can match models many times their size.
- Use higher LoRA ranks (32-64) for distillation than for standard fine-tuning, as the student needs more capacity to absorb the teacher's diverse behaviors.
- Speculative distillation optimizes serving speed by training a draft model to predict what the target model would generate, enabling parallel token verification.
Show Answer
Show Answer
Show Answer
Show Answer
Show Answer
Exercises
Explain the difference between hard labels and soft labels (logits) in knowledge distillation. Why do soft labels transfer more knowledge than hard labels?
Answer Sketch
Hard labels are one-hot vectors (e.g., [0, 0, 1, 0] for class 3). Soft labels are the teacher model's full probability distribution (e.g., [0.05, 0.10, 0.80, 0.05]). Soft labels convey inter-class relationships: a '7' that looks like a '1' gets a higher probability for '1' than for '8'. This dark knowledge teaches the student model about similarity structures that hard labels completely discard. The temperature parameter controls how much this dark knowledge is emphasized.
What is the role of the temperature parameter T in distillation? What happens at T=1, T=5, and T=20?
Answer Sketch
Temperature T softens the teacher's probability distribution: p_i = exp(z_i/T) / sum(exp(z_j/T)). At T=1: standard softmax, probabilities are peaked on the correct class. At T=5: distribution is smoother, revealing the teacher's uncertainty and inter-class similarity. At T=20: very flat distribution, nearly uniform, which may lose too much signal. Typical values: T=2 to T=5. Higher T transfers more dark knowledge but may dilute the primary signal. The student's loss is a weighted sum of distillation loss (soft targets) and standard cross-entropy (hard targets).
Write the key components of a distillation training loop: forward pass through teacher (no grad), forward pass through student, combined loss computation with temperature scaling.
Answer Sketch
Teacher: with torch.no_grad(): teacher_logits = teacher(input_ids).logits. Student: student_logits = student(input_ids).logits. Soft loss: soft_loss = F.kl_div(F.log_softmax(student_logits/T, dim=-1), F.softmax(teacher_logits/T, dim=-1), reduction='batchmean') * T*T. Hard loss: hard_loss = F.cross_entropy(student_logits, labels). Combined: loss = alpha * soft_loss + (1-alpha) * hard_loss. Typical alpha=0.5, T=3.
Compare on-policy distillation (student generates, teacher scores) with off-policy distillation (teacher generates, student learns). When does each approach produce better results?
Answer Sketch
Off-policy: the teacher generates responses that the student learns to imitate via SFT. Simple to implement but the student only sees the teacher's distribution, not its own mistakes. On-policy: the student generates responses, the teacher provides token-level or sequence-level feedback, and the student learns from its own errors. On-policy is more compute-intensive but typically produces stronger students because the training data matches the student's own distribution. On-policy is preferred for larger distribution gaps between teacher and student.
You want to distill a 70B teacher into a smaller student. Compare distilling into a 7B model (same architecture, fewer layers) versus a 3B model (different architecture). What factors determine the choice?
Answer Sketch
Consider: (1) Target inference budget: 3B is ~2.3x faster and uses ~2.3x less memory than 7B. (2) Quality ceiling: 7B retains more of the teacher's capability (larger models are better students). (3) Task complexity: simple tasks (classification, extraction) work with 3B; complex reasoning benefits from 7B. (4) Architecture compatibility: same-architecture distillation can use layer-by-layer matching losses in addition to output-level distillation. Choose 7B for quality-critical tasks, 3B for cost/latency-critical deployment.
What's Next?
In the next section, Section 17.7: Adapter Methods and Modular Fine-Tuning, we return to parameter-efficient methods, this time focusing on adapter layers and how multiple adapters can compose into a modular, task-routed model.
For the reasoning-model architectures (o1, o3, R1, QwQ) whose chain-of-thought is the dominant 2024-26 distillation target, see Section 8.2: Reasoning Model Architectures. For the synthetic-reasoning-data generation pipelines that feed reasoning distillation, see Section 15.6: Synthetic Reasoning Data. For the post-distillation evaluation suite (faithfulness, refusal calibration, contamination checks), see Section 42.1: LLM Evaluation Fundamentals.